| 还在用付费VIP追剧?神级程序员教你用Python任意下! | 您所在的位置:网站首页 › 不需要vip的追剧神器 › 还在用付费VIP追剧?神级程序员教你用Python任意下! |
还在用付费VIP追剧?神级程序员教你用Python任意下!
|
但是这个网站只提供了在线解析视频的功能,没有提供下载接口,如果想把视频下载下来,我们就可以利用网络爬虫进行抓包,将视频下载下来。 实战升级 分析方法相同,我们使用Fiddler进行抓包:
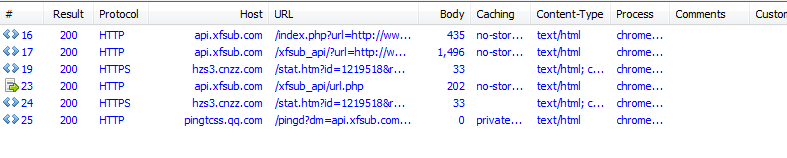
我们可以看到,有用的请求并不多,我们逐条分析。我们先看第一个请求返回的信息。
可以看到第一个请求是GET请求,没有什么有用的信息,继续看下一条。
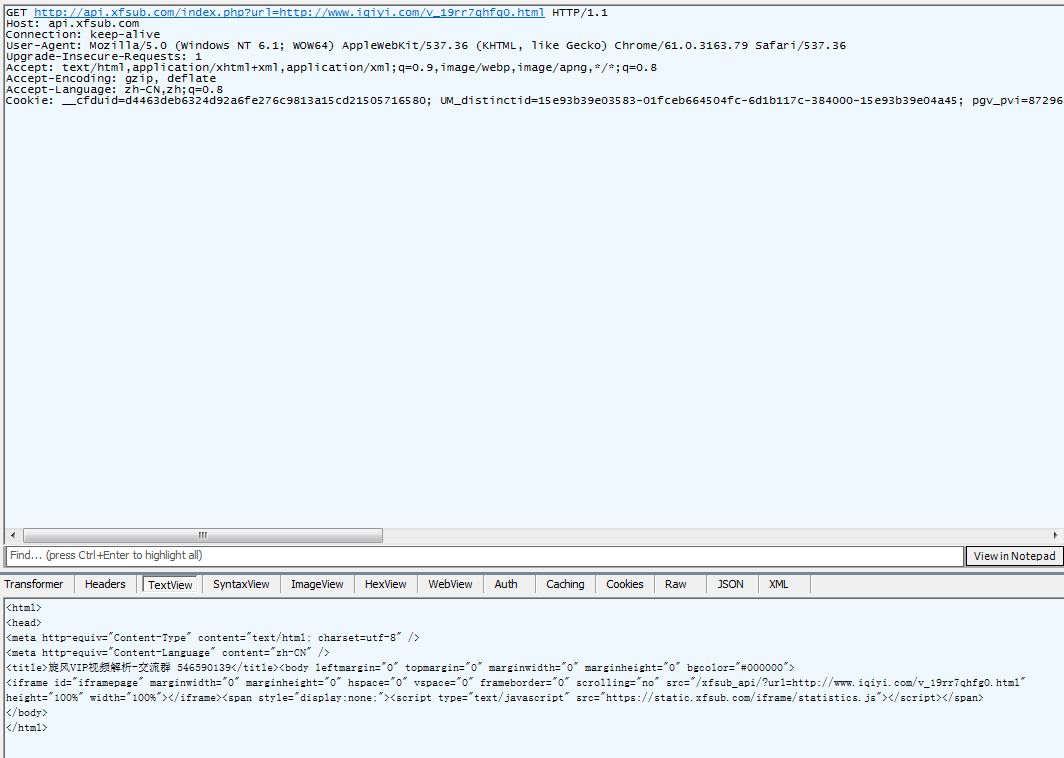
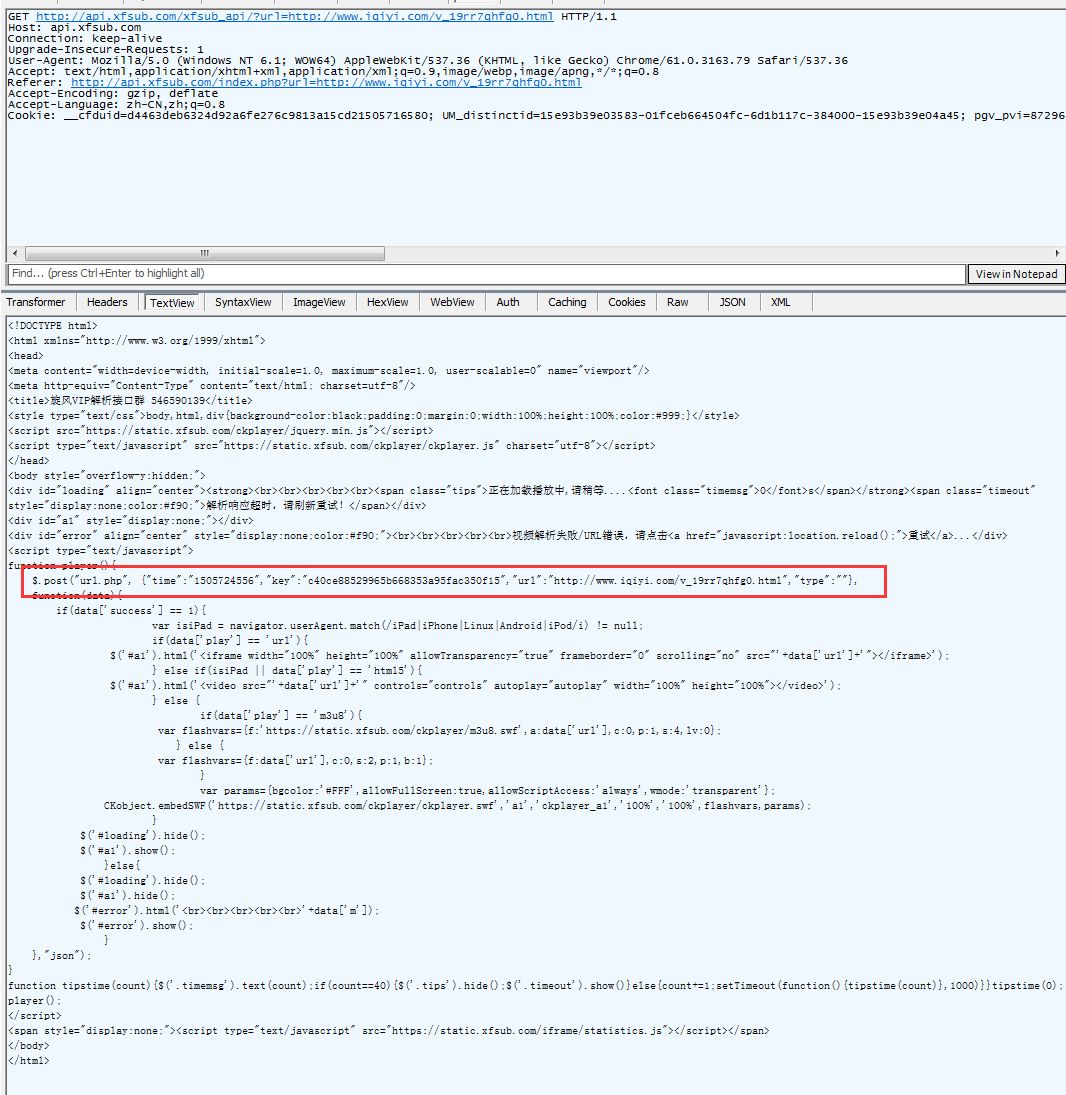
我们看到,第二条GET请求地址变了,并且在返回的信息中,我们看到,这个网页执行了一个POST请求。POST请求是啥呢?它跟GET请求正好相反,GET是从服务器获得数据,而POST请求是向服务器发送数据,服务器再根据POST请求的参数,返回相应的内容。这个POST请求有四个参数,分别为time、key、url、type。记住这个有用的信息,我们在抓包结果中,找一下这个请求,看看这个POST请求做了什么。
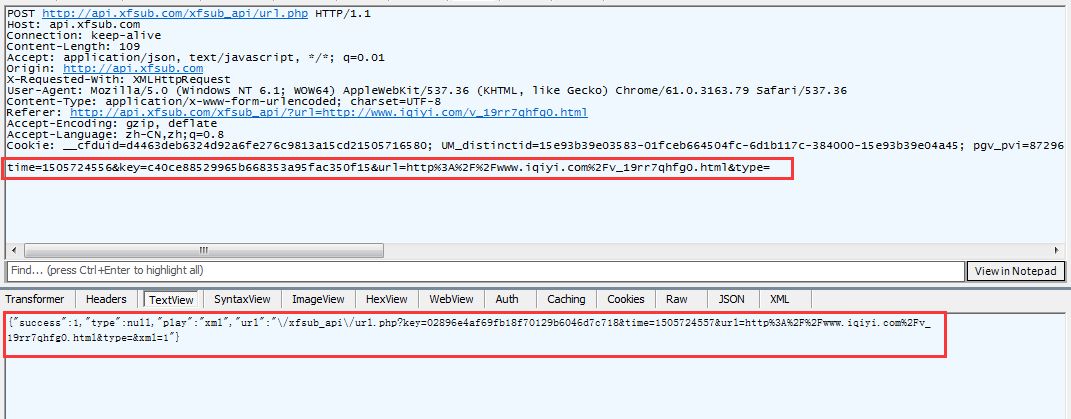
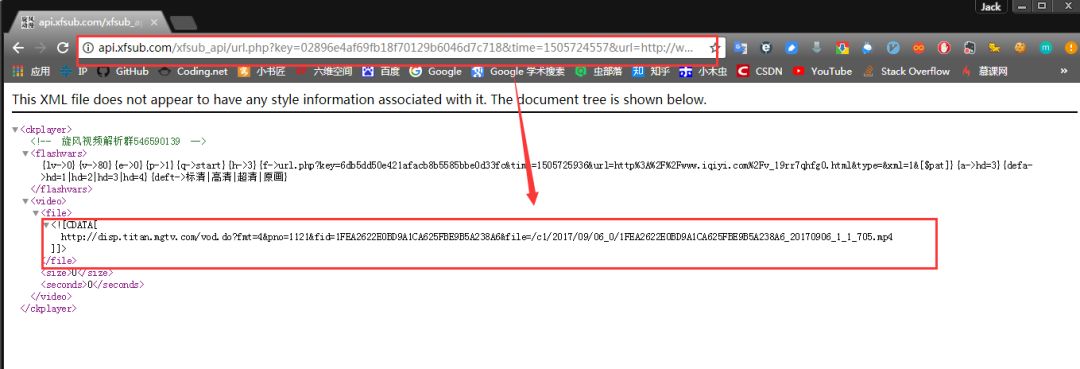
很显然,这个就是我们要找的POST请求,我们可以看到POST请求的参数以及返回的json格式的数据。其中url存放的参数如下: xfsub_api/url.php?key=02896e4af69fb18f70129b6046d7c718&time=1505724557&url=http%3A%2F%2Fwww.iqiyi.com%2Fv_19rr7qhfg0.html&type=&xml=1 xfsub_api/url.php?key=02896e4af69fb18f70129b6046d7c718&time=1505724557&url=http%3A%2F%2Fwww.iqiyi.com%2Fv_19rr7qhfg0.html&type=&xml=1 这个信息有转义了,但是没有关系,我们手动提取一下,变成如下形式: xfsub_api/url.php?key=02896e4af69fb18f70129b6046d7c718&time=1505724557&url=http://www.iqiyi.com/v_19rr7qhfg0.html&type=&xml=1 