| 上交提出:更好的语言模型预训练需要更好的Masking | 您所在的位置:网站首页 › 为什么标点符号很重要 › 上交提出:更好的语言模型预训练需要更好的Masking |
上交提出:更好的语言模型预训练需要更好的Masking
 一句话总结 一句话总结BERT当初暴利随机masking 15%的机制肯定是有问题的,比如应该着重masking那些实词,而少关注标点符号等虚词;另外从前到后的15%比例也有很大的改进空间。上交就是根据上面的问题提出了两种time-variant(随时间变化) masking方式,分别为Masking Ratio Decay (MRD)和POS-Tagging Weighted (PTW) Masking,并取得了相当好的效果。 关注zenRRan,可以快速了解到最新优质的NLP前沿技术和相关论文~ 点击进入——>微信NLP技术交流群 论文: Learning Better Masking for Better Language Model Pre-training 地址: https://arxiv.org/pdf/2208.10806v2.pdf单位: 上海交通大学摘要掩蔽语言模型 (MLM) 已被广泛用作预训练语言模型 (PrLM) 中的去噪目标。 现有的 PrLMs 通常采用 Random-Token Masking 策略,其中应用固定的掩蔽率,并且在整个训练过程中以相等的概率掩蔽不同的内容。 然而,模型可能会受到预训练状态的复杂影响,随着训练时间的推移,预训练状态会相应地发生变化。  实词和虚词的不同masking 实词和虚词的不同masking在本文中,我们表明这种时变 MLM 设置对屏蔽率和屏蔽内容不太可能提供最佳结果,这促使我们探索时变 MLM 设置的影响。  不同ratios在SQuAD v1.1上的表现 不同ratios在SQuAD v1.1上的表现我们提出了两种预定的掩码方法,可以在不同的训练阶段自适应地调整掩码率和掩码内容,从而提高预训练效率和在下游任务上验证的有效性。 我们的工作是关于比率和内容的时变掩蔽策略的开创性研究,可以更好地理解掩蔽率和掩蔽内容如何影响 MLM 预训练。  两种不同的decay 两种不同的decay  不同类型word的损失累计。实线为实词,虚线为虚词。 不同类型word的损失累计。实线为实词,虚线为虚词。 不同类型word的权重变化一些问题解释masking ratio:为什么时变掩蔽比不是最佳选择? 不同类型word的权重变化一些问题解释masking ratio:为什么时变掩蔽比不是最佳选择?从实验结果来看,有这样一个经验规律:一开始,高masking ratio的downstream performance起点较高,但增长速度相对较慢,赶上了masking ratio为的模型15%。 也就是说,masking ratio为15%的模型起点较低,但后期性能提升较快。 鉴于这一观察,我们表明我们可以应用相对较高的掩蔽率来训练模型,以使用更少的时间获得更好的模型。 另一方面,我们将较低的掩蔽率应用于训练模型,如果我们训练足够的时间,则可以获得更好的下游性能。但是如果我们使用衰减的masking ratio而不是固定的masking ratio,我们可以吸收高masking ratio和低masking ratio的优点。 Masked Content:为什么Random-Token Masking不是最优的?对于一个句子,实词和虚词的数量非常相似。 因此,对于 Random-Token Masking,模型同样重视从这两种词中学习。 然而,图中的实验结果表明,语言模型耗散了它对一些功能词建模的努力,这些功能词的损失非常低。同时,Random-Token Masking 让模型不太可能学习那些本应学习更多的非功能词,这肯定会产生次优的预训练结果。 模型 Masking Ratio Decay (MRD)很简单就不多做解释了,但是POS-Tagging Weighted (PTW) Masking方法估计大家对细节会有疑惑,所以还是看下面的论文解释吧:   实验分析 实验分析 Masking Ratio Decay实验对比 Masking Ratio Decay实验对比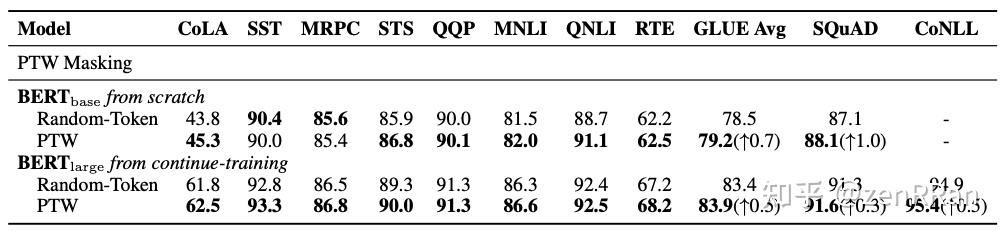 POS-Tagging Weighted (PTW) Masking实验对比 POS-Tagging Weighted (PTW) Masking实验对比 原始固定ratio和cosine decay对比 原始固定ratio和cosine decay对比另外,作者也做了其他decay的花式尝试:  各种花式变化 各种花式变化 其他decay对比总结 其他decay对比总结掩码语言模型预训练通常可以由两个主要因素来定义,掩码率和掩码内容。现有研究采用的 Random-Token Masking 方案平等对待所有单词,并在整个预训练过程中保持固定比例,这在我们的分析中显示为次优。 为了更好地发挥 MLM 的优势,我们探索了两种时变掩蔽策略,即掩蔽比衰减 (MRD) 和词性标记加权 (PTW) 掩蔽。 实验结果验证了我们的假设,即 MLM 受益于根据动态训练状态的掩蔽率和掩蔽内容的时变设置。我们的进一步分析表明,这两种时变掩蔽计划极大地提高了预训练效率和下游任务的性能。 关注zenRRan,可以快速了解到最新优质的NLP前沿技术和相关论文~ 点击进入——>微信NLP技术交流群 历史文章斯坦福+南洋理工等五大机构对ChatGPT做了在NLP任务上的优劣势的详细分析 AAAI2023 | 百度+中科院提出USM:一种信息抽取的大一统方法 COLING2022 | 中科院+北邮提出:具有Event-Argument相关性的事件因果关系提取方法 陈丹琦提出:带有语言约束的可控文本生成 邱锡鹏提出:DiffusionBERT - 用扩散模型改进生成式掩码语言模型 谷歌提出Flan预训练方法,一个模型解决可所有NLP任务,并发布Flan-T5模型 COLING'22 | SelfMix:针对带噪数据集的半监督学习方法 近200篇文章汇总而成的机器翻译非自回归生成最新综述,揭示其挑战和未来研究方向 一种全新易用的基于Word-Word关系的NER统一模型,刷新了14种数据集并达到新SoTA 阿里+北大 | 在梯度上做简单mask竟有如此的神奇效果 NAACL2021 | 陈丹琦又打破常规,最近流行的实体识别和关系抽取要回到最初状态? 清华刘知远联合新加坡国立大学提出CPT:基于预训练视觉-语言模型的跨模态Prompt-Tuning 让人深思:句法真的重要吗?邱锡鹏组提出一种基于Aspect的情感分析的强大基线 复旦邱锡鹏Lab提出:一个统一的面向基于Aspect的所有情感分析子任务的生成式方法 清华提出:用于细粒度实体分类的Prompt-Learning,并提出可训练Prompt模板 ACL2021 | 一种巧妙解决NER覆盖和不连续问题的方法 NAACL2021 | 苏大&阿里提出:一种统一的基于跨度的意见挖掘方法 一种巧妙且简单的数据增强方法 - MixUp 小综 |
【本文地址】