| Python数据分析案例30 | 您所在的位置:网站首页 › 中国票房前三名影片 › Python数据分析案例30 |
Python数据分析案例30
|
案例背景
最近总看到《消失的她》票房多少多少,《孤注一掷》票房又破了多少多少..... 于是我就想自己爬虫一下获取中国高票房的电影数据,然后分析一下。 数据来源于淘票票:影片总票房排行榜 (maoyan.com)
爬它就行。 不会爬虫的同学要这代码演示数据可以参考:数据 代码实现 首先爬虫获取数据: 数据获取导入包 import requests; import pandas as pd from bs4 import BeautifulSoup传入网页和请求头 url = 'https://piaofang.maoyan.com/rankings/year' headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.62'} response1 = requests.get(url,headers=headers) response.status_code
然后解析网页文件,获取电影信息数据 %%time soup = BeautifulSoup(response.text, 'html.parser') soup=soup.find('div', id='ranks-list') movie_list = [] for ul_tag in soup.find_all('ul', class_='row'): movie_info = {} li_tags = ul_tag.find_all('li') movie_info['序号'] = li_tags[0].text movie_info['标题'] = li_tags[1].find('p', class_='first-line').text movie_info['上映日期'] = li_tags[1].find('p', class_='second-line').text movie_info['票房(亿)'] = f'{(float(li_tags[2].text)/10000):.2f}' movie_info['平均票价'] = li_tags[3].text movie_info['平均人次'] = li_tags[4].text movie_list.append(movie_info)数据获取完成了! 查看字典数据: movie_list
可以,很标准,没什么问题,然后把它变成数据框,查看前三行 movies=pd.DataFrame(movie_list) movies.head(3)
对数据进行一定的清洗,我们看到上映日期里面的数据有“上映”两个字,我们要去掉,然后把它变成时间格式,票房,票价,人次都要变成数值型数据。 我们只取票房前250的电影,对应豆瓣250.,,,,中国票房250好叭 然后我们还需要从日期里面抽取年份和月份两列数据,方便后面分析。 #清洗 movies=movies.set_index('序号').loc[:'250',:] movies['上映日期']=pd.to_datetime(movies['上映日期'].str.replace('上映','')) movies[['票房(亿)','平均票价','平均人次']]=movies.loc[:,['票房(亿)','平均票价','平均人次']].astype(float) movies['年份']=movies['上映日期'].dt.year ; movies['月份']=movies['上映日期'].dt.month movies.head(2)
