| Python 爬虫对链家网广州二手房源信息的处理与可视化分析 | 您所在的位置:网站首页 › 二手房地图可视化 › Python 爬虫对链家网广州二手房源信息的处理与可视化分析 |
Python 爬虫对链家网广州二手房源信息的处理与可视化分析
|
使用Jupyter对链家网广州二手房源信息数据处理
简介一、数据文件二、数据处理三、数据可视化分析四、聚类算法
简介
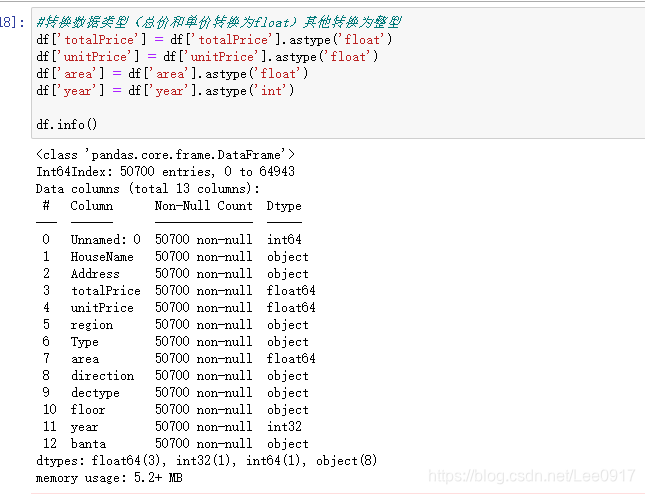
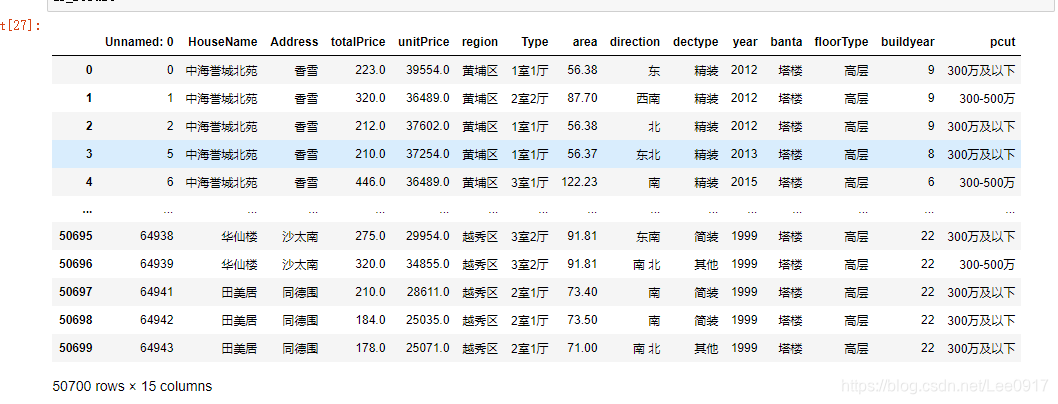
通过上一篇文章的爬取介绍,Python 使用Jupyter爬取链家网广州二手房源信息,这篇文章写一下关于数据处理的操作方法,对于数据处理的问题总结。 一、数据文件将我之前爬取的数据文件放在这个链接中,毕竟爬取时间太长,有需要的小伙伴自取,并进行处理操作尝试。 链接:https://pan.baidu.com/s/1-ds7T5GNiamxawbx2tmUkw 提取码:78zf 二、数据处理2022.02.23更新 导入python所需要的库,之前忘记加上了,有些小伙伴找不到一些库。 from pyecharts.globals import CurrentConfig, OnlineHostType import numpy as np import pandas as pd import matplotlib.pyplot as plt #pandas自带的图形包 import os from pyecharts.charts import Pie, Map, Bar, Line, Grid, Page, Funnel, Geo #插件可以绘制很酷炫的图形 from pyecharts import options as opts from pyecharts.globals import ThemeType, ChartType, GeoType import xlwt, xlrd import csv # matplotlib可以正常显示汉字 import