| 跳出抽象名词的泥潭, 揭密 Windows 上的各种 locale | 您所在的位置:网站首页 › window10分几个区比较好 › 跳出抽象名词的泥潭, 揭密 Windows 上的各种 locale |
跳出抽象名词的泥潭, 揭密 Windows 上的各种 locale
|
背景知识 [20221017.1] Locale 是什么? 按词典的解释,是“(事情发生的)地点,现场”。这个词显得比较抽象,日常生活中比较少用,英语日常表达中,常用的是 location、place、area 这些比较形象的词。 [20221017.2] 正因为 locale 平常比较少用,它就被计算机软件行业借用了。这是好事,因为当我们跟别人提及 locale 时,别人立即就能意识到,这个是专有名词,是电脑上用的词,是跟操作系统的某个设置有关的东西。恰好,操作系统用 locale 这个词表示的东西也是比较抽象的,一个具体的 locale,背后关联着一大把的数据(属性),并没有一个现实中的贴切词汇来整体表达那一大把的属性,那就拿 locale 充当这个角色好了。 [20221017.3] Windows 的 locale 表现在哪里? 在英文版的 Windows 10, 21H2 中,敲 intl.cpl 打开传统控制面板的 locale 设置 UI,可以看到 “system locale” 这样的提法。而在中文版 Windows 里头,locale 被翻译为“区域设置”。我觉得翻译为“地域设置”会更好。但微软从 Windows 2000 起就是那么翻译的,然后他们就不改了。 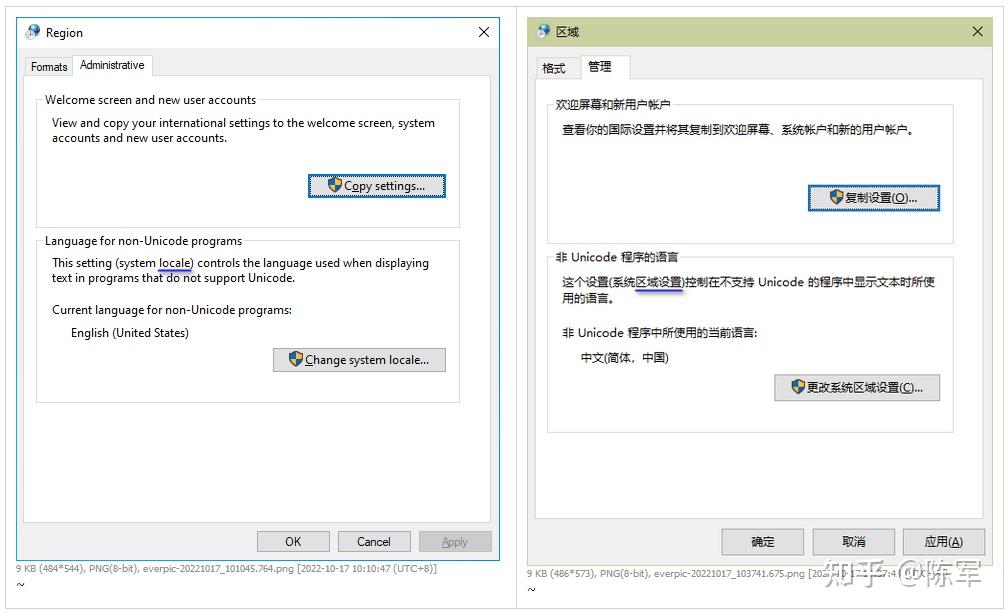 控制面板,选择 system-locale 控制面板,选择 system-locale[20221017.4] 区域设置,会对系统产生哪些影响?问得更具体一点,将 locale 设为“English (United States)” 跟设为“中文(简体,中国)”,有何不同的效果? 我拿六个不同 locale “特征”举例,你看看它们有何不同。 特征英语(美国)英语(英国)德语(德国)中文(简体,中国)短日期格式,比如要表达 2022 年 9 月 17 日9/17/202217/09/202217.09.20222022/9/17长日期格式Saturday, September 17, 202217 September 2022Samstag, 17. September 20222022年9月17日长时间格式,比如要表达 上午 9 点 17 分 3 秒9:17:03 AM09:17:0309:17:039:17:03带千分号的数值表达123,456,789.00123,456,789.00123.456.789,00123,456,789.00货币符号$£€¥负值的货币数量($1.1)-£1.1-1,1 €¥-1.1[20221017.5] 可以看出,用户通过选用不同的 locale(本质上是选取一对“语言+国家”的组合),操作系统就能够用该 locale 对应的本地习俗来表达日期、时间、货币。比如,Windows 文件管理器中显示文件的修改时间,就是根据你当前的 locale 设定来表达的。 [20221017.6] 当然,如果你对某种 locale 对应的默认格式不喜欢,Windows 是允许你自定义格式的,比如,在 locale 设定为“中文(简体,中国)”的情况下,你可以要求 Windows 将短日期显示为 2022-09-17 ,而非默认的 2022/9/17 。 [20221017.7] 对于 locale 背后关联的信息,微软后来也把它们叫作 culture info,这个提法看起来更形象了。一个 locale 里头包含的特征,并不只上头列出的那些,全部列出来太冗长了。你可以自己在 Windows 控制面板里头探索。 [20221017.7a] 微软还提供一个小软件,叫 Locale Builder 2.0,你可以用它来创建自己独特的 locale(独特的 culture info 组合),添加到 user-locale 列表中。 [20221017.8] 说到这里要停一停,Windows UI 给用户呈现的 locale 设定其实有两组,一组叫 system-locale,20221017.3 的那两张图展示的就是 system-locale 的设定。然而,上头列出的日期、时间、货币特征,则是由另一组 locale(称 user-locale)来决定的。 User-locale 的设定,在 intl.cpl 的另一个画面,如下图: 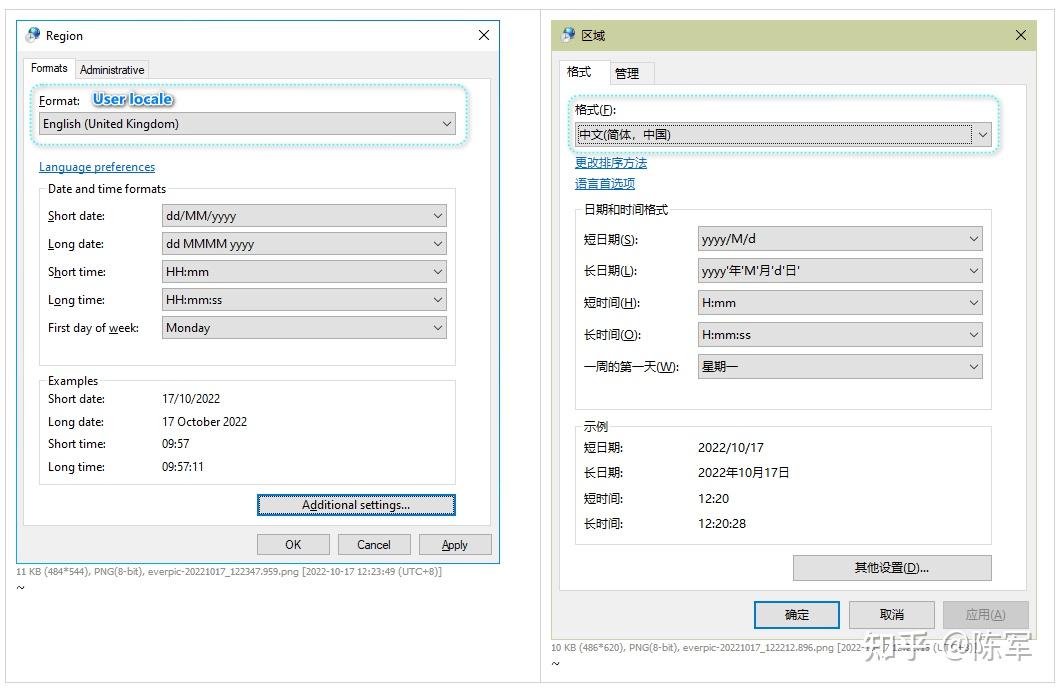 控制面板,选择 user-locale 控制面板,选择 user-locale [20221017.9] 虽然控制面板的 UI 上没有出现“user-locale”的字眼,但从 Windows API 的角度看,这里设定的就是 user-locale。也许是微软觉得 locale 这个提法对普通用户太晦涩,因此从 Windows XP 起就隐去了 locale 字眼。在 Windows 2000 时,该字眼还是存在的。 不妨看一眼 Win2000 和 WinXP 设置 user-locale 的 UI 是怎样的。 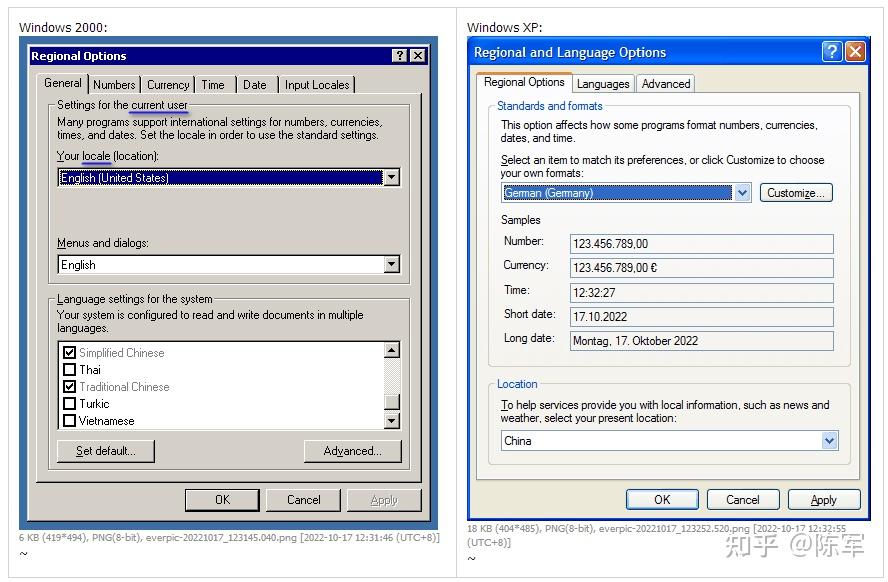 [20221017.9a] 我们稍后用程序来展示,system-locale 和 user-locale 这两者的具体设定值是互相独立的,并无从属关系,但,它们的取值集合是相同的。比如,system-locale 可以在 en-US, en-GB, de-DE, zh-CN ... 这些值中选取,user-locale 同样也是在这些值中选取的。 [20221017.10] 你要问我把 system-locale 和 user-locale 设成不一样的值,那会怎么样呢?答案是没问题,它们管的东西(影响的东西)不同。微软的规则很明晰: system-locale 管的是系统的默认代码页(codepage)。user-locale 管的是时间、日期、货币的表达格式。[20221017.11] 现在说 codepage 是什么东西。 所谓的 codepage,就是把一串字节流转换为 Unicode 字符流的转换表(包括正反两个方向的转换)。这些转换表是用业界规定好的一组数值来指代的。举例说, 如果你安装一份简体中文版的 Win7,那么,默认的 system-locale 被设为“中文(简体,中国)”,此 locale 背后关联的 codepage 号码(可简称之 system-codepage)是 936 。Codepage 936 还有一个通俗名称叫 GBK 。