| #今天介绍2种Python绘制词云的手法(wordcloud和stylecloud),你会偷偷pick谁呢? | 您所在的位置:网站首页 › 云图标准库 › #今天介绍2种Python绘制词云的手法(wordcloud和stylecloud),你会偷偷pick谁呢? |
#今天介绍2种Python绘制词云的手法(wordcloud和stylecloud),你会偷偷pick谁呢?
|
文章目录
1. wordcloud词云绘制1.1. 简单的例子1.2. 中文词云制作1.3. 自定义词云蒙版图1.4. 词频信息数据词云绘制1.5. 更多参数设置说明
2. stylecloud词云绘制2.1. 简单的例子2.2. 自带的配色方案2.3. 自带的蒙版方案2.4. 如何自定义蒙版图2.5. 更多参数设置说明
大家好,今天才哥带大家了解下他常用的两种绘制词云图的方法,也许有你想要的哦。
最近有粉丝同学在演示此前案例时发现在制作词云的时候有报错,希望才哥能讲解一下Python词云的绘制,那么今天他来了。 我这边之前一直是用的jieba+wordcloud,后来看到有朋友在用基于wordcloud的更高颜值的stylecloud,于是最近开始使用jieba+stylecloud了。 1. wordcloud词云绘制 先安装相关库(如果已有则可无视) pip install numpy pip install pillow pip install matplotlibwordcloud依赖于numpy and pillow,同时如果要预览或保存生成的词云图,matplotlib也是必须的。 再安装worlcloud pip install wordcloud更多详情大家可以去github了解: https://github.com/amueller/word_cloud/ 1.1. 简单的例子由于英文句子每个单词之间都会由空格或标点符号分开,不需要做额外的分词处理,因此对于英文文本来说,直接可用。 from wordcloud import WordCloud # 词云 文本来源 text text = "apple Banana Blueberry Cherry Grape Peach Cherry Cherry Grape" wc = WordCloud() wc.generate(text) # 存为本地图片 wc.to_file("example.png") # matplotlib用于显示 词云图 import matplotlib.pyplot as plt plt.imshow(wc) plt.axis("off") # plt方式存为本地图片 # plt.savefig('词云例子.png') plt.show()
由于中文博大精深,一段文本是有句子组成的,句子之间才有标点符号分开。而句子则是由单字或词组无缝连接而成,所以我们需要对文本进行分词处理。 这里用到的分词库是 jieba(https://github.com/fxsjy/jieba),思路上就是先用jieba进行分词,然后再调用worldcloud即可。 import jieba import jieba.analyse import matplotlib.pyplot as plt from wordcloud import WordCloud # 我们以刘德华的《今天》歌词为例 text = """走过岁月我才发现世界多不完美 成功或失败都有一些错觉 沧海有多广 江湖有多深 局中人才了解 生命开始情不情愿总要过完一生 交出一片心不怕被你误解 谁没受过伤 谁没流过泪 何必要躲在黑暗里 自苦又自怜 我不断失望 不断希望 苦自己尝 笑与你分享 如今站在台上也难免心慌 如果要飞得高 就该把地平线忘掉 等了好久终于等到今天 梦了好久终于把梦实现 前途漫漫任我闯 幸亏还有你在身旁 盼了好久终于盼到今天 忍了好久终于把梦实现 那些不变的风霜早就无所谓 累也不说累""" # jieba分词(精确模式) text_after_split = jieba.cut(str(text), cut_all=False) words = ' '.join(text_after_split) # 词云参数设置 wc = WordCloud( background_color='white', # 词云图背景颜色,默认为白色 font_path='FZZJ-YGYTKJW.TTF', # 词云图 字体(中文需要设定为本机有的中文字体) ) wc.generate(words) # matplotlib用于显示 词云图 plt.imshow(wc) plt.axis("off") plt.show()