matplotlib.pyplot as plt plt.rcParams['font.sans-serif'] = ['Arial Unicode MS'] # 用来正常显示中文标签 plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号通过导入的数据对房源信息进行数据处理,对houseInfo列的分割处理,首先将其中的车位信息剔除,然后对houseInfo列中的厅室、房屋大小、朝向、装修程度、楼层、年份、板塔进行处理分割,并将其保存到一个新的csv文件中,方便进行数据分析。 # 导入写入的广州二手房数据 df = pd.read_csv(r'./广州二手房源信息.csv') #加入区,方便后面数据处理 df['region'] = df.region + "区" #对houseInfo进行数据处理 df.houseInfo #查询有多少车位信息 df[df['houseInfo'].str.split('|').str[0].str.strip() == '车位'] #去除爬取到的车位的数据 df = df.drop(index=(df.loc[(df['houseInfo'].str.split('|').str[0].str.strip() == '车位')].index))
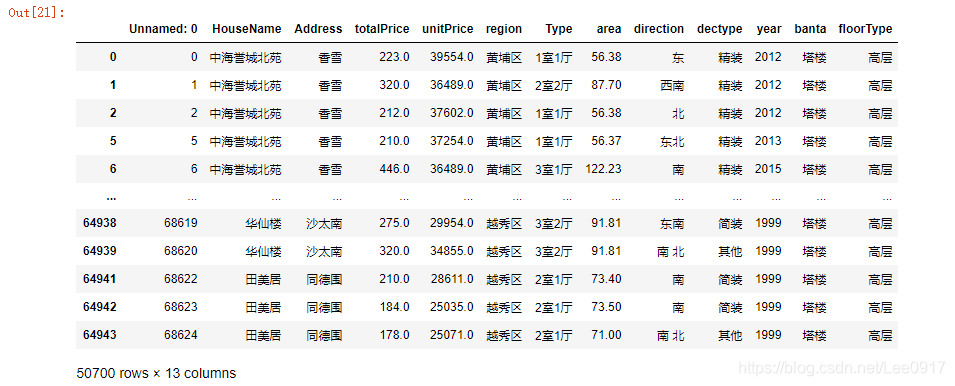
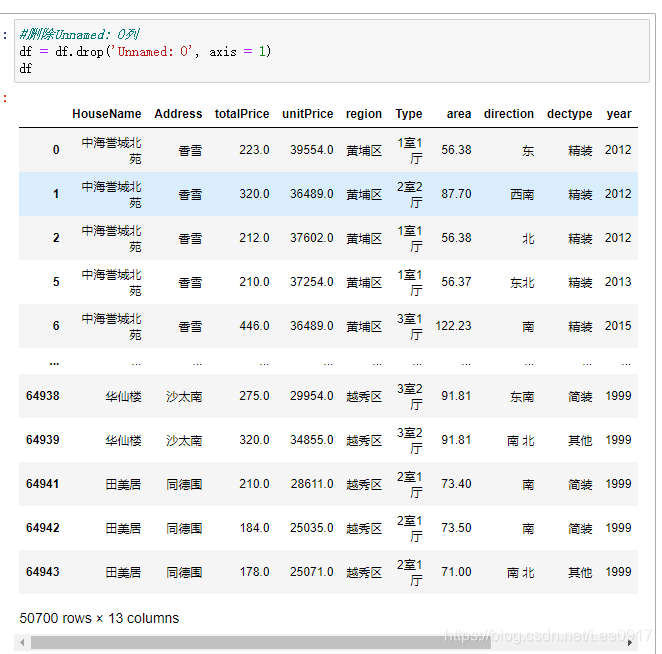
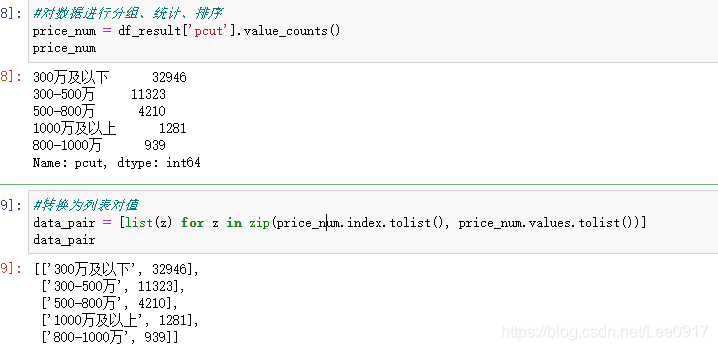
这里我又将数据保存一份成xlsx格式,用于后面数据分析时,将房子地点转化为经纬度。 #将信息保存成xlsx格式,方便数据处理,整理小区经纬度。 outputpath='./广州二手房数据清洗结果.xlsx' df.to_excel(outputpath,index=False, header=False)以上就是对数据处理的基本步骤了,接下来是对清洗后的数据进行可视化分析。 三、数据可视化分析通过对处理后的数据进行可视化分析,来确定广州二手房价格的区间,地段等等。 #打开数据 df_result = pd.read_csv(r'./广州二手房数据清洗结果.csv') #设置分割点 bins = [0, 300, 500, 800, 1000, 10000] bins_label = ['300万及以下', '300-500万', '500-800万', '800-1000万', '1000万及以上'] #插入新列 df_result['pcut'] = pd.cut(df_result.totalPrice, bins, right = False, labels = bins_label) df_result
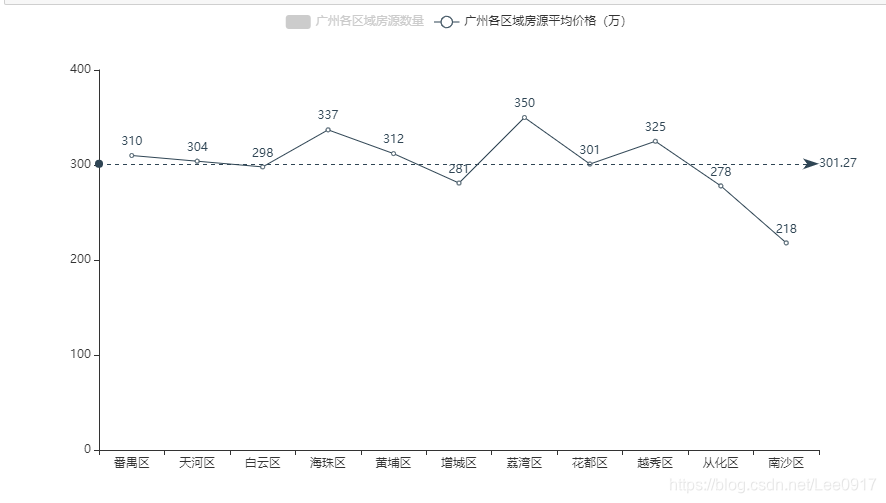
接下来求出每个区域的平均房价,然后对比房源数量和平均房价的关系。 #求出各个区域的房价总和 panyu_num = df[df['region'] == '番禺区']['totalPrice'].sum() tianhe_num = df[df['region'] == '天河区']['totalPrice'].sum() baiyun_num = df[df['region'] == '白云区']['totalPrice'].sum() haizhu_num = df[df['region'] == '海珠区']['totalPrice'].sum() huangpu_num = df[df['region'] == '黄埔区']['totalPrice'].sum() zengcheng_num = df[df['region'] == '增城区']['totalPrice'].sum() liwan_num = df[df['region'] == '荔湾区']['totalPrice'].sum() huadu_num = df[df['region'] == '花都区']['totalPrice'].sum() yuexiu_num = df[df['region'] == '越秀区']['totalPrice'].sum() conghua_num = df[df['region'] == '从化区']['totalPrice'].sum() nansha_num = df[df['region'] == '南沙区']['totalPrice'].sum() #求出各地区房价平均值 panyu_avg = int(panyu_num / region_num['番禺区']) tianhe_avg = int(tianhe_num / region_num['天河区']) baiyun_avg = int(baiyun_num / region_num['白云区']) haizhu_avg = int(haizhu_num / region_num['海珠区']) huangpu_avg = int(huangpu_num / region_num['黄埔区']) zengcheng_avg = int(zengcheng_num / region_num['增城区']) liwan_avg = int(liwan_num / region_num['荔湾区']) huadu_avg = int(huadu_num / region_num['花都区']) yuexiu_avg = int(yuexiu_num / region_num['越秀区']) conghua_avg = int(conghua_num / region_num['从化区']) nansha_avg = int(nansha_num / region_num['南沙区']) #查看区域房源和平均房价关系 x = region_num.index.tolist() a = region_num.values.tolist() b = [panyu_avg, tianhe_avg, baiyun_avg, haizhu_avg, huangpu_avg, zengcheng_avg, liwan_avg, huadu_avg, yuexiu_avg, conghua_avg, nansha_avg] bar = (Bar() .add_xaxis(x) .add_yaxis('广州各区域房源数量', a)) line = (Line(init_opts=opts.InitOpts(theme = ThemeType.SHINE)) .add_xaxis(x) .add_yaxis('广州各区域房源平均价格(万)', b, markline_opts=opts.MarkLineOpts(data = [opts.MarkLineItem(type_="average")])) .set_global_opts(title_opts=opts.TitleOpts(title="广州二手房区域平均价格情况",subtitle="测试"))) bar.overlap(line) bar.render_notebook()
或者直接使用转换好的经纬度文件: 链接:https://pan.baidu.com/s/1f2gE-WKXaSspgXiTEvXd3w 提取码:z5ws #载入整理的房源经纬度 data_house = pd.read_excel(r'./output.xlsx') #统计每个小区有多少房源 data_house_num = data_house['house_area'].value_counts() data_house_num #转化为列表形式 data_house_pair = [list(z) for z in zip(data_house_num.index.tolist(), data_house_num.values.tolist())] data_house_pair通过统计每个小区多少套房源,可以方便后续在代码中地图标注点位的时候提高代码的执行性,提高代码运行效率。
通过导入数据清洗后的房源数据,编写一个聚类算法。 df = pd.read_csv(r'./广州二手房数据清洗结果.csv') def plot_scatter(): plt.figure(figsize=(10,8),dpi=256) colors = ['red', 'red', 'red', 'red', 'blue', 'blue', 'blue', 'blue', 