如果你打开 Windows 自带的 notepad,敲入“电脑”两个字,保存成 gbk-diannao.txt ,那么,“电脑”两个字就会按 codepage 936 来转换成字节流(或说,encode 成字节流),得到的字节流是四个字节 [B5 E7 C4 D4]。如果你安装一份繁体中文版的 Win7,那么,默认的 system-locale 被设为“中文(繁体,台湾)”,此 locale 背后关联的 codepage 号码是 950。Codepage 950 还有一个近似名称叫 Big5 。如果你将刚才的 gbk-diannao.txt 拷贝到这台繁体中文版的 Windows 上,用记事本打开,会发现记事本将里头的两个字显示为“萇齟”,因为 [B5 E7 C4 D4] 按照 Big5 来解读(或说,将字节流 decode 成 Unicode 字符流),就是那两个怪字。[20221017.11a] 为什么刚才的实验用 Win7 而非 Win10? 因为在 Win10.21H2 上, notepad 的行为有所改变,无法体现出 system-codepage 的作用。Win10 的 notepad 在保存具有 non-ASCII 字符的内容时,不再根据当前的 system-codepage 来保存,而是按 UTF-8 编码来保存,假设存为 u8-diannao.txt ,这回是 6 个字节 [E7 94 B5 E8 84 91] 。 [20221017.11b] 将 u8-diannao.txt 拷贝到繁体中文 Win10.21H2 上,让记事本打开之,这回“电脑”是被正常显示的,因为 Win10 会试图优先用 UTF-8 来解码文件内容,解码成功(未发现不符合 UTF-8 编码规则的字节序列),因此“电脑”就被成功还原了。只有在 UTF-8 解码失败的情况下,才尝试用 system-codepage 来解码,比如将刚才的 gbk-diannao.txt 拷贝到繁体中文 Win10 上,是可以重现怪字的。 [20221017.11c] 事实是:对于 [E7 94 B5 E8 84 91] 这六个字节构成的文件来说,解读者无法准确判定当初生成此文件的作者期望用这六个字节来表达哪几个 Unicode 字符,因为它既是一串有效的 UTF8 字节流,也是一串有效的 GBK 字节流。有效的意思是,这些字节序列没有违反编码规则。 [E7 94 B5 E8 84 91] 按 UTF8 来解读,是“电脑”。 [E7 94 B5 E8 84 91] 按 GBK 来解读,是“鐢佃剳”——虽然是无意义的文字,但它们是符合 GBK 编码规则的。[20221017.11e] Codepage 950 跟 Big5 其实有细微差别,多出了七个汉字和少量线框字符,但本文的内容不会撞到这些差别,可以忽略之。 [20221017.12] System-codepage 可以被设为 UTF8 吗? 自 Windows 2000 出现之后的很长一段时间,UTF8 是没有办法作为 system-codepage 的。微软在 Windows 10 version 1803 时终于允许我们这么做了。如果勾起了 “Beta: Use Unicode UTF-8 for worldwide language support”,那么,system-codepage 就是 UTF8 了,这个 codepage 的数值号码是 65001 。我后面将该选项称作 UTF8ACP 。  Windows 在近些年为什么会有这种转变呢(才有这种转变呢)?必须说这是受了 Unix/Linux 世界的影响。要知道,业界曾经定义过的 codepage(一百来种)并没有涵盖一些少数民族的语言,比如藏语、蒙古语。早些年以前,如果 Windows 程序里头要使用这些冷门语言,微软的建议是用 UTF16-LE 来表达它们,更具体地说,是用 wchar_t 数组来存储它们,然后呢,调用宽字符的 Windows API 来显示它们。但是 Linux 世界可不吃微软这一套,他们在更早些年就倾向于用 UTF8 来表达 Unicode 字符串,包括在内存中表达以及在文件中表达。随着开源世界越来越兴旺,微软不得不试着向 UTF8 的趋势妥协,因此加入了 UTF8ACP 选项。 [20221017.12a] 不过,到 Win10.22H2 时,UTF8ACP 的功能仍很孱弱,只能说还停留在半成品阶段。详情见文后 [20230202.q1] 。 现在开始正题从 20221017.1~20221017.11 这些内容,我好多年前就知晓了,估计很多读者也在心里想“这些我早就知道了,有什么新鲜的吗”? [20221017.12] 但事实没那么简单。前几个月,我试图写一个 Python 程序,想捕获 svn.exe 子进程的 STDOUT 输出(svn.exe 由 TortoiseSVN 提供),然而却发现,当 svn 仓库中有中文文件名时,我总是没法可靠地捕获那些中文文件名,要不然字符丢失、要不然中文变问号或是错乱字符。我所说的可靠,指的是不论 Windows 的 system-locale 和 user-locale 被设成什么值,我都应该能够正确捕获中文文件名,如果不能,我需要能够定位到导致字符信息丢失的故障点在哪里。 [20221017.13] 调查几天后——不,后来又断断续续调查了三个月,发现这里头的水可深了。 Windows 里头潜藏的 locale 空间,可不止 system-locale 和 user-locale 这两个,而是多达八个。 每个 locale 空间分别影响了哪些 API,MSDN 并没有给出集中的列表,它们是分散讲述的,需要我自己一点一点总结。MSDN 从来就没有在一篇文章中并排指出那八个 locale 空间的存在(也许我是世界上第一个把它们扒出来的人),因此,MSDN 中 "user locale", "system locale" 这样的字眼有时候是含糊有歧义的,而且常常给我们翻炒各种抽象名词,读者很容易被误导。在某些话题上,MSDN 描述的行为还停留在 Windows NT4 时代,到 Win2000 之后已经属于错误表述了,但二十年来微软一直没有修正,也许他们认为,对于这种古老知识,该懂的人十年前就该懂了,不懂的人也没必要再懂,Win32 的知识只要一小撮搞底层的人懂就够了。VC2010 跟 VC2019 的 MSVCRT 行为有一个重大差别,lc_codepage 默认值的来源不同,VC2010 的默认值来自 user-locale,而 VC2019 的默认值来自 system-locale。我查了 MSDN 2008 和 MSDN 2019,里头讲述的行为跟 VC2019 相符,说明 VC2010 的 CRT 实现是有 bug 的。说明这 bug 存在了非常多年才被修正,也许是在 VC2015 修正的。还有相当一些隐秘行为,MSDN 只字未提。