| 云计算技术 实验五 Hbase的安装和基础编程 | 您所在的位置:网站首页 › 云计算的总结和体会 › 云计算技术 实验五 Hbase的安装和基础编程 |
云计算技术 实验五 Hbase的安装和基础编程
|
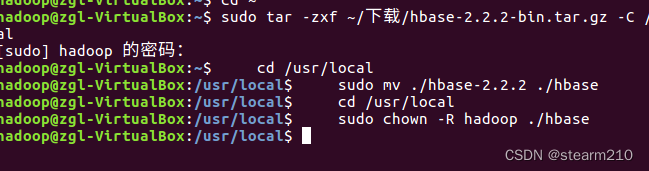
参考资料为: 教材代码-林子雨编著《大数据基础编程、实验和案例教程(第2版)》教材所有章节代码_厦大数据库实验室博客 1.实验学时 4学时 2.实验目的 熟悉Hbase的安装和配置。熟悉Hbase的相关命令。实现Hbase的Java编程调用。3.实验内容 (一)安装Hbase,能够查询Hbase的版本。 首先将压缩包传入linux中进行压缩:
后面把文件名改了,将hbash目录的权限赋值给hadoop用户: 然后在hbash路径下修改文件,配置环境变量: 先改变路径到hbash文件夹:
然后vim编译文件,加入路径名字:
然后使修改立刻生效:
然后添加用户权限: 将HBase安装目录下的所有文件所有者改成hadoop
然后查看版本号:
安装成功。 (二)单机运行Hbase系统。 先配置环境:(单机环境) 先配置java环境变量: 使用命令进入hbse-env.sh文件(vim进入):路径为/usr/local/hbase/conf/hbase-env.sh
找到这两行修改:
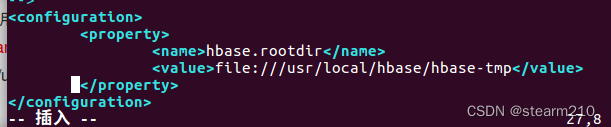
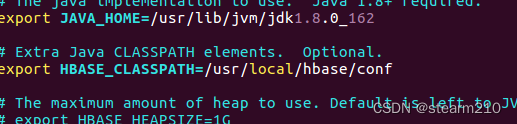
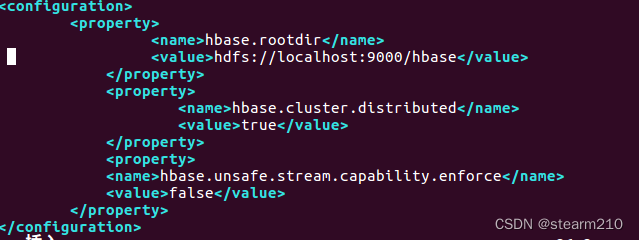
修改成: export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_162 export HBASE_MANAGES_ZK=true 然后修改hbase-site.xml,使用下面指令进入文件。 vim /usr/local/hbase/conf/hbase-site.xml 添加配置:
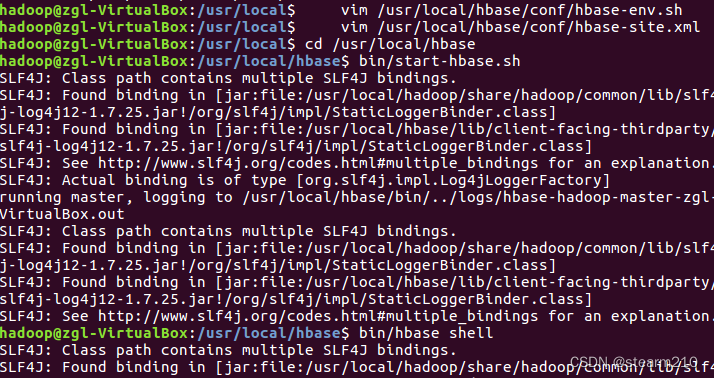
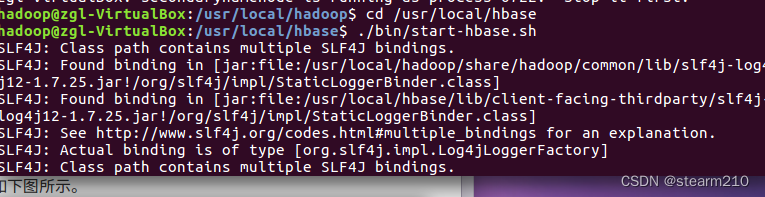
然后测试运行hbase 先打开目录,然后再启动Hbase
启动成功:
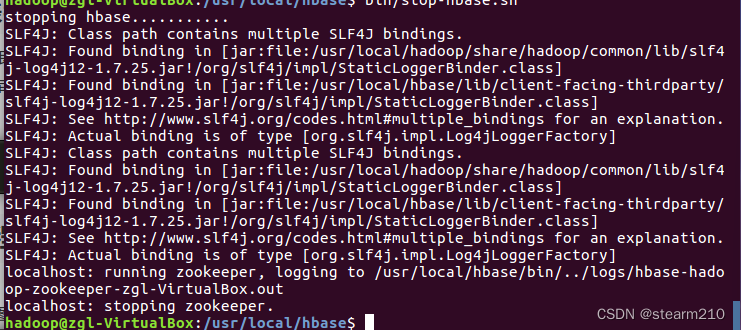
然后可以停止运行hBase:
(三)实现Hbase的伪分布式启动。 进入要修改的文件
先配置hbase-env.sh文件,修改路径
然后再配置hbase-site.xml
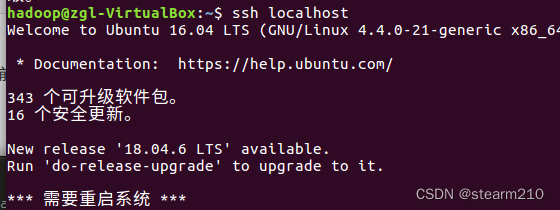
然后启动hbase : 先登录ssh