xfsub_api/url.php?key=02896e4af69fb18f70129b6046d7c718&time=1505724557&url=http://www.iqiyi.com/v_19rr7qhfg0.html&type=&xml=1 我们已经知道了这个解析视频的服务器的域名,再把域名加上: http://api.xfsub.com/xfsub_apiurl.php?key=02896e4af69fb18f70129b6046d7c718&time=1505724557&url=http://www.iqiyi.com/v_19rr7qhfg0.html&type=&xml=1 http://api.xfsub.com/xfsub_apiurl.php?key=02896e4af69fb18f70129b6046d7c718&time=1505724557&url=http://www.iqiyi.com/v_19rr7qhfg0.html&type=&xml=1 这里面存放的是什么东西?不会视频解析后的地址吧?我们有浏览器打开这个地址看一下:
我们再打开这个视频地址:
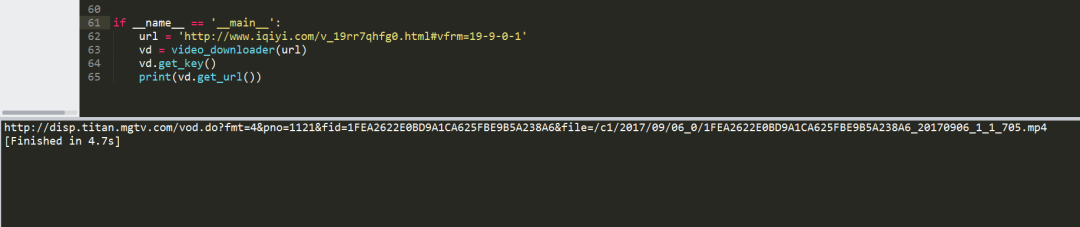
瞧,我们就这样得到了这个视频在服务器上的缓存地址。根据这个地址,我们就可以轻松下载视频了。 PS:需要注意一点,这些URL地址,都是有一定时效性的,很快就会失效,因为里面包含时间信息。所以,各位在分析的时候,要根据自己的URL结果打开网站才能看到视频。 接下来,我们的任务就是编程实现我们所分析的步骤,根据不同的视频播放地址获得视频存放的地址。 现在梳理一下编程思路: 用正则表达式匹配到key、time、url等信息。 根据匹配的到信息发POST请求,获得一个存放视频信息的url。 根据这个url获得视频存放的地址。 根据最终的视频地址,下载视频。编写代码 编写代码的时候注意一个问题,就是我们需要使用requests.session()保持我们的会话请求。简单理解就是,在初次访问服务器的时候,服务器会给你分配一个身份证明。我们需要拿着这个身份证去继续访问,如果没有这个身份证明,服务器就不会再让你访问。这也就是这个服务器的反爬虫手段,会验证用户的身份。 #-*- coding:UTF-8 -*- importrequests,re, json frombs4 importBeautifulSoup classvideo_downloader(): def__init__(self, url): self.server = 'http://api.xfsub.com' self.api = 'http://api.xfsub.com/xfsub_api/?url=' self.get_url_api = 'http://api.xfsub.com/xfsub_api/url.php' self.url = url.split( '#')[ 0] self.target = self.api + self.url self.s = requests.session() """ 函数说明:获取key、time、url等参数 Parameters: 无 Returns: 无 Modify: 2017-09-18 """ defget_key(self): req = self.s.get(url=self.target) req.encoding = 'utf-8' self.info = json.loads(re.findall( '"url.php", (.+),', req.text)[ 0]) #使用正则表达式匹配结果,将匹配的结果存入info变量中 """ 函数说明:获取视频地址 Parameters: 无 Returns: video_url - 视频存放地址 Modify: 2017-09-18 """ defget_url(self): data = { 'time':self.info[ 'time'], 'key':self.info[ 'key'], 'url':self.info[ 'url'], 'type': ''} req = self.s.post(url=self.get_url_api,data=data) url = self.server + json.loads(req.text)[ 'url'] req = self.s.get(url) bf = BeautifulSoup(req.text, 'xml') #因为文件是xml格式的,所以要进行xml解析。 video_url = bf.find( 'file').string #匹配到视频地址 returnvideo_url if__name__ == '__main__': url = 'http://www.iqiyi.com/v_19rr7qhfg0.html#vfrm=19-9-0-1' vd = video_downloader(url) vd.get_key() print(vd.get_url()) 思路已经给出,希望喜欢爬虫的人可以在运行下代码之后,自己重头编写程序,因为只有经过自己分析和测试之后,才能真正明白这些代码的意义。上述代码运行结果如下:
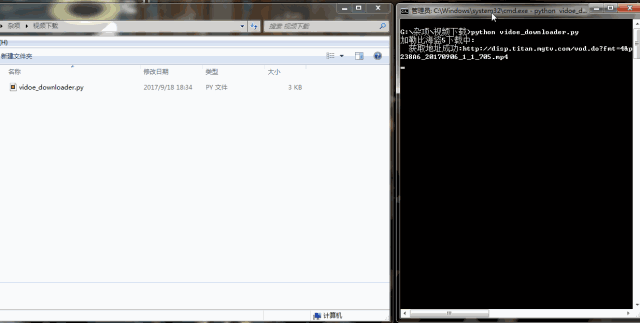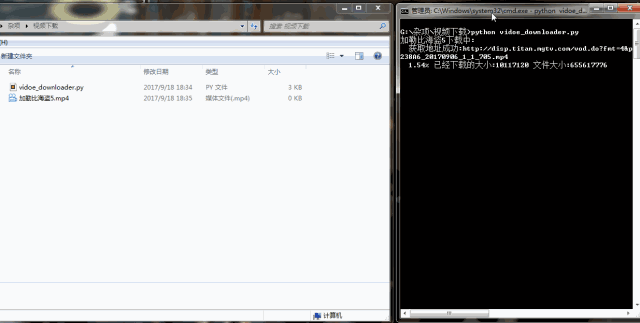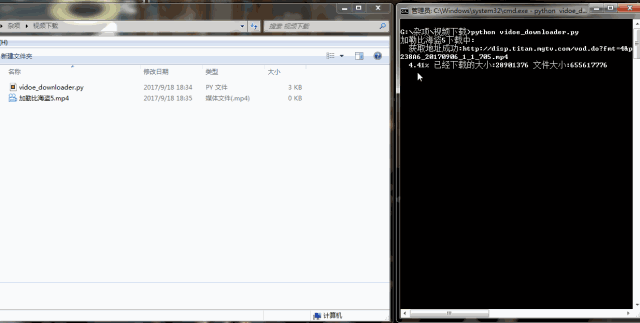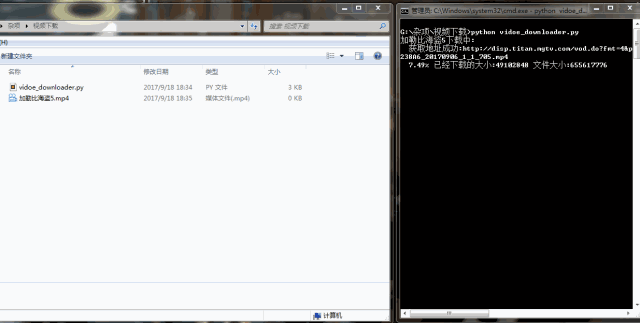
我们已经顺利获得了mp4这个视频文件地址。根据视频地址,使用urllib.request.urlretrieve()即可将视频下载下来。编写代码如下: #-*- coding:UTF-8 -*- importrequests,re, json, sys frombs4 importBeautifulSoup fromurllib importrequest classvideo_downloader(): def__init__(self, url): self.server = 'http://api.xfsub.com' self.api = 'http://api.xfsub.com/xfsub_api/?url=' self.get_url_api = 'http://api.xfsub.com/xfsub_api/url.php' self.url = url.split( '#')[ 0] self.target = self.api + self.url self.s = requests.session() """ 函数说明:获取key、time、url等参数 Parameters: 无 Returns: 无 Modify: 2017-09-18 """ defget_key(self): req = self.s.get(url=self.target) req.encoding = 'utf-8' self.info = json.loads(re.findall( '"url.php", (.+),', req.text)[ 0]) #使用正则表达式匹配结果,将匹配的结果存入info变量中 """ 函数说明:获取视频地址 Parameters: 无 Returns: video_url - 视频存放地址 Modify: 2017-09-18 """ defget_url(self): data = { 'time':self.info[ 'time'], 'key':self.info[ 'key'], 'url':self.info[ 'url'], 'type': ''} req = self.s.post(url=self.get_url_api,data=data) url = self.server + json.loads(req.text)[ 'url'] req = self.s.get(url) bf = BeautifulSoup(req.text, 'xml') #因为文件是xml格式的,所以要进行xml解析。 