| python爬取作文 | 您所在的位置:网站首页 › 九九作文网作文网 › python爬取作文 |
python爬取作文
|
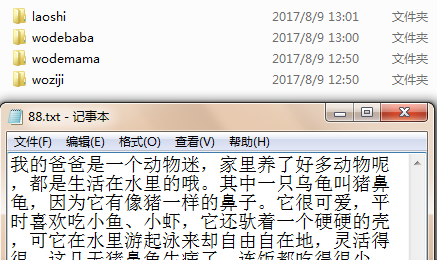
为了练习做文本处理,爬取了99作文网中的作文。beautifulsoup的学习文档http://beautifulsoup.readthedocs.io/zh_CN/latest/。 from bs4 import BeautifulSoup import requests import os #获取文章列表 def Articlelist(url,suffix,articlelist): urll = url+suffix res = requests.get(urll) res.encoding = 'utf-8' soup = BeautifulSoup(res.text, 'html.parser') urllist = soup.select('.xubg a[href$="html"]') for i in urllist: articlelist.append(i['href']) nextpage = soup.find('a',text='下一页') if nextpage: #下一页 return Articlelist(url,nextpage['href'],articlelist) return articlelist #获得每个文章内容并写入新文件 def content(articlelist,path): n = 0 for i,url in enumerate(articlelist): res = requests.get(url) res.encoding = 'utf-8' soup = BeautifulSoup(res.text, 'html.parser') content = ''.join(i.text for i in soup.select('.content p') ) if len(content)==0: content = ''.join(i.text for i in soup.select('.content br')) #如果文档为空则不写入 if len(content)!=0: name = path + '\\'+str(n) + '.txt' n = n+1 f = open(name,'w',encoding='utf-8') f.write(content) f.close() #主函数 def main(url): for i in range(len(url)): articlelist = [] suffix = '' articlelist = Articlelist(url[i],suffix,articlelist) path = 'E:\作文\\' + url[i].split('/')[-2] os.makedirs(path) content(articlelist,path) url= ['http://www.99zuowen.com/xiaoxuezuowen/wodebaba/','http://www.99zuowen.com/xiaoxuezuowen/laoshi/'] main(url)总共爬了老师,爸爸,妈妈,自己四种作文,爬出如图所示:
|
【本文地址】
公司简介
联系我们
| 今日新闻 |
| 推荐新闻 |
| 专题文章 |