| python提取word内容并写入excle | 您所在的位置:网站首页 › word表格如何保存到表格部件库中 › python提取word内容并写入excle |
python提取word内容并写入excle
|
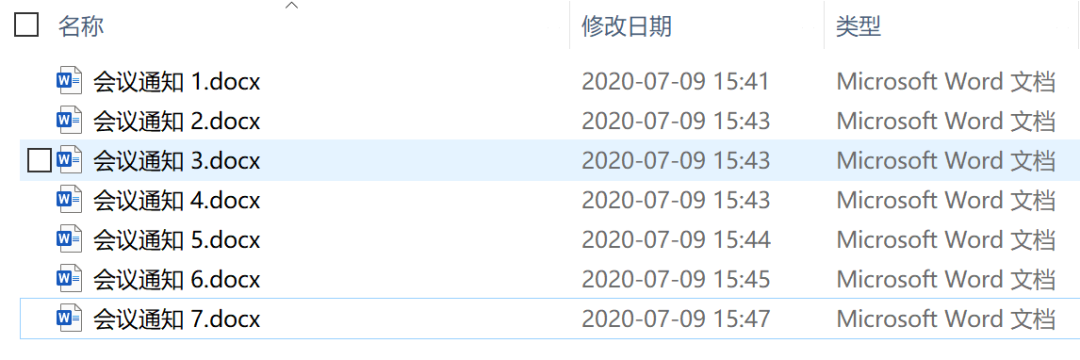
大概是这样,一个文件夹下有多份会议通知信息(本文以 7 份文件为例)
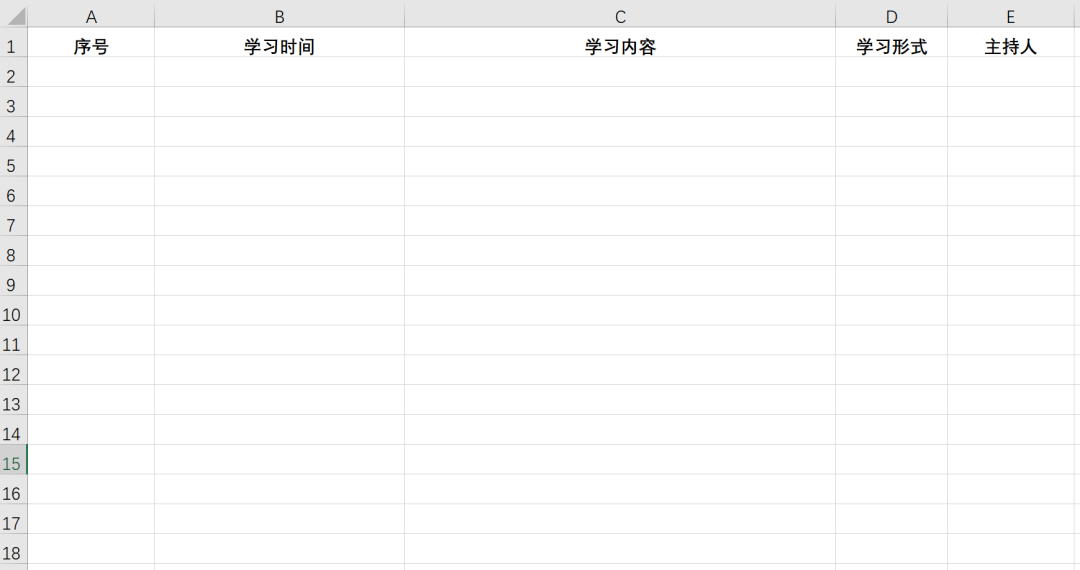
每一份通知打开格式基本类似,如下所示 👇 现在需要将每份会议文档中的 学习时间、学习内容、学习形式、主持人 四项关键信息提取出来,整理到 Excel 表格中:
在他真实需求中,会议通知四年积累下来有快 1000 份(四年开了这么多次会也是很厉害...),用人力挨个打开文件并录到 Excel 中工作量实在太大。 好家伙,这种重复的无聊工作, 不就是一份非常适合交给 Python 的自动化工作吗?我不允许我的粉丝还不会! 下面我们来看看如何用Python解决这个问题,主要将涉及: openpyxl 写入 Excel 文件 python-docx 读取 Word 文件 glob 批量获取文件路径 为了简化上面的需求,本文中需要获取的会议通知文件一共 7 个,分别命名为 会议通知1.docx会议通知2.docx... 会议通知7.docx,存放在 Notice 文件夹下。输出的目标 Excel 文件命名为 Meeting_temp.xlsx 基本逻辑写代码之前都先明确完整的问题需要分为几个小步骤实现。从需求中我们大概可以将代码分为以下几步: “获取会议通知 Notice 文件夹下的所有文件; 解析每一份 Word 文件,获取需要的四个信息,输出到 Excel 中; 保存 Excel 文件 ”有了逻辑就有了写代码的思路了。第 1 步可以由 glob 库完成,后面两步就是操作 Word 的 python-docx 库和操作 Excel 的 openpyxl 库的交互协作了。 这两个库我们都有说过,如果你不熟悉,一定要先阅读下面的文章! 👉python-docx操作Word详解 👉openpyxl操作Excel详解 代码实现首先导入需要的库: from docx import Document from openpyxl import load_workbook import glob将模板 Excel 读取进程序: path = r'C:\Users\xxx' # 路径为会议通知文件夹和 Excel 模板所在的位置,可按实际情况更改 workbook = load_workbook(path + r'\Meeting_temp.xlsx') sheet = workbook.active写任何批处理的代码之前都建议先写一下单次操作的代码,因此我们先完成对 会议通知 1.docx文件的解析,确保无误。现在对于文档的结构和关键信息的位置尚不明确,可以先将 Word 以段落Paragraph 为单位输出观察: wordfile = Document(path + r'\Notice\会议通知 1.docx') for paragraph in wordfile.paragraphs: print(paragraph)
文件的文字排布脉络比较清晰,基本是一句话对应一个段落,而需要的信息可以简单通过判断每句话(每段话)前几个字而明确: for paragraph in wordfile.paragraphs: if paragraph.text[0:5] == '学习时间:': study_time = paragraph.text[5:] if paragraph.text[0:4] == '主持人:': host = paragraph.text[4:] if paragraph.text[0:5] == '学习形式:': study_type = paragraph.text[5:]对于学习内容的获取比较特殊,不像其他三个信息,都在一句话中,且关键字就为前几个字:
可以看到,“学习内容” 四个字和真正包含的内容分散在不同的句子中. 这里简单用一个策略: “建立一个空列表存放,然后遍历每一段判断,如果一个字符为数字且第二个字符为中文顿号 “、” 就获取存放到列表中。最后把列表中的元素重新组合成一个长字符串即可: ” content_lst = [] for paragraph in wordfile.paragraphs: if paragraph.text[0:5] == '学习时间:': study_time = paragraph.text[5:] if paragraph.text[0:4] == '主持人:': host = paragraph.text[4:] if paragraph.text[0:5] == '学习形式:': study_type = paragraph.text[5:] if len(paragraph.text) >= 2: if paragraph.text[0].isdigit() and paragraph.text[1] == '、': content_lst.append(paragraph.text) content = ' '.join(content_lst)完成了解析 Word 文件之后,就需要把内容输出的 Excel 文件中了。 简单来说,就是将上面代码获取到的几个元素组合成一个列表,通过 sheet.append(list) 的方法写入 Excel 文件中: number = 0 # 全局中设置一个变量用于计数,做为序号输出 wordfile = Document(path + r'\Notice\会议通知 1.docx') content_lst = [] for paragraph in wordfile.paragraphs: if paragraph.text[0:5] == '学习时间:': study_time = paragraph.text[5:] if paragraph.text[0:4] == '主持人:': host = paragraph.text[4:] if paragraph.text[0:5] == '学习形式:': study_type = paragraph.text[5:] if len(paragraph.text) >= 2: if paragraph.text[0].isdigit() and paragraph.text[1] == '、': content_lst.append(paragraph.text) content = ' '.join(content_lst) number += 1 sheet.append([number, study_time, content, study_type, host])单个文件解析完,用 glob 改完获取文件夹下全部文件,建立循环逐个解析就能完成本需求,当然最后记得保存 Excel 文件。 完整代码如下👇 from docx import Document from openpyxl import load_workbook import glob path = r'C:\Users\xxx' workbook = load_workbook(path + r'\Meeting_temp.xlsx') sheet = workbook.active number = 0 for file in glob.glob(path + r'\Notice\*.docx'): wordfile = Document(file) content_lst = [] for paragraph in wordfile.paragraphs: if paragraph.text[0:5] == '学习时间:': study_time = paragraph.text[5:] if paragraph.text[0:4] == '主持人:': host = paragraph.text[4:] if paragraph.text[0:5] == '学习形式:': study_type = paragraph.text[5:] if len(paragraph.text) >= 2: if paragraph.text[0].isdigit() and paragraph.text[1] == '、': content_lst.append(paragraph.text) content = ' '.join(content_lst) number += 1 sheet.append([number, study_time, content, study_type, host]) workbook.save(path + r'\Meeting_notice.xlsx')
核心也不过三十行代码,总共不过三秒就搞定了! |




【本文地址】