video_url = bf.find( 'file').string #匹配到视频地址 returnvideo_url """ 函数说明:回调函数,打印下载进度 Parameters: a b c - 返回信息 Returns: 无 Modify: 2017-09-18 """ defSchedule(self, a, b, c): per = 100.0*a*b/c ifper > 100: per = 1 sys.stdout.write( " "+ "%.2f%% 已经下载的大小:%ld 文件大小:%ld"% (per,a*b,c) + 'r') sys.stdout.flush() """ 函数说明:视频下载 Parameters: url - 视频地址 filename - 视频名字 Returns: 无 Modify: 2017-09-18 """ defvideo_download(self, url, filename): request.urlretrieve(url=url,filename=filename,reporthook=self.Schedule) if__name__ == '__main__': url = 'http://www.iqiyi.com/v_19rr7qhfg0.html#vfrm=19-9-0-1' vd = video_downloader(url) filename = '加勒比海盗5' print( '%s下载中:'% filename) vd.get_key() video_url = vd.get_url() print( ' 获取地址成功:%s'% video_url) vd.video_download(video_url, filename+ '.mp4') print( 'n下载完成!') urlretrieve()有三个参数,第一个url参数是视频存放的地址,第二个参数filename是保存的文件名,最后一个是回调函数,它方便我们查看下载进度。代码量不大,很简单,主要在于分析过程。代码运行结果如下:
下载速度挺快的,几分钟视频下载好了。
对于这个程序,感兴趣的朋友可以进行扩展一下,设计出一个小软件,根据用户提供的url,提供PC在线观看、手机在线观看、视频下载等功能。 我们的程序员不仅工作中独当一面,生活中也很厉害哦!简直就是大神一般的存在。现在达妹也给你一个成为大神的机会。 达内6月免费训练营火热招生中,入门高薪互联网行业,全程大咖级讲师亲授,为你解析行业发展趋势,就业前景,帮你了解技术,轻松入门,更快一步成为技术大牛!返回搜狐,查看更多 |



【本文地址】