比如,GetThreadLocale() 的内部逻辑,根据 [system-locale 是否为中日韩] 而不同。命令行窗口正确显示 Unicode 字符的问题,很复杂。这个需要另外开一个长篇。要想在 CMD 窗口中正确无误地显示 Unicode 字符,需要通过几道关卡?超乎新手的想象。顺道探索一个问题,要想让一个 CmdApp(命令行程序、控制台程序、或称 CUI)能够显示 ExtUnicode 字符(代码点大于 0xFFFF 的字符),程序该如何写?伴随着系统中的多个 locale 空间,系统中还有多个 codepage 空间,掌握各个 codepage 空间的行为,是诊断命令行程序乱码的关键。此间探明了 wprintf/printf 内部复杂缠绕的各个 encoding/decoding 环节,扫除了一大块盲区。[20221017.14] 接下来的文字,我将深入这些细节,揭示各个 locale 的真面目。为了防止空口无凭,我必须写一组程序来验证我的结论。因此,接下来就是程序员的口吻了,如果你没有 Windows API 编程经验的话,会觉得我不知所云。 全局观很重要[20221025.1] 要理解一个复杂的系统,全局观很重要,在解释 locale 这个事情上,同样不例外。 全局观,可以认为是一个知识体系的框架,各个具体的知识点,依附于这个框架上的各个关键节点而存在。 框架的作用在于: 它让我们能够标识出各个知识点在框架中的层级位置,比如,哪些是涵盖面广的概念,哪些是涵盖面窄的概念。它让我们能够感知到两个不同知识点之间的关系,比如,是并列关系、还是从属关系?反之,若缺乏全局观: 我们往往只能看到复杂事物坍缩后的样貌,无法还原出事物本来的面目,无法找出事件发生的因果关系。容易被假象误导,或是被其他人不完整、有瑕疵、有歧义的陈述误导。全局观:Windows 是如何标识一个 locale 的?[20221026.0] 在 Windows 上,一个 locale 有两种标识方法。这里所谓的“标识”,是“给具体的事物取名”的意思,事物的内容不同,取的名字也应该不同,目的是,用不同的名字将不同内容的事物区分开。 [20221026.1] 第一种,用字符串来标识,MSDN 中称其 "locale name",有时让它看起来更像专有名词,也称之 “Language Tag”,简写为 LangTag。不影响语义的情况下,我会将其写为 langtag 。 [20221026.1a] 比如:en-US 是一个 locale,zh-CN 是另一个 locale。其格式是 “-”,两个要素间用减号字符连接。 [20221026.1b] 注意:此处跟 Linux 的习惯有所不同,Linux 上的 locale 值, 和 之间是下划线。 [20221026.2] 第二种,用一个数值来标识,该数值称 "locale identifier",简写为 LCID。在 Windows API 中大量出现 "LCID" 的身影,比如 LCIDToLocaleName ,LocaleNameToLCID 这两函数提供在两种标识方法间互转的功能,其内部就是简单的查表动作。 [20221026.2a] MSDN 中还很常见的一个词叫 Language-ID,简称 LANGID。不影响语义的情况下,我也会用全小写字母 langid 来表达它,用全小写的话,暗示 langid 不是当前句子的重点。LCID 是 32-bit value, LANGID 是 LCID 的 low 16-bit 。在绝大多数情况下,LCID 和 LANGID 是等值的,除非需要特别指出排序规则(比如中文字符串按拼音排序、还是按笔划排序),才需要用将 high 16-bit 设成非零的值。 [20221026.2b] MSDN 的 LCID 解释: https://docs.microsoft.com/en-us/windows/win32/intl/locale-identifiers [20221026.3] LangTag 表示法,在 Windows Vista 时才被支持;Windows XP 只能用 LCID 的表示法,LCID 的历史很久远,可能从 Windows NT 3.5 开始就有了。 [20221026.4] 一些 locale 取值举例: locale 标识符 (locale name)语言(ISO-639)国家名(或地区名)(ISO-3166)对应的 LCID 数值en-USEnglish, 英语United States, 美国0x0409en-GBEnglish, 英语United Kingdom(=Great Britain), 英国0x0809en-CAEnglish, 英语Canada, 加拿大0x1009zh-CNChinese, 中文China, 中国0x0804zh-TWChinese, 中文Taiwan, 台湾0x0404fr-FRFrench, 法语France, 法国0x040Cfr-CAFrench, 法语Canada, 加拿大0x0C0Cmni-INManipuri, 曼尼普尔语. 是3个字母.India, 印度0x0458[20221026.5] 以上信息可以用我的 EnumLocales 程序来验证,见 EnumLocales 列出系统支持的所有 locales 。 [20221026.6] Windows 上的 MSVCRT 函数(比如 setlocale )表达 locale 时,微软其实还定义了另外两种格式。这两种格式虽然现在还能用,但被认为已经过时了,因为 Vista 起引入的 - 的标识法显然更简洁,而且后者还是 ISO 国际标准。 两种老式标识法举例: cht_JPN.936Chinese (Traditional)_Japan.936控制面板中列出的 user-locales,跟 EnumLocales 所列出的 locales,是一样的吗?[20221026.7] 本文前头指出,控制面板中有两处 locales 列表供我们选择,一处是 system-locale 列表(20221017.3),另一处是 user-locale 列表(20221017.8)。 [20221026.7a] 经验证,user-locale 列表跟 Windows API EnumSystemLocalesEx , dwFlags=LOCALE_SPECIFICDATA 时枚举出来的列表是一样的。MSDN 虽然没提 LOCALE_SPECIFICDATA 这个宏,但它确实存在且有意义,它就在 winnls.h 里头, LOCALE_WINDOWS 的旁边。  [20221026.7b] 经实验,LOCALE_WINDOWS 枚举出的条目,等于 LOCALE_SPECIFICDATA 跟 LOCALE_NEUTRALDATA 的总和。 [20221026.8] 追问:控制面板中,system-locale 的列表是怎样的呢?跟 user-locale 列表一样吗? 答案是不一样。Win10.21H2 上, system-locale 有 258 条。user-locale 多了一些,总共 574 个条目。User-locale 多出的条目有这些: Chinese (Simplified Han, Hong Kong SAR)Chinese (Simplified Han, Macao SAR)Portuguese (Macao SAR)English (Germany)English (Denmark)English (Sweden)...[20230127.1] 我们可以自行编程来分别列出 system-locales 和 user-locales 。EnumLocales 程序可演示之。执行以下两个命令可获知: EnumLocales B 3 ,得到的就是 intl.cpl 中的 system-locale 的列表。EnumLocales B 4 ,得到的就是 intl.cpl 中的 user-locale 的列表。运行效果见:展示 Windows 控制面板中 user-locales 各条目对应的 LangTag [20230127.1a] user-locale 列表和 system-locale 列表有什么关系? system-locale 列表,是拥有具体 LCID 数值的那些 locale,包含了日常常见的 - 条目,比如 en-US (LCID=0x0409), zh-CN (LCID=0x0804) 等。user-locale 列表多出的那些条目,是一些不常见、或近几年刚冒出的 - ,比如,zh-Hans-HK (语言是简体中文,但地区设成香港), ru-UA (语言是俄语,但地区设成乌克兰)。对于这些组合,微软还没决定给它们安排专门的 LCID 值,因此它们暂时以 custom locale 形式存在的,好比是用户外挂上去的。[20230127.2] 为什么微软要设计 system-locale 和 user-locale 这两套东西出来呢?不是徒增用户的认知负担吗? 我意思是,如果微软把 user-locale 和 system-locale 那两个设置合并掉,只给用户呈现 user-locale 那 574 条选择,行不行呢?没错,Windows UI 上非要这么设计也行,不过微软目前仍然决定将它们分开,因为它们影响的是系统不同方面的行为。 system-locale 影响的是所谓的 system-codepage,即,WinAPI 将 ANSI 字符串和 Unicode 字符串互相转化时,默认用的是哪个 codepage。user-locale 影响的则是 culture info,日期格式、、货币符号等。[20230127.2a] 换言之,你将 system-locale 和 user-locale 设成不同的值也不要紧,它们各自影响的东西互不交叉。 [20230127.2b] Linux 和 macOS 上,就只有 user-locale 这套东西。它们不需要 system-locale 了,因为近十几年来,它们已经内定将 UTF8 作为 system-codepage 了。 歧义辨析:当有人说一个 locale 时,他说的到底是什么?[20230127.3] 在继续往下讲之前,我得停一停,我得拷问一下 locale 这个词所有的含义。前几个月我在 MSDN 中开始仔细检阅 locale 相关的信息,起初看得我火冒三丈,一段话常常讲得又抽象又含糊,讲得那叫什么狗屁,为什么跟我已经有的实践经验老是对不上呢? [20230127.3a] 怎么办呢?我只好硬着头皮写了一大摞测试代码,把各个相关 API 的行为都给探查一遍,渐渐才把各个细节的来龙去脉搞懂了。前面提及的 EnumLocales 就是这轮调查中编写的。后头陆续还会有其他演示程序登场。 [20230127.3b] MSDN 有时候就是有这个毛病,当下提及的抽象名词只适合于当下这个主题,你要是把其他主题的相同名词套到这个主题上来用,那就踩坑了。至于当前主题跟其他主题的边界在哪里,得靠更高一个层次的视角来解释,而这种具有更高层次视角的文字尤其的少,往往得靠自己去总结。我这篇长文就是试图站在更高层次来解释 locale 这个概念。当然,要讲清楚的话,是相当费唇舌的,而且还得配合实际程序来验证之。 [20230127.4] 当我们看到一个表述,“修改一个 locale”、“新加一个 locale”,它到底是修改什么?添加什么?如果没有搞清楚,后续文字立马卡壳。 [20230127.5] 根据我的总结,locale 这个词其实有三层含义,或说三个角度。 [20230127.5a] 第一层,指的是 locale 的“使用场合”。前面已经提及,system-locale 和 user-locale 就是两个不同的使用场合。 [20230127.5b] 第二层,指的是 locale 的取值,比如,en-US 是一个取值,zh-CN 是另一个取值,前面已告知,Win10.21H2 上,有效的取值共 574 种。 [20230127.5b.1] 为了简洁,我也将“使用场合”称作“空间”。每一个 locale 空间,都可以独立选取自己的 locale 取值。如果系统中存在两个 locale 空间,那么在同一时间我们就能看到系统中有两个独立的 locale 取值。 后面会讲到,Windows 上的 locale 空间数目,不是两个,而是多达八个!明白哪个 API 是作用于哪个空间的,是正确理解 API 语义的关键。 [20230127.5c] 第三层,一个具体 locale 取值里头的内容。此时,我们将一个 locale 值想象成是一个容器,那么: 拿 en-US 这个取值来说,里头的内容是:ANSI-codepage=1252, 货币符号是 '$',短日期格式是 M/d/YYYY,一个星期的第一天叫 “Sunday”。拿 zh-CN 这个取值来说,里头的内容变成:ANSI-codepage=936,货币符号是 '¥',短日期格式是 Year/M/d,一个星期的第一天叫 “星期日”。[20230127.5d] 有了这套概念框架后,我他妈才真的开窍了,现在 MSDN 的任何一处出现 locale 字眼,我都能找出它所传达的信息处在这个框架中的哪个位置。这才叫把事情搞明白了,再也不受抽象词汇蒙蔽了! [20230127.5e] 举例: 前文出现多次的 “user-locale 列表”,指的是系统支持的所有可用 locale 取值的列表。如果一个管理员说,我需要一张该系统上所有用户的 user-locale 取值列表。那么,他要的其实是空间列表。比如,表格第一项,Bob 将 user-locale 设为 en-US,第二项,Tom 将 user-locale 设为 en-GB,Kate 也将 user-locale 设为 en-GB ...