| 准确度(accuracy)、精确率(precision)、召回率(recall)、F1值 谈谈我的看法 | 您所在的位置:网站首页 › 万用表指针式和数字哪个准确率高 › 准确度(accuracy)、精确率(precision)、召回率(recall)、F1值 谈谈我的看法 |
准确度(accuracy)、精确率(precision)、召回率(recall)、F1值 谈谈我的看法
|
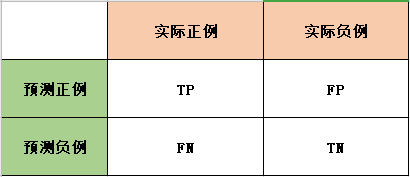
目录 前言 基本概念 准确率 Accuracy 精确度 Precision 召回率 Recall F1 值 sklearn 的评估函数 pyspark 的评估函数 tensorflow 的评估函数 多分类下的评估 前言准确度、精确率、召回率、F1值作为评估指标,经常用到分类效果的评测上。比较好理解的二分类问题,准确度评估预测正确的比例,精确率评估预测正例的查准率,召回率评估真实正例的查全率。如何把这些评估指标用到多分类上呢,比如有三个类别A、B、C,准确度好理解,只要关系是否预测正确即可;那么精确率和召回率怎么理解呢?我们可以把多分类问题拆分成多个二分类问题,比如A类别是否预测正确,B类别是否预测正确,C类别是否预测正确,分别计算各个类别的每个类别的精确率和召回率,最终求均值既能作为所有样本的评估指标。 基本概念TP(True Positives):真正例,预测为正例而且实际上也是正例; FP(False Positives):假正例,预测为正例然而实际上却是负例; FN(false Negatives):假负例,预测为负例然而实际上却是正例; TN(True Negatives):真负例,预测为负例而且实际上也是负例。
记忆要点:正负例的是依据预测值,真假是依据实际值。真正例的意思,预测为正例,实际上是真的正例。 用二分类的问题类举例,有黑白色球,真实的球个数是黑球3个,白球7个,编号和真实颜色如下表格:
模型预测结果为黑球4个,白球6个,预测结果入下表格,红色代表预测正确:
如果我们以黑球为正例标准,则可以统计出: TP:2个, 预测是黑色的,实际就是黑色的,即黑字红色部分。 FP:2个,预测是黑色的,实际是白色的,即黑字黑色部分,即编号4和5。 FN:1个,预测是白色的,实际是黑色的,即白字黑色部分,即编号3。 TN:5个。预测是白色的,实际是白色的,即白字红色部分。 准确率 Accuracy准确度:正例和负例中预测正确数量占总数量的比例,用公式表示: 继续用用黑球白球的例子计算,就是红色字部分黑色2个,白色5个,共7个预测正确,则ACC=0.7。 准确度好理解,就是所有预测样本中预测准确的占比,就不多费文墨解释了。 精确度 Precision精确度:以预测结果为判断依据,预测为正例的样本中预测正确的比例。预测为正例的结果分两种,要么实际是正例TP,要么实际是负例FP,则可用公式表示: 精确度还有一个名字,叫做“查准率”,我们关心的主要部分是正例,所以查准率就是相对正例的预测结果而言,正例预测的准确度。直白的意思就是模型预测为正例的样本中,其中真正的正例占预测为正例样本的比例,用此标准来评估预测正例的准确度。 还是用之前黑白求的例子计算,令黑色为正例标准,预测为正例的有4个黑球,其中真正是黑球的有两个,则p=0.5。 召回率 Recall召回率:以实际样本为判断依据,实际为正例的样本中,被预测正确的正例占总实际正例样本的比例。实际为正例的样本中,要么在预测中被预测正确TP,要么在预测中预测错误FN,用公式表示: 召回率的另一个名字,叫做“查全率”,评估所有实际正例是否被预测出来的覆盖率占比多少,我们实际黑球个数是3个,被准确预测出来的个数是2个,所有召回率r=2/3。 F1 值单独用精确率或者召回率是否能很好的评估模型好坏,举个例子: 1、什么情况下精确率很高但是召回率很低? 一个极端的例子,比如我们黑球实际上有3个,分别是1号、2号、3号球,如果我们只预测1号球是黑色,此时预测为正例的样本都是正确的,精确率p=1,但是召回率r=1/3。 2、什么情况下召回率很高但是精确率很低? 如果我们10个球都预测为黑球,此时所有实际为黑球都被预测正确了,召回率r=1,精确率p=3/10。 F1值就是中和了精确率和召回率的指标: 当P和R同时为1时,F1=1。当有一个很大,另一个很小的时候,比如P=1,R~0,此时F1~0。分子2PR的2完全了为了使最终取值在0-1之间,进行区间放大,无实际意义。 sklearn 的评估函数 from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score y_true = [1, 1, 1, 0, 0, 0, 0, 0, 0, 0] y_pred = [1, 1, 0, 1, 1, 0, 0, 0, 0, 0] print("acc:", accuracy_score(y_true, y_pred)) print("p:", precision_score(y_true, y_pred)) print("r:", recall_score(y_true, y_pred)) print("f1:", f1_score(y_true, y_pred))输出结果为: acc: 0.7 p: 0.5 r: 0.6666666666666666 f1: 0.5714285714285715 pyspark 的评估函数 from pyspark.mllib.evaluation import MulticlassMetrics from