| 归一化、标准化、零均值化作用及区别 | 您所在的位置:网站首页 › z-score规范化值域 › 归一化、标准化、零均值化作用及区别 |
归一化、标准化、零均值化作用及区别
|
归一化、标准化、零均值化核心思想:平移+缩放 归一化、标准化的关系:  一、归一化 一、归一化【公式】  其中 x 为某个特征的原始值, x_{min} 为该特征在所有样本中的最小值, x_{max} 为该特征在所有样本中的最大值,x^* 为经过归一化处理后的特征值 ∈ (0, 1)。  【作用】将某个特征的值映射到[0,1]之间,消除量纲对最终结果的影响,使不同的特征具有可比性,使得原本可能分布相差较大的特征对模型有相同权重的影响,提升模型的收敛速度,深度学习中数据归一化可以防止模型梯度爆炸。 二、标准化 其中 x 为某个特征的原始值,μ 为该特征在所有样本中的平均值,\sigma 为该特征在所有样本中的标准差, x^* 为经过标准化处理后的特征值 ~ N(0, 1)。 【作用】将原值减去均值后除以标准差,使得得到的特征满足均值为0,标准差为1的正态分布,使得原本可能分布相差较大的特征对模型有相同权重的影响。举个例子,在KNN中,需要计算待分类点与所有实例点的距离。假设每个实例(instance)由n个features构成。如果选用的距离度量为欧式距离,数据预先没有经过归一化,那些绝对值大的features在欧式距离计算的时候起了决定性作用。 从经验上说,标准化后,让不同维度之间的特征在数值上有一定比较性,得出的参数值的大小可以反应出不同特征对样本label的贡献度,可以大大提高分类器的准确性。 【二者比较】具体应该选择归一化还是标准化呢,如果把所有维度的变量一视同仁, ①在计算距离中发挥相同的作用,应该选择标准化,标准化更适合现代嘈杂大数据场景。 ②如果想保留原始数据中由标准差所反映的潜在权重关系,或数据不符合正态分布时,选择归一化。  【注意】逻辑回归必须要进行标准化吗? 答案是,这取决于我们的逻辑回归是不是用了正则化。如果你不用正则,标准化并不是必须的,如果用正则,那么标准化是必须的。当然,无论哪种情况,标准化都有益无害。 为什么呢?因为不用正则时,我们的损失函数仅仅在度量预测与真实的差距,此时仅仅是参数更新速度慢,模型还是正确的;但加上正则化后,损失函数除了要度量上面的差距外,还要度量参数值是否足够小,而参数值的大小是与特征的数值范围相关的,如果不对特征进行标准化,则正则项偏向于关注数值范围大参数(对应的特征一般数值范围偏小),小参数都被忽略了,此时模型可能就会出错。 标准化注意事项:先拆分出test集,不要在整个数据集上做标准化,因为那样会将test集的信息引入到训练集中,这是一个非常容易犯的错误! 