注意:关于作图的中文字体设置,大家可以参考《》 1.3. 自定义词云蒙版图我们经常看到别的做的词云的文字覆盖区域刚好可以组成特定的图形,如苹果主题的以苹果为形状等等。 wordcloud提供参数mask用于我们进行自定义背景区域,由于mask接受的是nd-array类型参数,因此这里我们需要用先打开我们要用到的蒙版图,然后转化为nd-array。 关于蒙版图设置需要注意:除全白(#FFFFFF)的部分将不会绘制,其余部分会用于绘制词云 import numpy as np from PIL import Image # 就下面代码,即可获取满足类型要求的参数 bg=np.array(Image.open("蒙版图.png")) mask=bg我们以 刘德华 形象为蒙版图,接1.2节内容,用《今天》歌词绘制词云如下: wc = WordCloud(width=500, # 词云图宽 height=500, # 词云图高 mask = mask, # 词云蒙版图 background_color='white', # 词云图背景颜色,默认为白色 font_path='FZZJ-YGYTKJW.TTF', # 词云图 字体(中文需要设定为本机有的中文字体) max_font_size=400, # 最大字体,默认为200 random_state=50, # 为每个单词返回一个PIL颜色 ) wc.generate(words) # matplotlib用于显示 词云图 import matplotlib.pyplot as plt plt.imshow(wc) plt.axis("off") # plt方式存为本地图片 # plt.savefig('词云例子.png') plt.show()
有时候我们可能在手上的 数据信息是 带有词频信息的数据,这种情况下也是可以用wordcloud的generate_from_frequencies方法进行处理的,它接受一个包含词频信息数据的字典参数,比如下面这个例子: import matplotlib.pyplot as plt from wordcloud import WordCloud # 词云参数设置 wc = WordCloud( background_color='white', # 词云图背景颜色,默认为黑色 font_path='FZZJ-YGYTKJW.TTF', # 词云图 字体(中文需要设定为本机有的中文字体) ) # 词频信息数据,用字典形式传给 generate_from_frequencies frequencies = { '才哥':18, '水哥':16, '航哥':10, '梦泪':11, '牛头':5, '孙悟空': 12, '诸葛亮':18, '马超':7, '刘备':12, '黄忠':5, '鲁班8号':1, } wc.generate_from_frequencies(frequencies) # 根据词频信息数据做词云图 # matplotlib用于显示 词云图 plt.imshow(wc) plt.axis("off") plt.show()
另外,在进行词云绘制时,还有很多别的参数大家可以自行摸索,让你的词云图更加有个性。 wordcloud.WordCloud(font_path=None, width=400, height=200, margin=2, ranks_only=None, prefer_horizontal=0.9, mask=None, scale=1, color_func=None, max_words=200, min_font_size=4, stopwords=None, random_state=None, background_color='black', max_font_size=None, font_step=1, mode='RGB', relative_scaling='auto', regexp=None, collocations=True, colormap=None, normalize_plurals=True, contour_width=0, contour_color='black', repeat=False, include_numbers=False, min_word_length=0, collocation_threshold=30)参数说明: 在以下参数中,停用词stopwords是我们用的较多的,比如我们对于某些词不希望参与到词云制作中,则可以将其添加到停用词中。 font_path : string #字体路径,需要展现什么字体就把该字体路径+后缀名写上,如:font_path = '黑体.ttf' width : int (default=400) #输出的画布宽度,默认为400像素 height : int (default=200) #输出的画布高度,默认为200像素 prefer_horizontal : float (default=0.90) #词语水平方向排版出现的频率 mask : nd-array or None (default=None) #如果参数为空,则使用二维遮罩绘制词云。 