[20230127.5f] 有了 locale 概念框架之后,我就可以一步一步将 locale 的所有细节解释清楚了。 全局观:八个 locale 空间[20230127.6] 八个 locale 空间,意味着我们在同一时间能够看到系统上有八个不同的 locale 取值。 [20230127.6a] 下面画出它们的分类和关系图:  Windows 上的八个 locale 空间 Windows 上的八个 locale 空间[20230127.6b] 空口无凭,我有实打实的程序给你展示: DefaultLocales 程序,展示 Windows 上八个不同的 locale 空间  [20230127.7] 整体关系 八个 locale 空间的取值,各自有自己的一份拷贝,并不存在任何的 overlay 关系。#1, #2, #4, #5 对于当前登录用户来说,是全局设置;#3, #6, #7, #8 是每个线程各自的设置。特别提示 system-locale 和 user-locale 的关系,不要望文生义觉得后者是用来 override 前者的,它们实际上是并列的,各自的作用角度不同(见 20230128.4)。[20230127.7a] 图中的 #1, #2, #3, MSDN 对它们的称呼是 LANGID (language id 的意思),并非叫 LCID(locale id),但,我们看一下 LCID 和 LANGID 的格式关系就知道, LANGID 就是 LCID 的低 16 位。  LCID & LANGID 的关系 LCID & LANGID 的关系当表示用户界面语言时,根本用不着 SortID 那个信息,你可用将 LANGID 当作 LCID 来看待。你完全可以将 GetSystemDefaultUILanguage(), GetUserDefaultUILanguage(), GetThreadUILanguage() 的返回值传给 LCIDToLocaleName() 来得到一个 LangTag。因此,我将 LANGID 的三个不同使用场合也分别称作是 locale 空间。 [20230127.7b] locale-name 和 LANGID 字段的对应关系。以 zh-CN 为例,zh 对应的其实是 10 bit primary language,CN 对应的其实是国家/地区名字。没错,与其说那 6 bit 是 Sub-language,不如说它用来表示 country/region 。 zh-CN 中的 CN 是 China,en-US 中的 US 是 United-States。 另外两点提示: zh 表示汉语、CN 表示中国大陆,这种表达方法是 ISO-639 和 ISO-3166 国际标准,但,将 zh-CN 对应到 LANGID 数值的规则,则是微软自行定义的。6-bit 的 country code,只能表达 64 个数值,而整个地球上国家有 200 个左右,显然做不到一个国家独占一个数值。微软的做法是:Sub-language 的具体含义要根据 Primary-language 的值来确定。比如:LANGID=0x0804, Primary-language=4(zh),此时 Sub-language=2 表示中国大陆。LANGID=0x080C, Primary-language=12(fr),此时 Sub-language=2 表示比利时。[20230127.7c] #7 指的是 "Input LANGID" ,更具体地说,指 GetKeyboardLayout(0) 返回值的低 16 位。跟 20230127.7a 同理,我们也可以将这 16 位值看作是一个 LCID,或者说,Input LANGID(简写成 inputlang) 被我看成是一个 Locale 空间。 [20230127.7d] GetKeyboardLayout 的返回值是 32 位,微软称这个 32-bit value 叫“input locale identifier”,但别被这个叫法迷惑了。“input locale identifier” 并不是 LCID 值(不是一个 locale 空间),因为它的高 16位表示 “physical layout of the keyboard”,而非 LCID 中的 SortID。 为了 100% 防止你误解,我重述一遍:GetKeyboardLayout 返回的 32-bit value 不是一个 locale 空间,它的 lower 16-bit value 才是一个 locale 空间。 [20230127.7e] #1~#7 全部是 Windows API 层面的东西,而 #8 是 MSVCRT (Visual C++ runtime library)层面的。 [20230127.7f] #8 其实是没有 LCID 的,或说,没有数值型的 locale 表达。有跨平台 C/C++ 编程经验的老手应该知道,MSVCRT 是在 WinAPI 之上进行的一层封装,用于提供跟 ANSI C 基本兼容的一套 API,比如 printf, strlen 之类。 这个 MSVCRT 库,微软一直有提供源代码供我们调试(在 Visual Studio 安装包里头)。 [20230127.7g] MSVCRT 里头有它自己专门的一套 locales 内容(简称 CRT-locale),包括名曰 lc_codepage 和 mb_codepage 的两个 codepage(它们的默认值会受 system-locale 设定值的影响),以及它自己的一套 culture info 描述格式(比 WinAPI 层面的 locale 内容简化很多)。 [20230127.7h] CRT-locale 的取值如何影响应用程序的行为,特别是 printf 和 wprintf 的行为,又是个超大的话题。得找时间另开一篇讲解。 [20230127.8] 专门提一下 #6. SetThreadLocale 和 GetThreadLocale 这两个函数的作用, 自 Win7 起已经被彻底废弃了. 虽然我们 set 进去的 LCID 值是可以被原原本本地 get 出来的, 但它们已经几乎不影响其他 Windows API 的行为了. 我推测它们的作用发生在 WinNT4 时代, 用于影响用户从 .rc 中挑选哪种 LANGUAGE 的资源, 但后来微软觉得不妥, 用 SetThreadUILanguage 和 GetThreadUILanguage 代替了它们的作用. [20230127.8a] 但让人遗憾的是, MSDN 至今还星星点点散布着很多页面存在过时的表述, 让人误以为 GetThreadLocale 还在发挥作用. [20230127.8b] 比如, FormatMessage 的 dwLanguageId 参数是这么解释的: 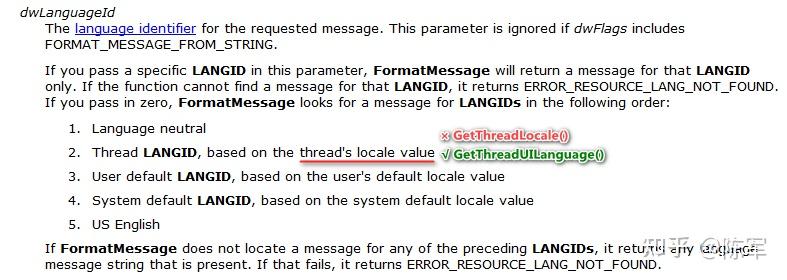 ——第 2 步用词 "thread's locale value", 会让人误以为是 GetThreadLocale() 的返回值, 但这可能是 WinNT4 时代的行为. 