| Python实战案例:爬取中国执行信息公开网 | 您所在的位置:网站首页 › 中国执行信息公开网客服电话号码 › Python实战案例:爬取中国执行信息公开网 |
Python实战案例:爬取中国执行信息公开网
|
从面试题谈起
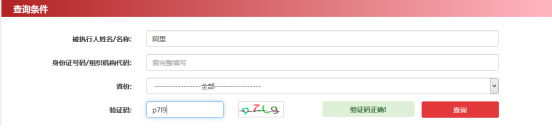
谈到这个项目的爬虫,就要从一道面试题谈起了。 这道面试题是: 请写一个爬虫从网址 http://zxgk.court.gov.cn/shixin/,检索被执行人姓名:"阿里",并填入验证码后查询,抓取结果列表,与对应的详情,并将内容导出为csv。 根据这道面试题的情境,进入到地址http://zxgk.court.gov.cn/shixin/,在“被执行人姓名/名称”后面的输入框中输入“阿里”,再输入验证码,点击红色的“查询”按钮。如下图所示。
现在需要抓取的是查询后的结果数据,如下图所示。
首先必须明确这些数据是点击查询后出现的动作,可以先审阅代码,在”查询"按钮的地方右键”查看元素",找到点击这个按钮后发生了什么样的动作.如下图所示。
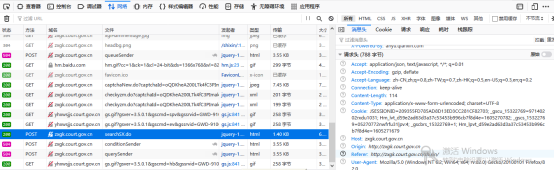
在整个网页空白处右键"查看页面源代码",从”源代码"中搜索出search方法,看一下search方法实现逻辑.如图所示.
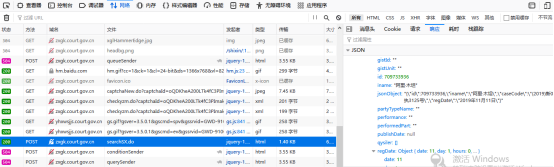
从图中,可以看到search方法中有一个ajax的请求,ajax请求的url地址可以看到是searchSX.do。这个地址可以从网页“查看元素”的“Network”或网络中可以查看一下这个请求最终的响应结果是什么样的数据。如下图所示。
由上图中可以看到左边接口地址searchSX.do,对应的右边的响应结果是阿里最终的查询结果。通过这样的分析,以这里只需要知道接口请求的请求头中需要哪些信息即可。如图所示。
如上图所示,在右边的窗口中点击:“消息头”,就可以看到请求头中的相关内容。在请求头中有很多项。 第一项: Acceptapplication/json,text/javascript,*/*;q=0.01这是Accept客户端能够接受的MIME的类型。在爬虫请求时可以忽略不设置。 第二项: Accept-Encoding:gzip, deflate这是客户端允许的编码,也可以在爬虫请求时忽略不设置。 第三项 Accept-Language:zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2这是客户端允许的语言,一般在中国,都是简体中文,爬虫请求时也可以忽略不设置。 第四项 Connection:keep-alive,这是保持连接,爬虫爬取时也可以忽略不设置。 第五项: Content-Length:114,这是内容的长度,针对本次爬取,爬取可以不设置这个选项。 第六项: Content-Type:application/x-www-form-urlencoded; charset=UTF-8,这句标志内容类型,针对本次爬取,爬取时也可以不设置这个选项。 第七项: Cookie:JSESSIONID=209355FD785AD8D13ED3CC281CF82703; _gscu_15322769=97140202rxdu1031; Hm_lvt_d59e2ad63d3a37c53453b996cb7f8d4e=1605270782; _gscs_15322769=05270772nwfrfu31|pv:4; _gscbrs_15322769=1; Hm_lpvt_d59e2ad63d3a37c53453b996cb7f8d4e=1605271679,这句是访问这个网站时产生的,这一项必须包括在内,不然爬虫可能爬取不到相关的内容。 第八项: Host:zxgk.court.gov.cn主机名字,这个选项在爬取时可以不设置这个选项。 第九项: Origin:http://zxgk.court.gov.cn,这个选项爬取时也可以不设置。 第十项: Referer:http://zxgk.court.gov.cn/shixin/,如果目标爬取的网站做过盗链的条件下,这个选项是必须要进行设置的. 第十一项: User-Agent:Mozilla/5.0 (Windows NT 6.2; Win64; x64; rv:82.0) Gecko/20100101 Firefox/82.0,爬取网站时模拟浏览器的客户端动作,这个选项有助于防止服务器进行反爬,也决定了这个选项是必须要进行设置的. 通过以上的分析,请求头必须有的选项定义headers字典如下. headers={ “User-Agent”:“Mozilla/5.0 (Windows NT 6.2; Win64; x64; rv:82.0) Gecko/20100101 Firefox/82.0”, “referer”:“http://zxgk.court.gov.cn/shixin/”, “cookie”:“JSESSIONID=209355FD785AD8D13ED3CC281CF82703; _gscu_15322769=97140202rxdu1031; Hm_lvt_d59e2ad63d3a37c53453b996cb7f8d4e=1605270782; _gscs_15322769=05270772nwfrfu31|pv:4; _gscbrs_15322769=1; Hm_lpvt_d59e2ad63d3a37c53453b996cb7f8d4e=1605271679” }接下来再点击“查看元素”中“network”或“网络”选项卡的右边“请求”的标签,如下图所示。
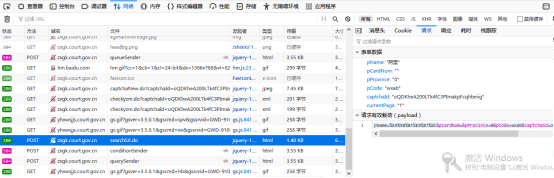
从图中可以看到,请求的表单数据中是包括了如下的字典参数,可以用params变量来保存这个字典变量参数。 params={ “pName”:“阿里”, “pCardNum”:“”, “pProvince”:“0”, “PCode”:“wxab”, “captchaId”:“oQDKheA200LTk4fC3PImakpFcqhbeiig”, “currentPage”:“1” }在以上这个字典参数中,pName就是搜索的关键词,pCode就是对应的验证码,pCardNum、pProvince这两个参数不起什么作用,currentPage是页码的问题,关键是captchaId这个参数到底是个什么东西是值得研究的问题。 针对于capchaId的研究只能针对源码进行。通过“查看网页源代码”,可以看到如下图所示的代码。
从上面截取的代码上看,是能够找到captchaId,并且capthaId的值就是uuid的值进行了repace()方法的替换得到了.那么uuid是如何产生的呢?就是function getNum()中的方法得到了.只要把function getNum()的方法用Python的语言写出来就可以了. Python语言改写前端函数function getNum()中的方法是前端的语言,把前端转成Python语言可以遵循以下的原则. (1)把function字母改成def。 (2)把var赋值语句中的var去掉。 (3)把for循环的格式如for(var i=0;i |




【本文地址】
| 今日新闻 |
| 推荐新闻 |
| 专题文章 |