| Python Pandas 从一个数据表里删除包含另外一个表的内容(取表格差集) | 您所在的位置:网站首页 › 一个表里面怎么删除重复的内容 › Python Pandas 从一个数据表里删除包含另外一个表的内容(取表格差集) |
Python Pandas 从一个数据表里删除包含另外一个表的内容(取表格差集)
|
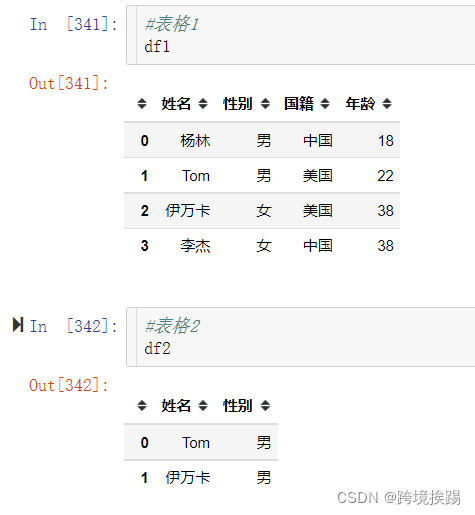
现在有2个表格A和B,需要把表格A里面包含B表格的内容全部删除,也就是希望结果为A-B(取差集)。2个表格有1列相同,比如说都有一列叫**‘姓名**,我要删除表格A里面含有表格B相同姓名的信息。 经过网上查询,发现Python强大的 Pandas库并没有直接的差集函数,只有表格合并功能。但是可以通过先合并再删除重复行的方法实现差集运算。就是通过pd.concat()函数先上下拼接表格A和B(做并集运算),然后再通过pd.drop_duplicates()函数删除重复的行,这样相当于变相实现了2个表格的差集减法运算。 示例代码如下: import pandas as pd df1=pd.DataFrame(data=[['杨林','男','中国','18'],['Tom','男','美国','22'],['伊万卡','女','美国','38'], ['李杰','女','中国','38']],columns=['姓名','性别','国籍','年龄']) df2=pd.DataFrame(data=[['Tom','男'],['伊万卡','男']],columns=['姓名','性别']) #上下合并表格,并重置索引 total=pd.concat([df1,df2], ignore_index=True, verify_integrity=True,sort=True) #删除合并后姓名里有重复的所有行 total.drop_duplicates(subset=['姓名'],keep=False,inplace=True) #subset=['姓名']表示检查姓名这一列是否有重复内容,keep=False表示不保留重复内容 运行过程如下截图:
|


【本文地址】
公司简介
联系我们