'green', 'green', 'green'] addr_dist = ['番禺区','天河区','白云区','海珠区', '黄埔区','增城区','荔湾区','花都区', '越秀区', '从化区','南沙区'] markers = ['o','s','v','x', 'o', 's', 'v', 'x', 'o', 's', 'v'] # print(addr_dist) for i in range(11): x = df.loc[df['region'] == addr_dist[i]]['area'] y = df.loc[df['region'] == addr_dist[i]]['unitPrice'] plt.scatter(x, y, c=colors[i], s=20, label=addr_dist[i], marker=markers[i]) plt.legend(loc=1,bbox_to_anchor=(1.138,1.0),fontsize=12) plt.xlim(0,500) plt.ylim(0,200000) plt.title('广州各区二手房面积对房价的影响',fontsize=20) plt.xlabel('房屋面积(平方米)',fontsize=16) plt.ylabel('房屋单价(元/平方米)',fontsize=16) plot_scatter()
以上就是所有通过对二手房源爬取后的数据信息处理。还有很多处理后的数据没用到,有学习的朋友可以尝试对楼龄等数据进行可视化分析,确定二手房售卖与楼龄关系等。希望能给大家一点帮助,互相学习进步,希望大佬指点改进优化的地方。 |
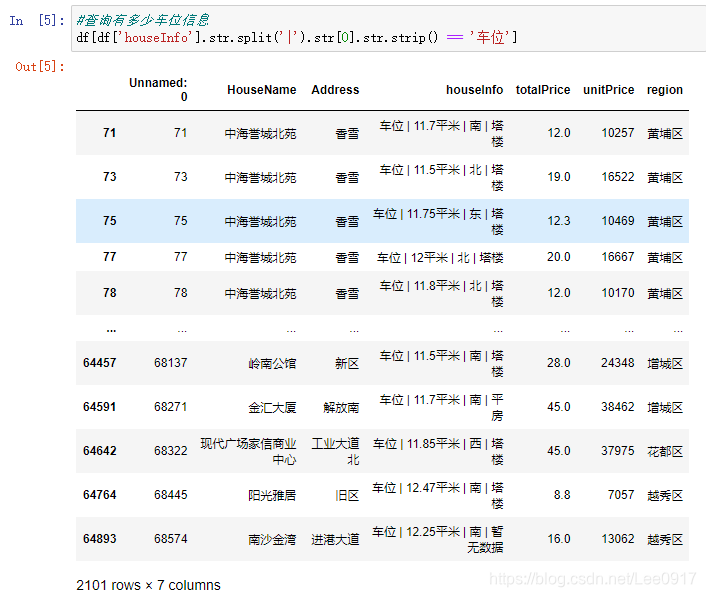
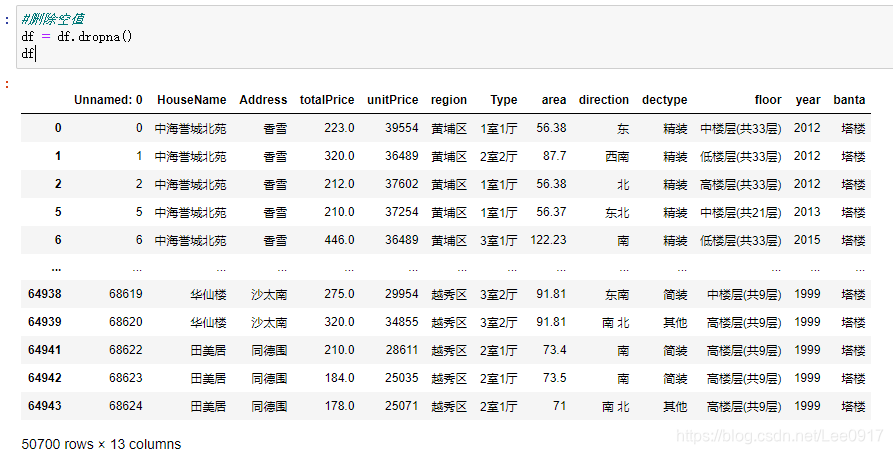
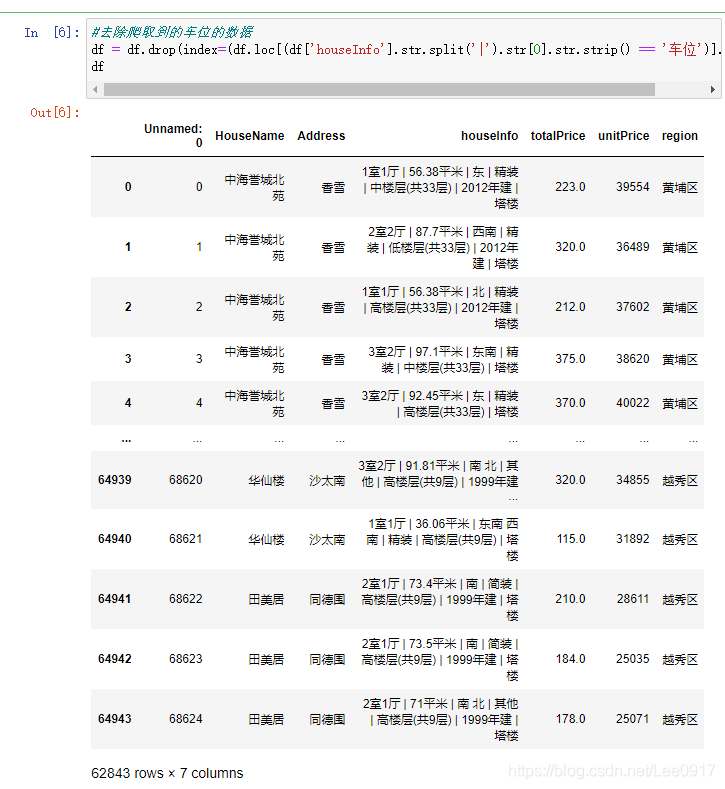 剩余62843条二手房信息,接下来对houseInfo列进行分割操作。