从 WinXP 起很可能就已经不是这样了. 我已经验证, 从 Win7 起, 第 2 步表述为 GetThreadUILanguage() 是正确的. 全局观:locale 容器中有哪些内容?[20230128.1] 计算机这门学问就是这样,任何的信息在到达我们的眼睛之前,都只是抽象的概念,同时,这些概念又是有层次的,一个大的概念里头套着多个小的概念,小的概念里头又套着更小的概念。我们把一个概念想象成一个容器,那么它就是一个大容器套着多个小容器,每个小容器又套着多个更小的容器这样的多元多层嵌套结构。你说人为什么要设计这么繁琐的层层嵌套结构呢?这是为了灵活。意思是,当我们需要之前还没有的一样新东西时,往往可以从已有的这些层次中挑选一些出来、重新组合后就能得到那样新东西,而不必从头开始设计每一样细节。 [20230128.1a] 我在 20230127.5 提及的 locale 的三层含义,广义上可以认为它们是依次嵌套的三个概念容器。只不过,为了在这篇文章中为了指代方便,我给这三个层次分别起了 “空间、取值、内容” 这三个名字。有了这三个词来标定上下文,读者就可以知道,我当下正在说的容器,所指到底是哪个层次了。 [20230128.2] 本节,我们要考察的是“取值”这个容器里头有什么。具体地说,当某个场合我们要用到 zh-CN 这个 locale 值的时候,我们要用的到底是 zh-CN 这个概念容器里头的什么东西呢? [20230128.2a] 微软的设计是这样的:不论一个 locale 值是 en-US 还是 zh-CN,这个 locale 值(想象它是个容器)里头的信息结构是一样的。 如果你写过 C/C++ 程序,我就可以说,不同 locale 里头的内容是由同一个 struct 结构体定义实例化出来的。对于外行,我会举例说明。A 小学和 B 小学的信息结构是一样的,里头都有教学楼、有操场、有老师、有划分班级;但一个小学跟一个银行的信息结构就大不相同了,银行里有取款机和柜员,但小学里没有。[20230128.2b] 在 WinAPI 这个层面,一个 locale 里头含有相当多特征,用 GetLocaleInfo 可以获取那些特征。传入一个 LCID 和一个特征索引值,即可得到一项内容。 [20230128.2c] 列出一些典型的: 索引值含义en-US 里头的值zh-CN 里头的值el-GR(希腊语@希腊)LOCALE_IDEFAULTANSICODEPAGEANSI-codepage12529361253LOCALE_IDEFAULTCODEPAGEOEM-codepage437936737LOCALE_SINTLSYMBOL三字母货币符号USDCNYEURLOCALE_SCURRENCY货币符号的本国表达$¥€LOCALE_SDAYNAME1星期一怎么写Monday星期一ΔευτέραLOCALE_SSHORTDATE短日期格式M/d/yyyyyyyy/M/dd/M/yyyy[20230128.2d] 使用面向对象编程的术语,你可以将 LOCALE_IDEFAULTANSICODEPAGE 这把符号所指代的东西认为是 locale 的一个属性。 MSDN 没有给此处的“属性”起一个好的泛称,只是称它们 locale information (出自 GetLocaleInfo 2023.01)。什么叫 "information"?你这跟没起名也没什么两样嘛。因此,我自己决定,把这些“属性”叫作“特征(trait)”。 [20230128.3] 要点:给定一个具体的 locale-name,它背后关联的各个特征值是微软内定好的了。比如,你在任何一台 Windows 上用 GetLocaleInfo 来查 el-GR 的 LOCALE_IDEFAULTANSICODEPAGE , 得到的结果必定是 1253,跟这台 Windows 上的用户用户将那八个 locale 空间设定什么值无关。 [20230128.3a] 何谓 system-codepage(系统代码页)?之前已经多次出现该词。现在我们知道,它的准确含义是: system-locale 的取值所对应的 ANSI-codepage。 [20230128.3b] 我们看到,一个 locale 其实关联着两个 codepage,一个叫 ANSI-codepage,另一个叫 OEM-codepage 。 [20230128.3c] Codepage 是 ANSI↔Unicode 之间的字符编码转换表。按照微软的设计意图: ANSI-codepage 用在 GUI 程序上(图形界面程序)。OEM-codepage 用在命令行程序上(也称 CUI 程序,C 表示 console)。[20230128.3d] 比如,我们写一个 16 字节的 b80.txt,十六进制表达如下: 80 81 82 83 84 85 86 87 88 89 8A 8B 8C 8D 8E 8F然后呢,在一台 system-locale 被设为 el-GR(希腊语-希腊) 的 Win7 上,分别在 Notepad 和 CMD 窗口中查看它们,会看到不同的字符。  原因是,Notepad 用 Codepage 1253 来解释字节流,而 CMD 内部用 Codepage 737 来解释字节流。 [20230128.3e] 为什么会有这种撕裂设计呢?是历史原因造成的。所谓的 OEM-codepages,指的是 DOS 时代 IBM 定义的那一套 codepages,后来微软开发了 Windows ,就觉得 IBM 那套代码页定得不合理,太多、太杂,给欧洲这些国家定了十五六个代码页。微软把画线框的那些字符位腾开,重新排列其他字符,整合成了 1250~1257 这八个代码页,让 Windows GUI 程序使用,称它们为 ANSI codepages。新搞出的这八个代码页跟原先的 OEM codepages 是不兼容的,但又不能废弃掉,因为还有很多 DOS 时代的程序还要在 Windows 里头运行呢?因此,微软就做了个决定,让电脑用户指定一个 system-locale ,这相当于同时指定了一个 ANSI-codepage 和一个 OEM-codepage,当然这个 ANSI-codepage 和 OEM-codepage 不是乱搭配的,其中的 OEM-codepage 被安排成那个 locale 地区的人在早些年使用 DOS 电脑时所用的代码页。