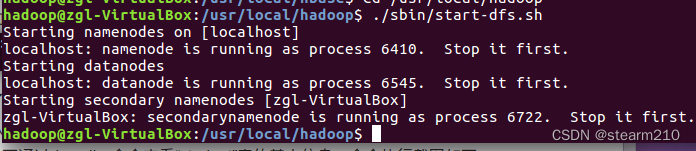
然后启动hadoop :
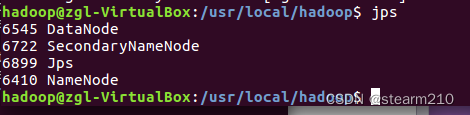
输入jps命令,然后发现进程namenode、secondarynamenode、datanode都启动了
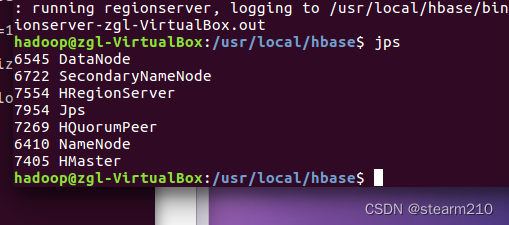
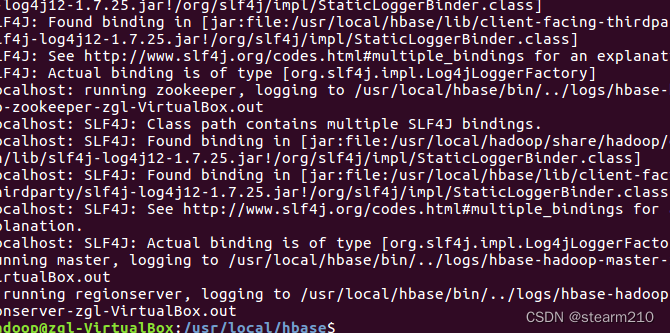
切换目录之后再启动hbase 出现以下进程说明启动成功:
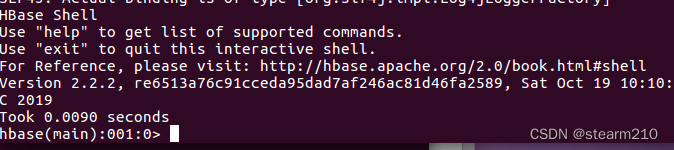
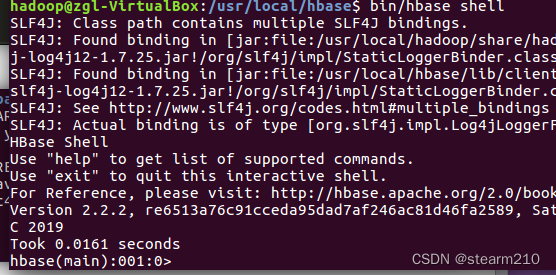
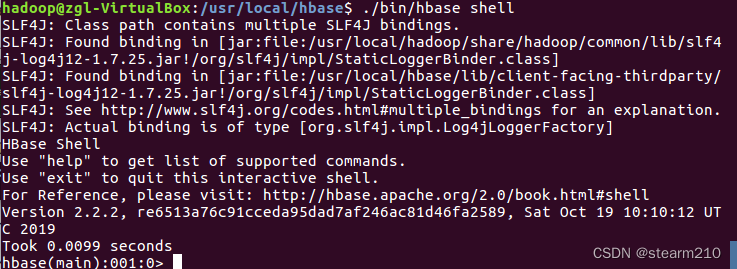
进入hbase 的shell命令,
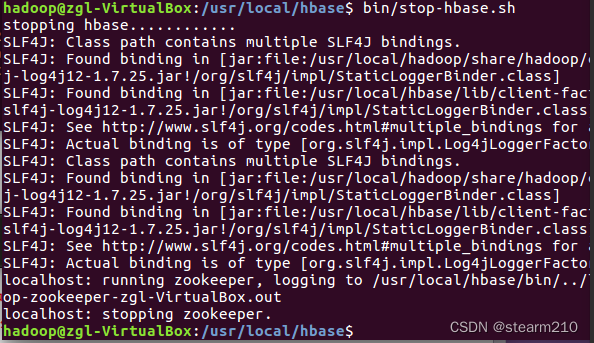
然后关闭hbase :
(四)运行Hbase相关的Shell命令,实现表的创建,数据插入,数据删除,以及数据查看等操作。 先启动hadoop:
然后启动hbase:
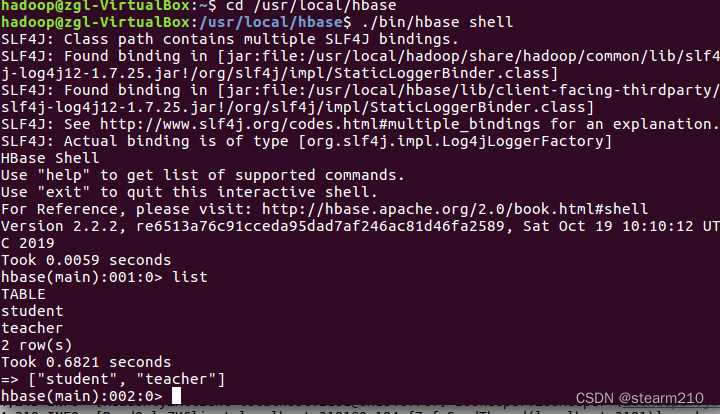
然后进入hbase的shell命令
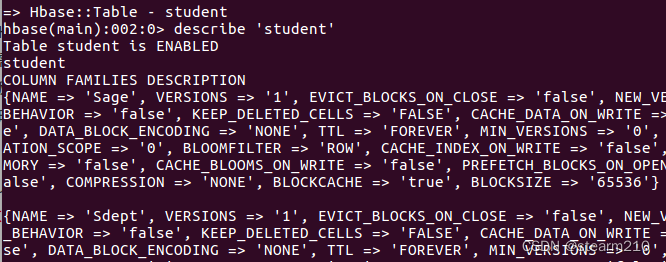
1.创建表:
然后可以查看建完的表的信息:
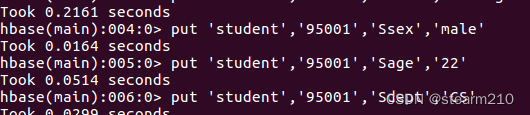
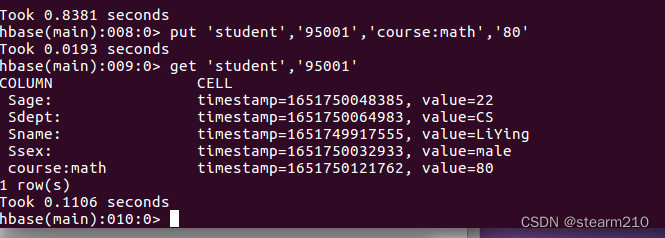
2.然后是添加数据
3.添加多组数据
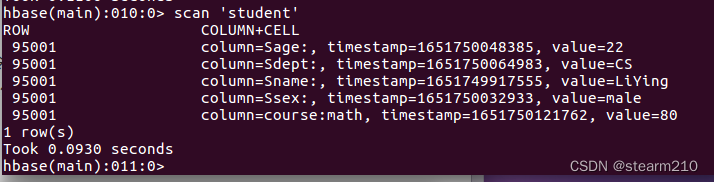
4.查看数据,这里返回95001行的数据; 这里使用get命令
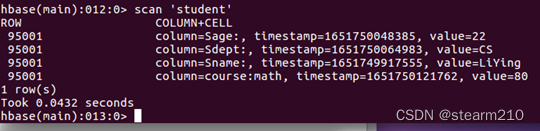
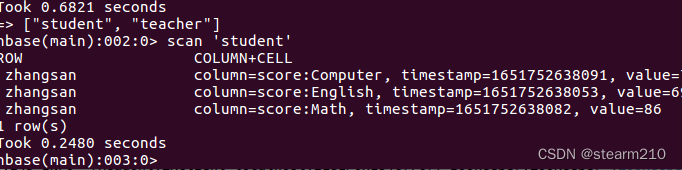
使用scan命令
5.删除数据:
已经删除了这个信息:
删除全部信息:
6.然后是删除表的操作: 先让表不可使用
删除student表
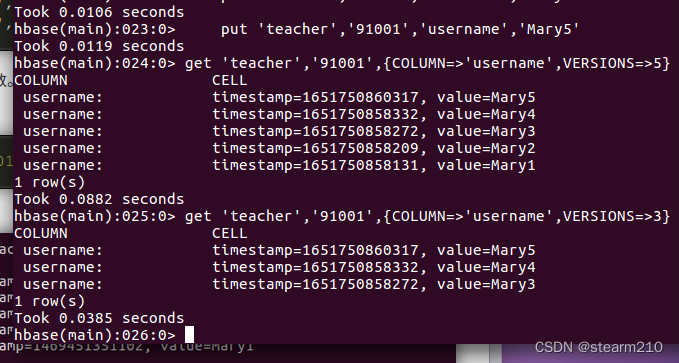
7.查询历史信息: 先建立一个teacher表保存信息
插入数据后更新数据: 然后指定查询信息:
退出数据库,完成操作。
(五)实现Hbase的Java编程,在eclipse中创建项目,ExampleForHbase。java代码。 先启动hadoop,然后启动hbase
然后启动eclipse:
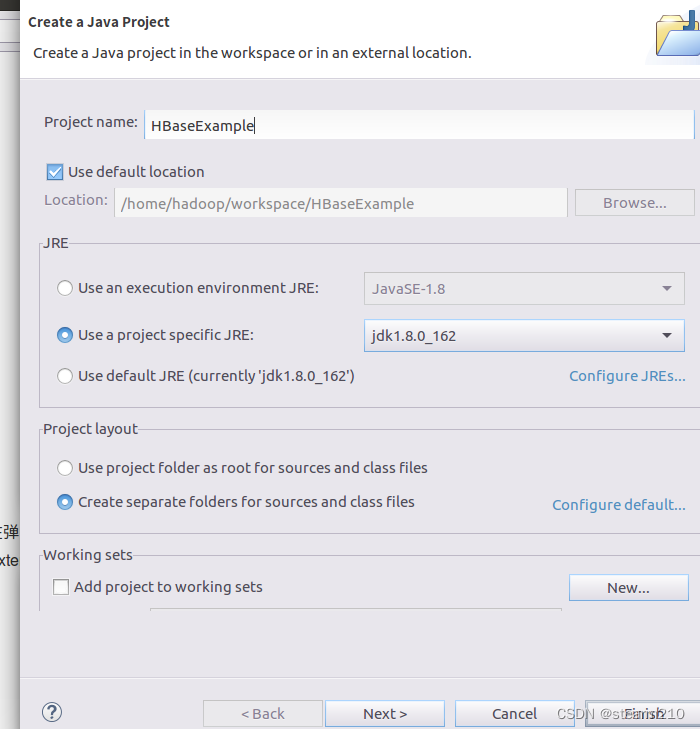
创建新的项目:
然后next之后在下一个界面点击libraries,之后选择add external jars 然后在usr/local/hbase/lib目录下选择要导入的jar包
然后进入最上面的目录导入剩下的jar包
完成之后点击finsh 之后右键新创建的hbaseexmaple创建一个新的class
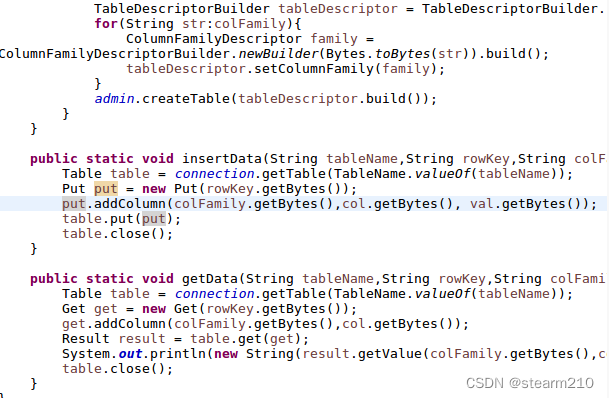
然后输入代码:下面为java代码 import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.*; import org.apache.hadoop.hbase.client.*; import org.apache.hadoop.hbase.util.Bytes; import java.io.IOException; public class ExampleForHBase { public static Configuration configuration; public static Connection connection; public static Admin admin; public static void main(String[] args)throws IOException{ init(); createTable("student",new String[]{"score"}); insertData("student","zhangsan","score","English","69"); insertData("student","zhangsan","score","Math","86"); insertData("student","zhangsan","score","Computer","77"); getData("student", "zhangsan", "score","English"); close(); } public static void init(){ configuration = HBaseConfiguration.create(); configuration.set("hbase.rootdir","hdfs://localhost:9000/hbase"); try{ connection = ConnectionFactory.createConnection(configuration); admin = connection.getAdmin(); }catch (IOException e){ e.printStackTrace(); } } public