scale : float (default=1) #按照比例进行放大画布,如设置为1.5,则长和宽都是原来画布的1.5倍 min_font_size : int (default=4) #显示的最小的字体大小 font_step : int (default=1) #字体步长,如果步长大于1,会加快运算但是可能导致结果出现较大的误差 max_words : number (default=200) #要显示的词的最大个数 stopwords : set of strings or None #设置需要屏蔽的词,如果为空,则使用内置的STOPWORDS background_color : color value (default=”black”) #背景颜色,如background_color='white' max_font_size : int or None (default=None) #显示的最大的字体大小 mode : string (default=”RGB”) #当参数为“RGBA”并且background_color不为空时,背景为透明 relative_scaling : float (default=.5) #词频和字体大小的关联性 color_func : callable, default=None #生成新颜色的函数,如果为空,则使用 self.color_func regexp : string or None (optional) #使用正则表达式分隔输入的文本 collocations : bool, default=True #是否包括两个词的搭配 colormap : string or matplotlib colormap, default=”viridis” #给每个单词随机分配颜色,若指定color_func,则忽略该方法 random_state : int or None #为每个单词返回一个PIL颜色 2. stylecloud词云绘制stylecloud 是一位数据科学家叫Max Woolf的大神做出来的wordcloud词云包的升级版,它让词云看起来更美观了。 其核心主要在 配色方案 和 蒙版方案 上,其配色方案是让词云图更美观优雅的点,只能使用其提供的蒙版方案上我觉得反而让自由空间变小了,所以今天我们会介绍如何自定义蒙版! 先安装stylecloud库 pip install stylecloud更多详情可以前往github了解: https://github.com/minimaxir/stylecloud 2.1. 简单的例子由于stylecloud是基于wordcloud库的,关于其他诸如中文分词的操作这里就不再赘述了。 先看个简单的列子吧: import stylecloud from PIL import Image # 词云 文本来源 text text = "apple Banana Blueberry Cherry Grape Peach Cherry Cherry Grape AAA BBB CCC DDD EE FFFF" stylecloud.gen_stylecloud(text=text) # 默认会存一张名为stylecloud的png词云图 # 打开预览 词云图 Image.open("stylecloud.png")
stylecloud配色方案是使用的高级调色板palettable来实现了,所以我们看起来很舒服吧。 大家可以去它的设计网站了解详情: https://jiffyclub.github.io/palettable/ 调色板们
我们选择某个如palettable.tableau,在页面可见其效果预览:
通过设置参数palette为指定配色方案,我们即可完成配色。比如我们拿palettable.tableau里的BlueRed_6,那么只需要加上参数palette='tableau.BlueRed_6'即可。 import stylecloud from PIL import Image text = "apple Banana Blueberry Cherry Grape Peach Cherry Cherry Grape AAA BBB CCC DDD EE FFFF" stylecloud.gen_stylecloud( text=text, palette='tableau.BlueRed_6', # 设置配色方案 ) Image.open("stylecloud.png")
stylecloud蒙版方案是使用的Font Awesome里现成的icon来实现了,由于这里有海量的图标,大家总能找到自己想要的吧。 大家可以去它的网站了解详情: https://fontawesome.dashgame.com/ 在stylecloud有一个fontawesome.min.css文件包含了巨量的图标,你可以定期到官方网站获取最新的图标库来更新。