pyspark import SparkConf, SparkContext conf = SparkConf() \ .setMaster("local") \ .setAppName("Metrics-test") sc = SparkContext(conf=conf) predictionAndLabels = sc.parallelize([ #(预测值,真实值) (1.0, 1.0), (1.0, 1.0), (0.0, 1.0), (1.0, 0.0), (1.0, 0.0), (0.0, 0.0), (0.0, 0.0), (0.0, 0.0), (0.0, 0.0), (0.0, 0.0)]) metrics = MulticlassMetrics(predictionAndLabels) print("acc:", metrics.accuracy) print("p:", metrics.precision(1.0)) # 必须传入label值,否则统计的是类别0和类别1的均值 print("r:", metrics.recall(1.0)) print("f1", metrics.fMeasure(1.0)) tensorflow 的评估函数 import tensorflow as tf train_graph = tf.Graph() with train_graph.as_default(): labels = tf.constant([1, 1, 1, 0, 0, 0, 0, 0, 0, 0]) predicts = tf.constant([1, 1, 0, 1, 1, 0, 0, 0, 0, 0]) # 返回的是一个二元组tuple accuracy = tf.metrics.accuracy(labels, predicts) precision = tf.metrics.precision(labels, predicts) recall = tf.metrics.recall(labels, predicts) f1 = tf.metrics.mean((2 * precision[1] * recall[1]) / (precision[1] + recall[1]), name='f1_score') with tf.Session(graph=train_graph) as sess: sess.run(tf.local_variables_initializer()) result = sess.run([accuracy, precision, recall, f1]) print(result)输出为: [(0.0, 0.7), (1.0, 0.5), (1.0, 0.6666667), (0.0, 0.57142854)] 后面一个才是真实值 多分类下的评估正如文章开头所说的那样,多分类问题的评估是可以转换成多个二分类的评估方式的,最后求均值就是多分类的评估指标。 二分类也可以看成是特殊的多分类,比如我们之前的例子,黑球和白球的预测问题。前面我们都是拿预测黑球当作正例,完全忽视了白球的预测情况,这样的评估也是不够完全的。如果我们也要考虑白球的预测情况呢,该如何修改评估指标?我们先算出黑球为正例时的评估指标,精确率、召回率、F1值,然后我们可以把白球当作正例,再算一次白球的精确率、召回率、F1值。最后算精确率的时候可以把黑球的准确率和白球的准确率进行求均值,就可以作为最后的评估指标。 之前的例子中,黑球为正例时,p=0.5;同理可计算白球为正例时,p=5/6;如果不考虑样本分布,无加权求均值,p=0.666。用sklearn的代码实现这个逻辑: from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score y_true = [1, 1, 1, 0, 0, 0, 0, 0, 0, 0] y_pred = [1, 1, 0, 1, 1, 0, 0, 0, 0, 0] print("p:", precision_score(y_true, y_pred, average='macro'))输出结果:p: 0.6666666666666667,与我们自己算的一致。sklearn还支持其他求均值方式,也可以自己设置权重值,这边就不说明,感兴趣可以自己看源码或者官方api。 我们看下类别更多的情况下,加入球色有黑、白、蓝三种颜色的球,真实颜色和预测颜色如下表格:
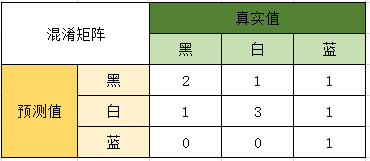
对预测结果统计成混淆矩阵:
按颜色计算精确率: P黑=2/4 P白=3/5 P蓝=1/1 求均值得p=0.7 from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score y_true = [1, 1, 1, 0, 2, 0, 2, 2, 0, 0] y_pred = [1, 1, 0, 1, 1, 0, 2, 0, 0, 0] print("p:", precision_score(y_true, y_pred, average='macro')) print("acc:", accuracy_score(y_true, y_pred))输出结果: p: 0.7000000000000001 acc: 0.6 与手算结果一致 同理对召回率,F1值同样计算 ~ That's all, Thank you for your attention! |



【本文地址】