static void close(){ try{ if(admin != null){ admin.close(); } if(null != connection){ connection.close(); } }catch (IOException e){ e.printStackTrace(); } } public static void createTable(String myTableName,String[] colFamily) throws IOException { TableName tableName = TableName.valueOf(myTableName); if(admin.tableExists(tableName)){ System.out.println("talbe is exists!"); }else { TableDescriptorBuilder tableDescriptor = TableDescriptorBuilder.newBuilder(tableName); for(String str:colFamily){ ColumnFamilyDescriptor family = ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes(str)).build(); tableDescriptor.setColumnFamily(family); } admin.createTable(tableDescriptor.build()); } } public static void insertData(String tableName,String rowKey,String colFamily,String col,String val) throws IOException { Table table = connection.getTable(TableName.valueOf(tableName)); Put put = new Put(rowKey.getBytes()); put.addColumn(colFamily.getBytes(),col.getBytes(), val.getBytes()); table.put(put); table.close(); } public static void getData(String tableName,String rowKey,String colFamily, String col)throws IOException{ Table table = connection.getTable(TableName.valueOf(tableName)); Get get = new Get(rowKey.getBytes()); get.addColumn(colFamily.getBytes(),col.getBytes()); Result result = table.get(get); System.out.println(new String(result.getValue(colFamily.getBytes(),col==null?null:col.getBytes()))); table.close(); } }
然后运行代码:
程序运行成功:
在新的终端中启动hbase的shell命令之后查看list
发现有student的表 然后再查看student表中的数据
完成编译。 4.思考题 (一)Hbase和传统的关系型数据库相比,有哪些特点? 1.Hbase的容量十分大,它里面的表可以存储很多行和列组成的数据。 2.Hbase的版本十分的多,它表中的每一个列的数据都有多个版本,一般来说,每一个列对应着一条数据,可能有的数据会对应着多个版本。每个版本对应的查看相对方便。 3.Hbase中的表中的列可以是空的,对于空列,它不会占用空间,对于表的设计可以相对随意。 4.对于Hbase当存储空间不够的时候,由于Hbase底层使用HDFS,可以动态增加机器解决空间问题。 5.Hbase的可靠性更高,由于底层使用HDFS,所以HDFS具有备份的机制,当Spark集群发生严重的问题的时候,Hbase中的机制可以保证数据不会发生丢失或者损毁。 (二)Hbase创建的应用程序,需要导入哪些安装包,这些安装包里面有什么功能? 1.在单机配置的时候,需要导入java的jdk文件,用于后面调用eclipse进行java项目的编写,配置hbase-env.sh文件还需要加上对应的路径。 2.在使用eclipse的时候,导入的jar包用于实现java项目的编写,对应的有向Hbase中输入数据的jar包,连接Hbase数据库的包,使用shell命令的包等。 3.在配置伪分布式模式的时候,需要设置好对应的访问路径用于使用hadoop等,这些访问路径对应的包是已经安装好的。 5.实验结论或体会 1.在添加用户权限的时候,需要注意对应的文件夹不要配置错误权限。 2.在Hbase中使用Shell命令的时候,需要注意退出之后,要重新使用对应的进入命令才能继续使用Shell命令操作Hbase。 3.退出数据库的时候,需要注意路径的问题可能导致退出失败。 4.在操作eclipse的时候,导入jar包的时候,对应的包需要全部导入,路径不要错了。 5.操作eclipse之前,一定要运行hadoop和Hbase之后,运行代码才会有结果,对应的Hbase中才会出现数据。 |
















【本文地址】