三、零均值化将每个像素的值减去训练集上所有像素值的平均值,比如已计算得所有像素点的平均值为128,所以减去128后,现在的像素值域即为[-128,127],即满足均值为零。  原始数据分布、零均值化数据分布、归一化数据分布 原始数据分布、零均值化数据分布、归一化数据分布【作用】可以避免“Z型更新”的情况,这样可以加快神经网络的收敛速度。下面将分别以Sigmoid、tanh以及ReLu三个最为经典的激活函数来分别说明。 3.1 sigmoid函数 首先以Sigmoid为激活函数来作为例子,Sigmoid函数的图像,公式如下: Sigmoid(x)=\frac{1}{1+e^{-x}} 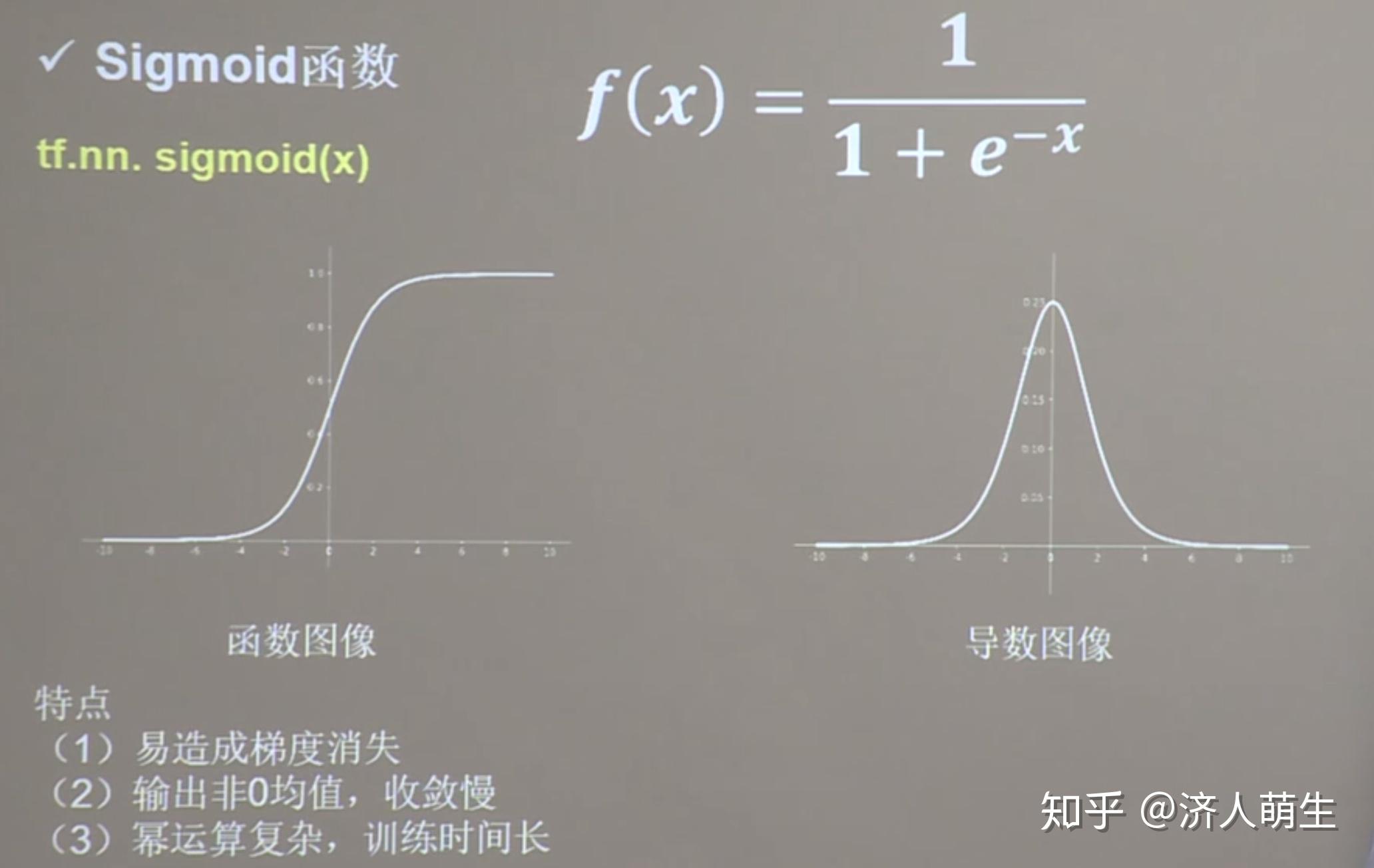 假设我们对数据不做零均值化,那么对于神经网络第一个隐藏层来讲,输入的数据 X 就全是正值(因为原始像素数值属于[0,255])。以第一个隐藏层的某一个神经元为例,当进行反向传播算法,梯度从反向到达该神经元时,根据链式法则,对权值 w 的梯度为全局传过来的梯度乘以激活函数对于 w 的梯度,即为公式:  所以 \frac{\partial f}{\partial w} 的正负只和 x 的正负有关,此时 x 全部为正,所以 \frac{\partial f}{\partial w} 的结果为正,加上 \frac{\partial f}{\partial w} 对于所有的 w 来说都是相同的,所以对于第一层的某个神经元的全部 w 来说,梯度的符号就是 \frac{\partial f}{\partial w}的符号,所以这些 w 的梯度符号全部一致,要么都为正要么都为负,所以该神经元的 w 都会往同一个方向更新,就会造成"Z型更新"现象,如下图所示:  Z型更新 Z型更新当然这是对于第一层的情况而言的,经过第一层的激活函数Sigmoid输出后,所有的输出值范围都在[0,1]之间,也就是都大于0,所以后面的第二层、第三层到最后一层,在反向传播时,由于输入的 x 符号都为正一致,就会出现Z型更新现象,使得网络收敛速度很慢,这就是Sigmoid函数非零均值导致的问题。所以对于Sigmoid函数来说,第2、3到最后层神经网络,是存在Z型更新问题的,对于输入数据的零均值化,能够避免第一层神经网络的Z型更新问题。 为了避免Z型更新的情况,将输入进行零均值化,这样某次输入就会是正负掺杂的输入,每个 w 的梯度符号和输入 x 相关,也就不会全部都一样,也就不会Z型更新了。 3.2 tanh函数 tanh函数也是经典的激活函数之一,函数图像,公式如下所示:   3.3 ReLU函数 ReLU是目前最通用的激活函数,函数图像、公式如下所示:   【参考】 [1] [2] [3] |
【本文地址】
| 今日新闻 |
| 推荐新闻 |
| 专题文章 |