数据处理完毕,开始画图分析! 画图分析导入画图包 import seaborn as sns import matplotlib.pyplot as plt plt.rcParams ['font.sans-serif'] ='SimHei' #显示中文 plt.rcParams ['axes.unicode_minus']=False对票房排名前20的电影画柱状图 top_movies = movies.nlargest(20, '票房(亿)') plt.figure(figsize=(7, 4),dpi=128) ax = sns.barplot(x='票房(亿)', y='标题', data=top_movies, orient='h',alpha=0.5) #plt.xticks(rotation=80, ha='center') # 在柱子上标注数值 for p in ax.patches: ax.annotate(f'{p.get_width():.2f}', (p.get_width(), p.get_y() + p.get_height() / 2.), va='center', fontsize=8, color='gray', xytext=(5, 0), textcoords='offset points') plt.title('票房前20的电影') plt.xlabel('票房数量(亿)') plt.ylabel('电影名称') plt.tight_layout() plt.show()
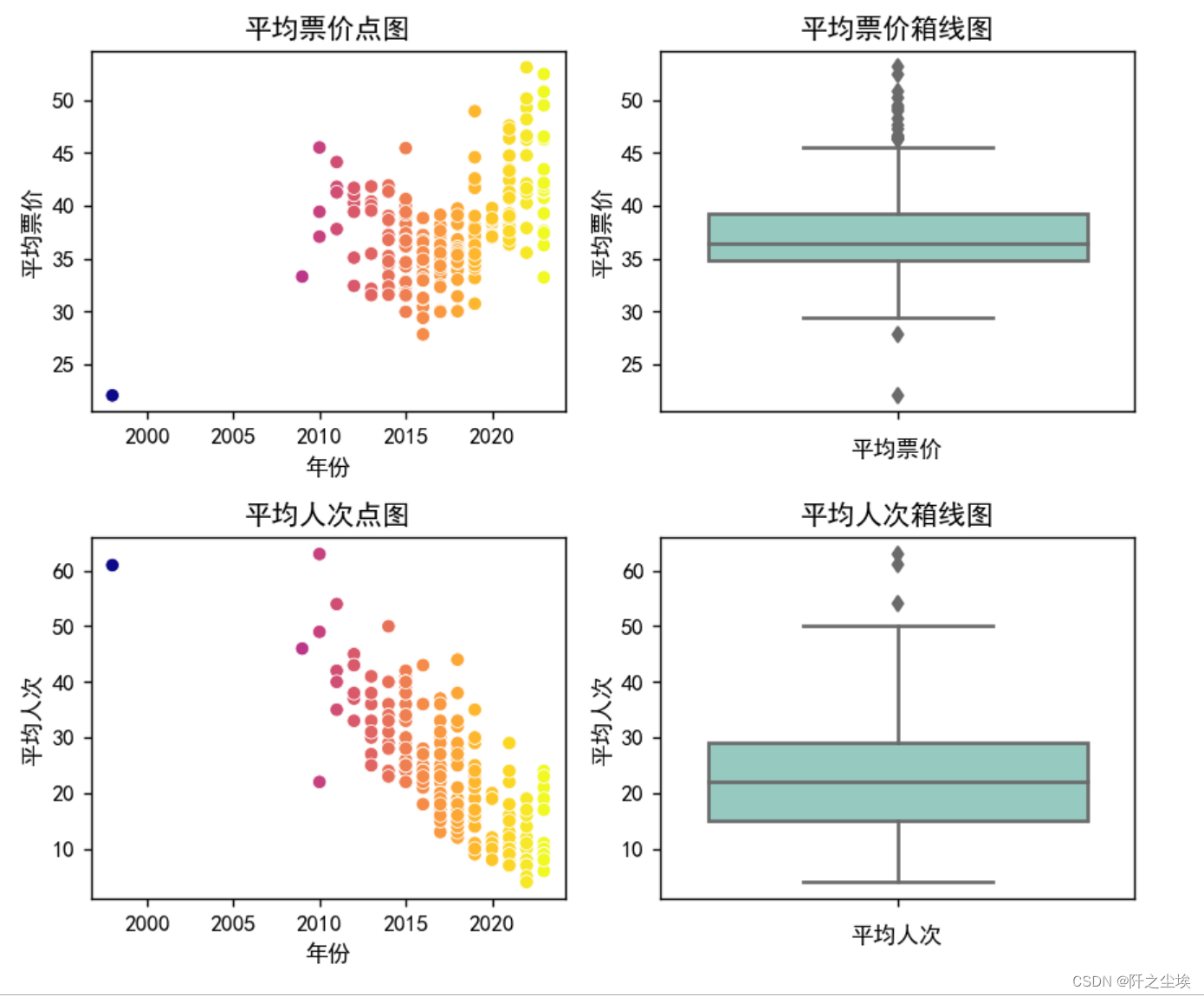
还不错,很好看,可以看到中国历史票房前20 的电影名称和他们的票房数量。 对平均票价和平均人次进行分析: plt.figure(figsize=(7, 6),dpi=128) # 绘制第一个子图:平均票价点图 plt.subplot(2, 2, 1) sns.scatterplot(y='平均票价', x='年份', data=movies,c=movies['年份'],cmap='plasma') plt.title('平均票价点图') plt.ylabel('平均票价') #plt.xticks([]) plt.subplot(2, 2, 2) sns.boxplot(y='平均票价', data=movies) plt.title('平均票价箱线图') plt.xlabel('平均票价') plt.subplot(2, 2, 3) sns.scatterplot(y='平均人次', x='年份', data=movies,c=movies['年份'],cmap='plasma') plt.title('平均人次点图') plt.ylabel('平均人次') plt.subplot(2, 2, 4) sns.boxplot(y='平均人次', data=movies) plt.title('平均人次箱线图') plt.xlabel('平均人次') plt.tight_layout() plt.show()
先看柱状图,可以看到平均票价和平均人次都是有一些离群点的,然后我们在左边画了他们和年份的的散点图,可以明细看到,随着年份越大,电影的平均人次越来越低,平均票价越来越高.....也就是最近的电影比起之前的电影来说,越来越贵,而且平均每场看的人越来越少......也侧面反映了我国电影业的一些“高票价”,‘幽灵剧场刷票房’ 等等乱象... 我注意到2000年之前有一个电影每场人次特别高,票价很低,它是什么电影我很好奇我就查看了一下: movies[movies['年份'] |

 200表示获取网页文件成功
200表示获取网页文件成功



【本文地址】
公司简介
联系我们