剩余62843条二手房信息,接下来对houseInfo列进行分割操作。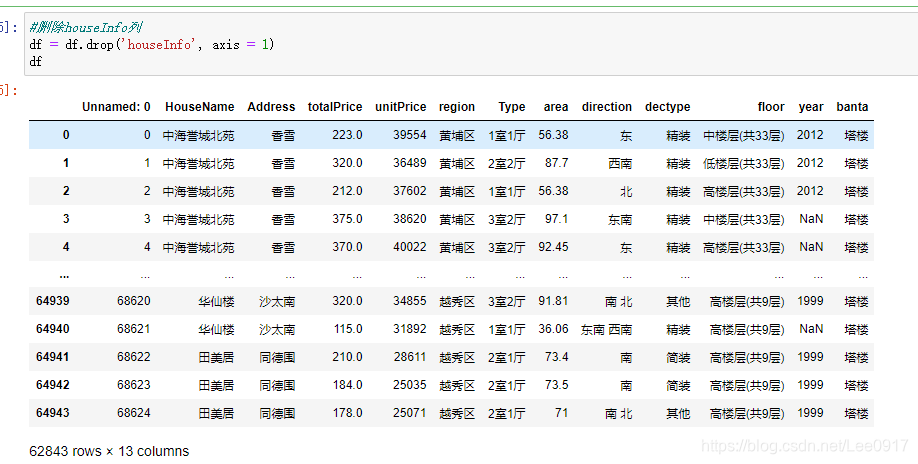 将houseInfo列处理完之后,还要对其中的数据进行处理,查看空值并去除。
将houseInfo列处理完之后,还要对其中的数据进行处理,查看空值并去除。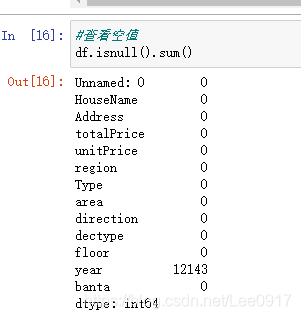
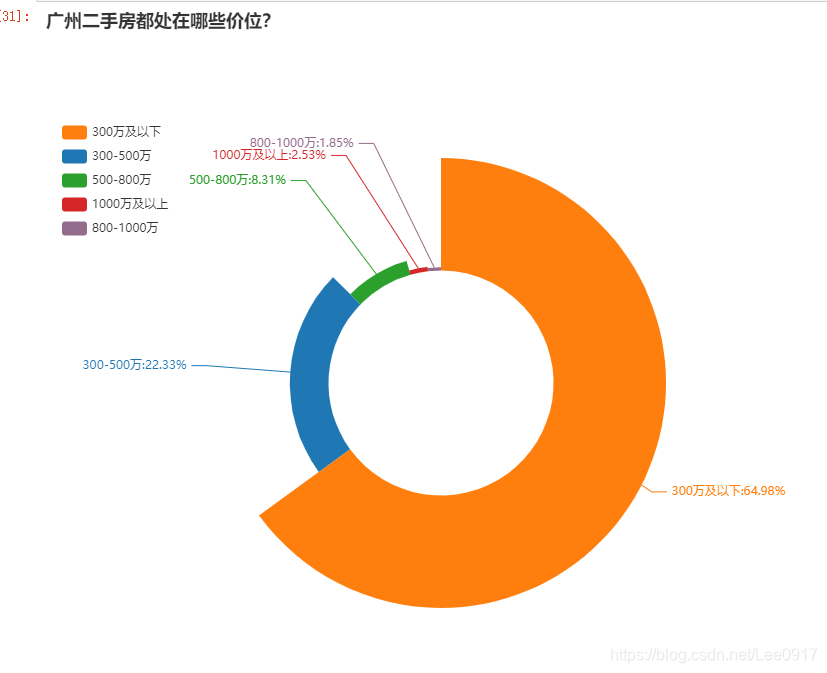 通过上图可以得知广州二手房源的多在300万以下,可以通过饼图很直观的看到价格分布情况。
通过上图可以得知广州二手房源的多在300万以下,可以通过饼图很直观的看到价格分布情况。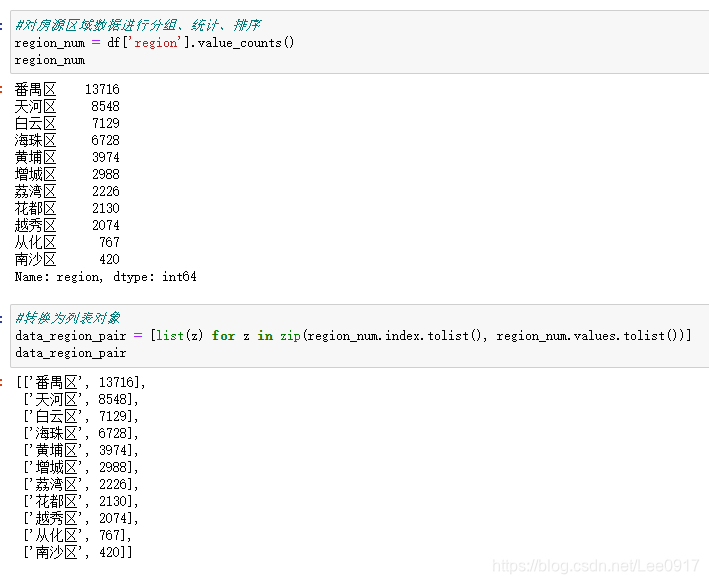
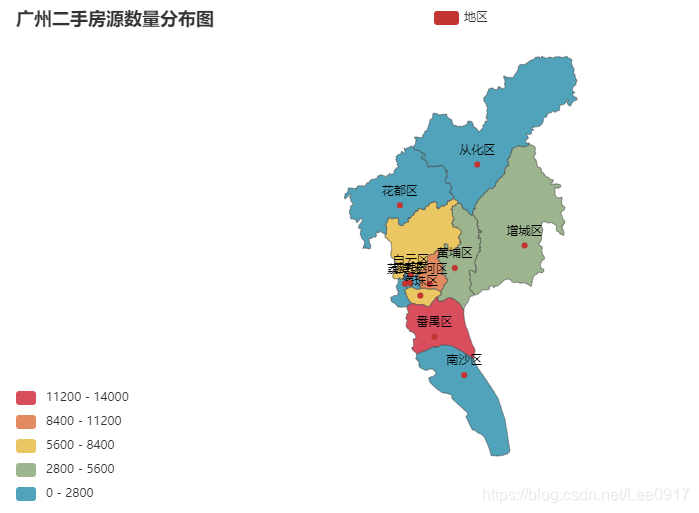
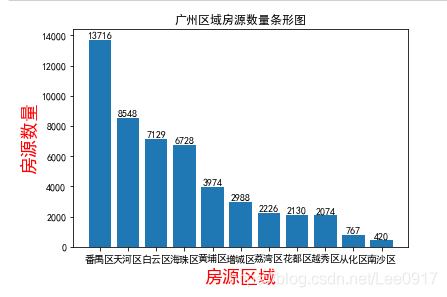 通过此图可以很直观的看出广州二手房分布区域。方便做数据统计。
通过此图可以很直观的看出广州二手房分布区域。方便做数据统计。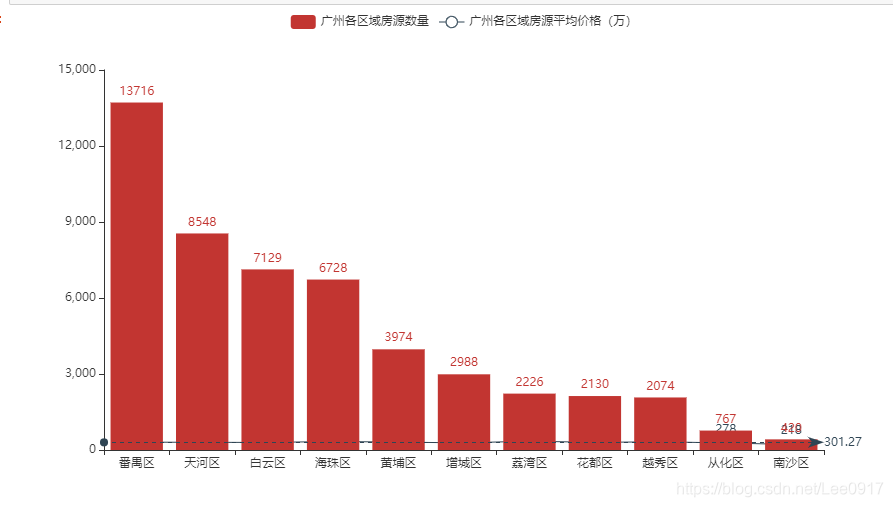
 接下来通过经纬度的整理,然后把房源的地址通过经纬度表达,就可以得到各个小区在广州的具体位置。
接下来通过经纬度的整理,然后把房源的地址通过经纬度表达,就可以得到各个小区在广州的具体位置。 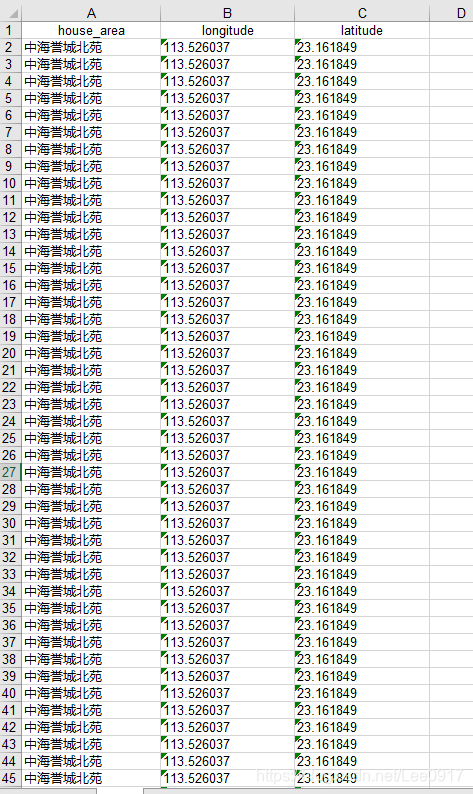 转换后的部分数据 附上经纬度转换工具(需要的小伙伴自取):
转换后的部分数据 附上经纬度转换工具(需要的小伙伴自取):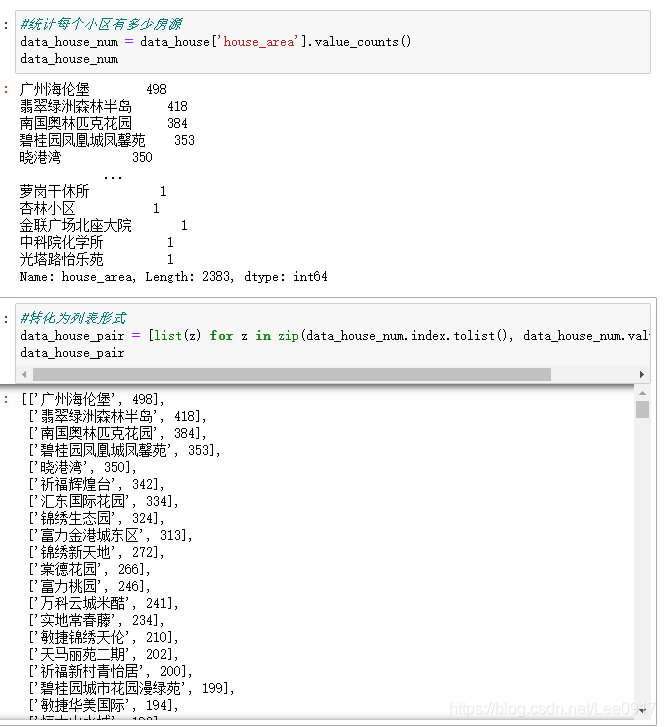 然后将导入的数据进行处理,去重重复的值,再新增一列,就能得知每个小区的经纬度及其在售二手房套数。这个地方虽然看着不难写,但却是花费了我部分时间在如何存放小区房源数量上。还是挺有意思的写法,也爬了许多帖子优化了许多算法才勉强写出。