这样一来,早期的 DOS 程序在 Windows 上显示的字符就跟真正 DOS 环境中显示的一致了。 [20230128.4] 仔细端详 #1~#7 这七个使用场景,会发现这里边似乎有一些冗余设计。 #1~#3 这三个 uilang,它们只用到了 locale 取值自身,没有用到 locale 取值里头关联的内容。#4 和 #7,它们只用到了 locale 里头的 codepage 信息。意思是说,如果用户要给自己的电脑指定一个默认的 ANSI-codepage (即 system-codepage),那么他不是直接指定 codepage 值,而是要挑选一个 ANSI-codepage 匹配自己需求的 system-locale 。#5 用的则是 codepage 之外的其他信息,同样,用户也不是直接指定日期格式、货币格式之类,而是指定一个匹配自己需求的 user-locale 。[20230128.4a] 上头这种设计是否合理呢? 我觉得还是挺合理的,因为一个 locale 的“名字”是面向用户的简洁表达,一个普通用户不太可能需要很复杂的 locale 内容组合,普通用户只需告诉系统,自己使用的语言和所在的国家,大部分设置就已经到位了。 [20230128.4b] 当然,像 en-US, zh-CN 这样的取值代号对于普通用户还是太陌生了,Windows UI 将其翻译成自然语言呈现给用户也是对的。不过呢,对于我这样希望对系统有尽可能多掌控感的用户,我真希望 Windows 能提供一种(高级显示模式),在不伤害系统易用性的同时,将系统内部的实质信息也展露出来,比如,在控制面板中显示 locales 列表时,在“语言-国家”的后头,将它的 LangTag 也给标出来。 Windows 的 locale 空间是否过于繁多?能否简化?[20230128.5] 八个 locale 空间,显然是太多了。就算除掉从 WinXP 起已经废除了实际意义的 #6,仍然有七个 locale 空间会影响应用程序的行为。 [20230128.5a] 不妨对比一下其他的桌面 OS 是如何做的。比如,我找了一台 macOS 12.4 Monterey (2021 发布的 OS 版本) 来进行对比。  (上方为大图,需要单独开窗看才看得到细节) (上方为大图,需要单独开窗看才看得到细节)[20230128.5b] 我观察得到的结论是: #1, 不知有没有,但这显然不重要,因为 #1 总是会被 #2 override 掉的。#2, 选择 OS 的用户界面的语言。#3 的形态表现为:用户可以为指定的 App 设定专门的用户界面语言,以此 override 掉 #2 的设定。#4, 不存在, 估计是对文本流强制使用 UTF8 了。#5, 让用户选取一个国家/地区,来预设一组默认的 culture info。#K, 允许用户指定默认的键盘布局(含输入法)。这跟 Windows 的 #7 有点像,但我相信它们有重大区别,macOS 这里选取的键盘布局,应该是不携带任何 codepage 信息的(只是单纯的键盘布局),因为 macOS 内部已经强制用 UTF8 作为 codepage 了。#8, 这个没有体现在 Language & Region 设置区。另外,我不确定 macOS 是否像 Windows 那样,OS API 层和 ANSI C Runtime 层各自有一份 locale 内容。总结起来,macOS 的优点是: 将 codepage 这个元素简化掉了(消除 #4)。将 language 的概念和 Country/Region 的概念清晰地分离。[20230128.5c] 这么看来,能简化的东西不是太多。很多时候,灵活性和复杂性是相伴的。 全局观:WinAPI 的 Charset 是什么东西?[20230131.0] 一些 WinAPI 里头会见到名叫 Charset 的东西,它跟 locale 有何关系? [20230131.1] Charset 是个很古老的概念,也许 Windows 1.0 (1985) 起它就存在了,Charset 比 locale 和 codepage 的概念出现得更早,Windows 用 Charset 来表达“字符集合 ”的概念。比如,西欧一干国家用的字符,形成一个 Charset,东欧一干国家用的字符,形成另一个 CharSet,所有的 GBK 汉字也形成一个 Charset。在 Windows 早期,字体文件(.ttf) 通常是根据 Charset 来划分的,一个字体文件(对应一个 fontface)内部会提供一个或几个 Charset 中所有字符的字模(glyph),而不会仅仅提供半个 Charset 的字模。 [20230131.2] Charset 在 Windows API 中目前依然存在,主要出现在跟字体相关的 API 中,当然,那些 API 也是从 Windows 1.0 流传至今的。比如 CreateFont 的 iCharSet 参数(以前也叫 fdwCharSet)用于指示一个 Charset ,用户传入的 iCharSet 将使得 CreateFont 创建出不同 fontface 的字体对象(如果用户不明确指定 fontface 的话)。 比如: iCharset=134, 创建出的字体之 fontface 是 宋体(SimSun)。iCharset=136, 创建出的字体之 fontface 是 细明体(MingLiu)。[20230131.3] 微软总共就定义了 16 个 Charset 值,并且,今后也不会再定义新值了。 [20230202.4] 先看看这 16 个 Charset 值的简表。 宏名Charset 数值对应的 codepage涵盖的语系/文字种类#1 ANSI_CHARSET01252西欧国家用的字符,包括德语、法语、西班牙语、葡萄牙语、意大利语等。#2 EASTEUROPE_CHARSET2381250东欧国家用的字符,包括捷克语,波兰语,匈牙利语,罗马尼亚语等。#3 RUSSIAN_CHARSET2941251西里尔文字:俄语,保加利亚语等。#4 GREEK_CHARSET1611253希腊语#5 TURKISH_CHARSET1621254土耳其语#6 HEBREW_CHARSET1771255希伯来语#7 ARABIC_CHARSET1781256阿拉伯语,波斯语#8 BALTIC_CHARSET1861257(波罗的海地区)包括爱沙尼亚语,拉脱维亚语,立陶宛语#9 VIETNAMESE_CHARSET1631258越南语#10 THAI_CHARSET222874泰语#11 SHIFTJIS_CHARSET128932日语#12 GB2312_CHARSET134936涵盖 GBK 字符集中的汉字(22000+ 简体中文字和繁体中文字),囊括所有 codepage 950 的字符。