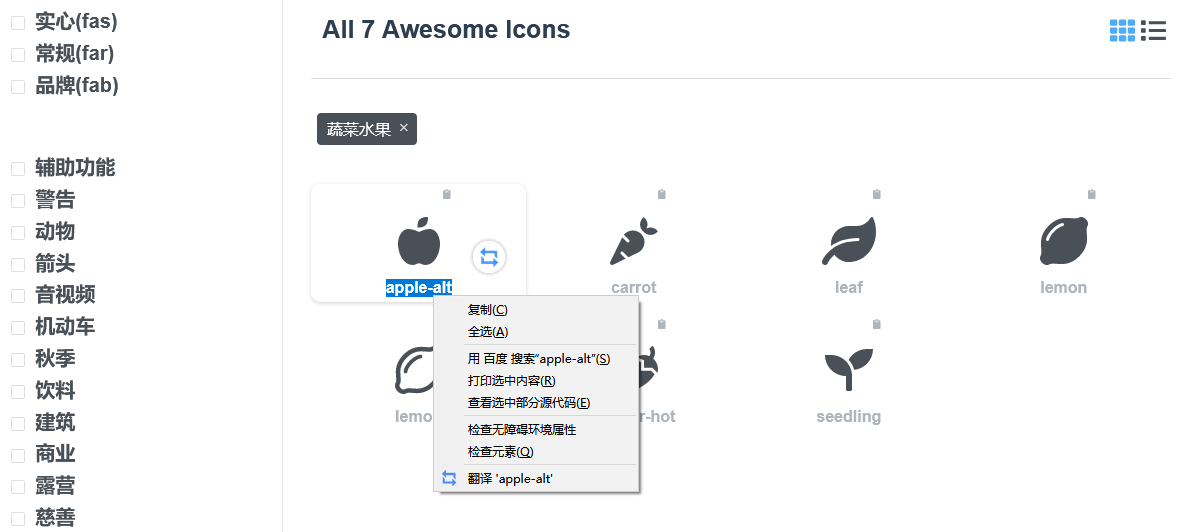
大家还可以去以下两个地址搜索你想要的蒙版图标(icon)名称,然后复制图标名称如蔬菜水果中的苹果图标名称apple-alt。 https://fa5.dashgame.com/#/%E5%9B%BE%E6%A0%87https://fontawesome.com/icons?d=gallery
通过设置参数icon_name为指定蒙版图标,我们即可完成设置蒙版。比如我们拿apple-alt为例,那么只需要加上参数icon_name='fas fa-apple-alt'即可。 import stylecloud from PIL import Image text = "apple Banana Blueberry Cherry Grape Peach Cherry Cherry Grape AAA BBB CCC DDD EE FFFF" stylecloud.gen_stylecloud( text=text, palette='tableau.BlueRed_6', # 设置配色方案 icon_name='fas fa-apple-alt', # 设置蒙版方案 ) Image.open("stylecloud.png")
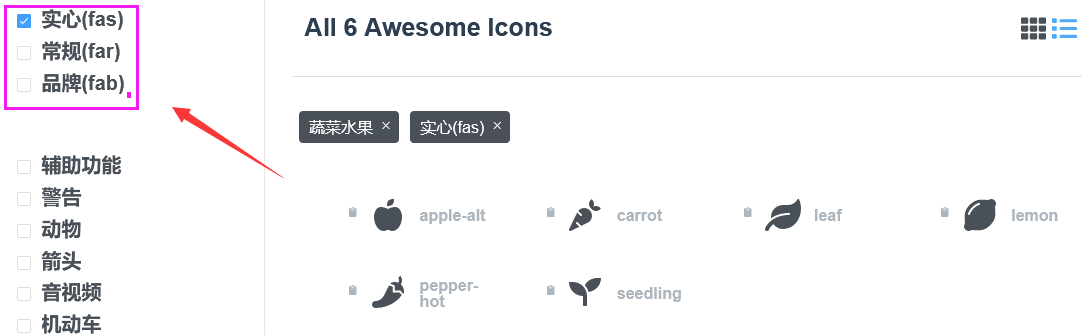
注意: 需要关注的是图标前缀存在三种:fas(实心)、far(常规)和fab(品牌)。大家在设置的时候一定要注意,比如我搜索apple-alt就是实心fas,大家在网站上是可以找到分类的。
通过上面的例子,我们发现stylecloud提供的蒙版功能只能选择它所固有的,如果我想自定义设置任意的蒙版效果,该如何下手呢? 既然 是基于 wordcloud词云库,而且我们已经熟知了wordcloud如何自定义词云蒙版的,那么我们打开 stylecloud库的文件一探究竟! 文件路径
直接查看 词云图绘制部分代码,找到核心 代码块,也就是调用wordcloud的部分。 def gen_stylecloud( text: str = None, file_path: str = None, size: int = 512, icon_name: str = "fas fa-flag", palette: str = "cartocolors.qualitative.Bold_5", colors: Union[str, List[str]] = None, background_color: str = "white", max_font_size: int = 200, max_words: int = 2000, stopwords: bool = True, custom_stopwords: Union[List[str], set] = STOPWORDS, add_stopwords: bool = False, icon_dir: str = ".temp", output_name: str = "stylecloud.png", gradient: str = None, font_path: str = os.path.join(STATIC_PATH, "Staatliches-Regular.ttf"), random_state: int = None, collocations: bool = True, invert_mask: bool = False, pro_icon_path: str = None, pro_css_path: str = None, ): #... wc = WordCloud( background_color=background_color, font_path=font_path, max_words=max_words, mask=mask_array, # 快看,这个是 蒙版设置参数 stopwords=custom_stopwords if stopwords else None, max_font_size=max_font_size, random_state=random_state, collocations=collocations, #... ) 代码分析及重构分析以上代码,我们发现 蒙版设置参数 mask 传递的是 mask_array 的值,具体不需要知道这个值怎么来的,我们要做的是如何 传递自定义的蒙版背景nd-array值。 为了兼容 他原本的 逻辑,这里我的思路是 : gen_stylecloud()新增一个参数bg,其默认赋值为空字符串; 当bg为空字符串的时候 参数 mask 传递的是 mask_array 的值; 当bg为我们赋的nd-array值时,参数 mask 传递的是 bg 的值。 