然后将导入的数据进行处理,去重重复的值,再新增一列,就能得知每个小区的经纬度及其在售二手房套数。这个地方虽然看着不难写,但却是花费了我部分时间在如何存放小区房源数量上。还是挺有意思的写法,也爬了许多帖子优化了许多算法才勉强写出。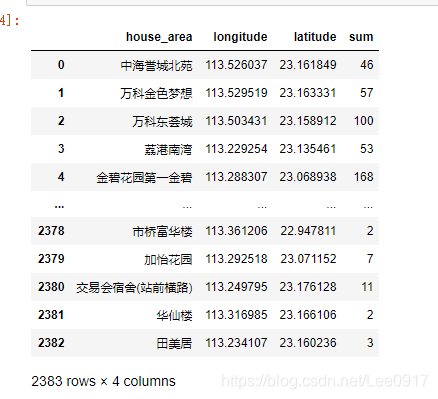 最后将显示广州小区分布图,加载所有数据会让浏览器出现卡顿变慢的现象,通过修改其中的值可以查看不同的小区。
最后将显示广州小区分布图,加载所有数据会让浏览器出现卡顿变慢的现象,通过修改其中的值可以查看不同的小区。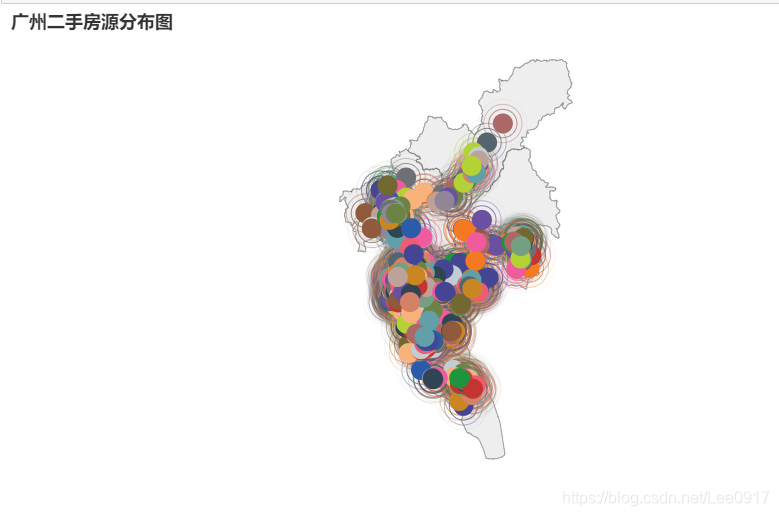 这样可以看到每个小区的地理位置分布图,这里有几个问题,当我将geo.add(’’,data_pair, type_=GeoType.EFFECT_SCATTER, symbol_size=20) # 可尝试把’'里面内容替换成data_house[‘house_area’][i] 进行替换之后,原本想象的效果图是像图一这样规规整整,行数过多能把地图按序往下推,结果成了图二,爬了许多帖子不知道如何进行修改,不得已将其设置为空,希望有大佬能帮忙指出问题所在。
这样可以看到每个小区的地理位置分布图,这里有几个问题,当我将geo.add(’’,data_pair, type_=GeoType.EFFECT_SCATTER, symbol_size=20) # 可尝试把’'里面内容替换成data_house[‘house_area’][i] 进行替换之后,原本想象的效果图是像图一这样规规整整,行数过多能把地图按序往下推,结果成了图二,爬了许多帖子不知道如何进行修改,不得已将其设置为空,希望有大佬能帮忙指出问题所在。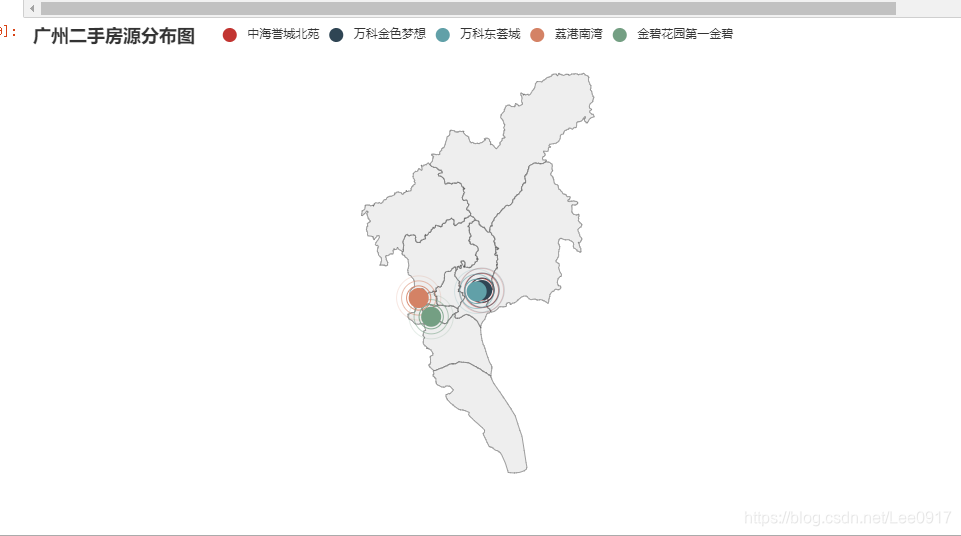
 同时还想求助问一下如何让地图显示成和百度高德地图那样可以覆盖个底层地图上去,并且显示出地铁线路,方便查看房源是否靠近地铁线路。
同时还想求助问一下如何让地图显示成和百度高德地图那样可以覆盖个底层地图上去,并且显示出地铁线路,方便查看房源是否靠近地铁线路。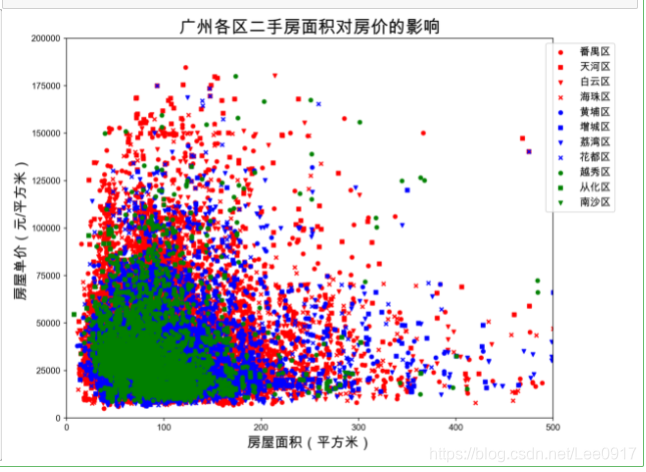
【本文地址】