#13 HANGUL_CHARSET129949韩语#14 CHINESEBIG5_CHARSET136950台湾和香港用的繁体中文字符集。#15 DEFAULT_CHARSET1-此值并不表示一个具体的 Charset,而是指当前 system-locale 关联的 ANSI-codepage。因此,创建默认字体,应该传 iCharSet=1 给 CreateFont。默认值不是 0 很不妙,很多程序员会误将 0 当作 Charset 的默认值。 #16 OEM_CHARSET255-此值也不表示一个具体的 Charset,而是指当前 system-locale 关联的 OEM-codepage。[20230202.4a] 上表的关键点在于 Charset 和 codepage 的对应关系。 这组对应关系是通过 WinAPI TranslateCharsetInfo 查得的。 Windows 支持的 codepages 列表: https://learn.microsoft.com/en-us/windows/win32/intl/code-page-identifiers [20230202.5] 除了影响 CreateFont 选用不同的字体外,Charset 在 Win95/98 时代更重要的作用是明确稍后传给 DrawText 的 ANSI 字节流用哪个 codepage 对应到真正的字符,同样一个 ANSI 字节流,不同的 Charset 值对应的 Unicode 字符可以是完全不同的。这使得 Win95/98 的应用程序可以在“单一语言”的 non-Unicode Windows 上用传统 Windows API 同时显示多国语言的文字。至少,同时显示西欧各国的文字是没问题的,比如 这篇展示的例子。这相当于在“往屏幕显示文字”功能上,Win98 也具有了一定的 Unicode 功能。 [20230202.5a] 那你说 Win98 能不能借助 Charset 在屏幕上同时显示所有 Unicode 字符呢?比如中文、日文、韩文、希腊语、俄语全上。这个问题有些复杂,我自己目前的结论是: 用指定 Charset 的方法来 CreateFont,还不能做到显示所有 Charset 的字符。比如,英文版的 Win98 即使指定 Charset=134,CreateFont 也无法得到简体中文字体、无法 DrawText 出汉字字符,效果相当于指定 Charset=DEFAULT_CHARSET;简体中文版的 Win98,即使指定 Charset=128,也无法得到韩文字体、无法 DrawText 出韩语字符,效果也相当于指定 Charset=DEFAULT_CHARSET。——这是 Win98 自身的功能限制。从 Win98 时代过来的老用户会质疑,那为什么 IE6 里头就能够显示所有国家的文字呢?用英文版 Win98+IE6 访问中文网站,显示中文字可是完全没问题。嗯,这个问题我还没精力去调查,猜测是 IE6 内部自己编写了一套 Unicode 字体渲染库,而不是调用 DrawText 之类传统的 Windows API。[20230202.6] 别跟 html 的 charset 搞混。 在 html 文件中,我们会写下面这样的语句来给网页指明 text-encoding: 此处的 "charset" 跟 Windows API 的 Charset 取值空间不同。 http-equiv 中的 charset,跟 Windows 的 codepage 则可以认为是同一空间的。 比如,charset="gbk" 跟 Windows 的 codepage 936 是相同的含义。 [20230202.6a] 只不过,Windows 用数值来表达一个 codepage,而 http/html 用一个字符串来表达一个 codepage。 Windows 上用 WinAPI EnumSystemCodePages 可以枚举出所有的 codepages 。Win10.21H2 提供 140 个 codepages。Http/html 定义的 codepages 在 IANA 的网页列出: https://www.iana.org/assignments/character-sets/character-sets.xhtml 。不过,特定的浏览器能够识别哪些 codepages 则因人而异。[20230202.7] Charset 功能的隐退。 [20230202.7a] 在 Windows 早期版本(Win95/98 或更早),如果 CreateFont 时弄错了 Charset 值,就会导致 Windows 内部引用到错误的 .ttf 文件,在 TextOut 时屏幕显示出的字符往往是错误的。到 Win2000 之后,情况逐渐好转,微软用 font-linking 和 font-fallback 的隐秘手段,在某个 .ttf 中不含指定字符时,自动去其他的 .ttf 中寻找。这样一来,Charset 就不再是“字符能否正确显示”的关键了,而只是用来表达字体挑选偏好。 [20230202.7b] 除了 CreateFont 这批古老函数之外,凡是涉及到 ANSI↔Unicode 转换的场合,新函数都会用 codepage 来指示转换表。为什么要做这种转变呢?我想是因为微软当初给 Charset 留的数值空间太小了,就 8-bit,今后转换表种类多了担心排不下、或是排起来太拥挤。因此就换上个名叫 codepage 的新概念,codepage 至少是 16-bit 的,这下就可以重新定义一套对应值了。 Q & A[20230203.q1] Q: 开启 UTF8ACP 后,对系统行为有何影响?目前观察到如下影响: GetACP 和 GetOEMCP 的返回值变成 65001,不再是中文版 Windows 上通常的 936 。MultiByteToWideChar 和 WideCharToMultiByte,指定参数 codepage=0 的话,内部将私用 UTF8 进行 ANSI 和 WCHAR 的互转。涉及到文件名的函数,比如 MSVCRT 的 _open, _remove,以及 WinAPI 的 CreateFileA,FindFirstFileA 等,表达文件名时,文件名 char * 字符串都被认为是 UTF8 编码的。目前不太乐观的是,UTF8ACP 对于 ANSI char 的 GUI 程序并不友好。详见 Win10/Win11 UTF8ACP 对系统行为的影响,目前对 GUI 程序仍不友好 。 演示程序Jimm 陈军/dailytools 用 Visual Studio 2019 打开 win32-locale.sln,编译可得。 我也准备了现成编好的 EXE,存放于如下网址: Jimm 陈军/exebinary (END, 初稿于 2023.02.15) |
【本文地址】