基于上述思路,我们简单重构代码如下: def gen_stylecloud( *原有参数不变 bg: str='', # 新增自定义蒙版参数 ): #... wc = WordCloud( background_color=background_color, font_path=font_path, max_words=max_words, mask=mask_array if len(bg)==0 else bg, # 快看,这个是 蒙版设置参数 stopwords=custom_stopwords if stopwords else None, max_font_size=max_font_size, random_state=random_state, collocations=collocations, #... ) 效果演示同样以刘德华的《今天》歌词为例: import stylecloud from PIL import Image import jieba import jieba.analyse text = """走过岁月我才发现世界多不完美 成功或失败都有一些错觉 沧海有多广 江湖有多深 局中人才了解 生命开始情不情愿总要过完一生 交出一片心不怕被你误解 谁没受过伤 谁没流过泪 何必要躲在黑暗里 自苦又自怜 我不断失望 不断希望 苦自己尝 笑与你分享 如今站在台上也难免心慌 如果要飞得高 就该把地平线忘掉 等了好久终于等到今天 梦了好久终于把梦实现 前途漫漫任我闯 幸亏还有你在身旁 盼了好久终于盼到今天 忍了好久终于把梦实现 那些不变的风霜早就无所谓 累也不说累""" # jieba分词(精确模式) text_after_split = jieba.cut(str(text), cut_all=False) words = ' '.join(text_after_split) # 就下面代码,即可获取满足类型要求的参数 bg=np.array(Image.open("背景图.png")) stylecloud.gen_stylecloud( text=words, palette='tableau.BlueRed_6', # 设置配色方案 # icon_name='fas fa-apple-alt', bg = bg, # 刘德华 照片为蒙版啦 font_path='FZZJ-YGYTKJW.TTF', # 词云图 字体(中文需要设定为本机有的中文字体) ) Image.open("stylecloud.png")
其他如背景色、词云图大小、停用词参数等等,大家自行摸索吧! text: str = None, # 输入文本,最好在直接调用函数时使用 file_path: str = None, # 输入文本的文件路径 size: int = 512, # 词云图长宽大小 icon_name: str = "fas fa-flag", #stylecloud 形状的图标名称 palette: str = "cartocolors.qualitative.Bold_5", # 配色方案 colors: Union[str, List[str]] = None, background_color: str = "white", # 控制词云图底色,可传入颜色名称或16进制色彩 max_font_size: int = 200, # stylecloud 中的最大字号 max_words: int = 2000,# stylecloud 可包含的最大单词数 stopwords: bool = True, # 布尔值,用于筛除常见禁用词 custom_stopwords: Union[List[str], set] = STOPWORDS, # 传入自定义的停用词List add_stopwords: bool = False, icon_dir: str = ".temp", output_name: str = "stylecloud.png", # stylecloud 的输出文本名 gradient: str = None, # 梯度方向 font_path: str = os.path.join(STATIC_PATH, "Staatliches-Regular.ttf"), # stylecloud 所用字体,若要正确显示中文字符,需要指定中文字体 random_state: int = None, # 控制单词和颜色的随机状态 collocations: bool = True, invert_mask: bool = False, pro_icon_path: str = None, pro_css_path: str = None, |











【本文地址】