| 75. CSV文件的写入(保姆级教程) | 您所在的位置:网站首页 › vscode怎么打开csb文件 › 75. CSV文件的写入(保姆级教程) |
75. CSV文件的写入(保姆级教程)
|
推荐最保姆的教程!!! 75. CSV文件的写入(保姆级教程) 1. 目标任务 2. 什么是CSV文件 2.1 CSV文件知识 2.2 准备工作 2.3 实操练习1 2.4 实操练习2 2.5 实操练习3 3. os模块文件操作 3.1 准备工作 3.2 os模块知识回顾 3.3 模块导入语法 3.4 os.getcwd()获取当前工作目录 3.5 os.remove()删除指定文件 3.6 os.mkdir()新建目录 4. CSV文件的写入 5. CSV模块知识 6.语法解析 6.1 导入模块 6.2 新建字典 6.3 确定表头 6.4 确定文件的路径 6.5 创建文件对象 6.6 实例化类创建对象 6.7 写入内容 7. 代码总结 1. 目标任务新建【各班级成绩】文件夹; 在该文件夹下新建一个【1班成绩单.csv】文件; 在该文件中写入下面的内容: 成绩 姓名 刘一 100 陈二 90 2. 什么是CSV文件 2.1 CSV文件知识CSV文件和TXT文件一样,一种纯文本文件。 CSV 是 “Comma-Separated Values(逗号分割的值)” 的首字母缩写。 comma [ˈkɒmə]:逗号。 separated[ˈsepəreɪtɪd]:分开的。 values [ˈvæljuːz]:值。 逗号分割的值意思就是用逗号把不同的值进行分割。 CSV文件中的数据是纯文本的形式, 不同行的值(数据)之间,通过英文逗号,进行分割。 CSV文件文件的第一行相当于Excel表格的列名。 CSV文件可以通过记事本打开,也可以通过Excel软件打开。 【CSV文件和Excel表格的区别】 Excel表格的功能很丰富,样式美观;但占据比较多的存储空间,读写的耗时较长。 CSV文件没有样式,读写速度块;相比Excel表格,CSV文件没有最大行。 Python爬虫项目实操中,我们通常用CSV文件和JSON文件来存储解析到的网页数据。 今天我们先学习CSV文件的操作。 下面,我们来手动新建一个CSV文件。 2.2 准备工作在电脑D盘新建一个【75】文件夹,在该文件下进行如下操作。 2.3 实操练习1 新建一个txt记事本,将其重命名为1班成绩单.CSV。 1.新建csv文件
1.新建csv文件
右键点击1班成绩单.CSV文件,打开方式选择【Excel】 打开后,在A1单元格中输入姓名,在B1单元格中输入成绩。 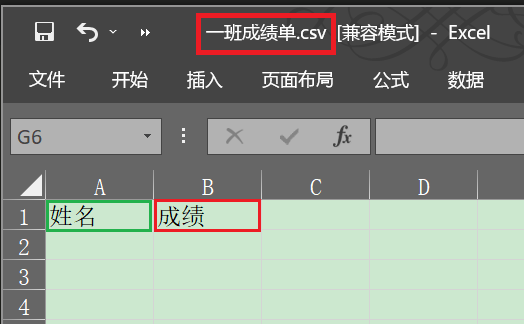 2.输入姓名
2.输入姓名
如果你用Excel打开CSV文件,你会发现其实CSV文件就是一个简易版的Excel。 关闭保存文件。 再次右键点击1班成绩单.CSV文件,打开方式选择【记事本】。 我们发现姓名和成绩之间有一个英文逗号,。 这是因为CSV文件的值是以英文逗号进行分割的。 关闭并保存文件。 2.4 实操练习2以记事本的方式打开1班成绩单.CSV文件 在第二行输入原样输入刘一,,60 注意这里要输入两个英文逗号,不能输入中文逗号。 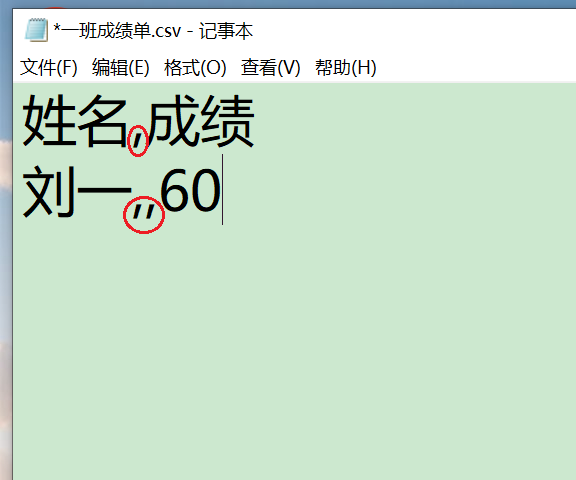 3.2个逗号
3.2个逗号
关闭保存文件。 右键点击1班成绩单.CSV文件,打开方式选择【Excel】 我们发现刘一和60之间多了一个空格。 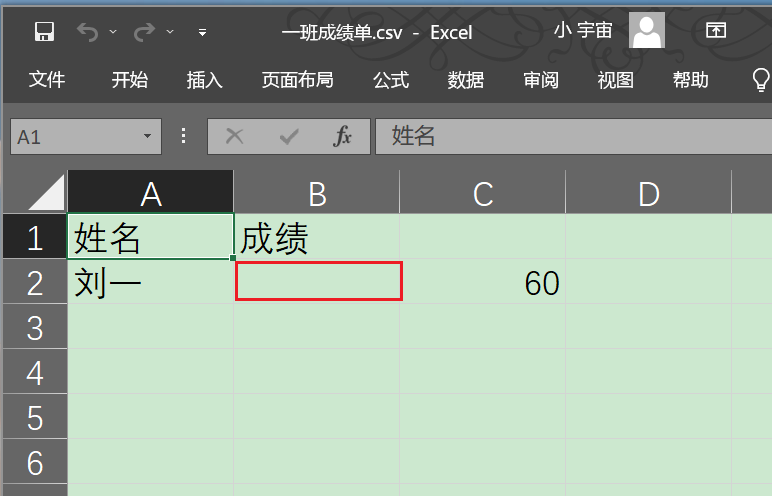 4.空格
4.空格
CSV文件中,如果有多个英文逗号, 第一个逗号的作用是对值进行分隔。 剩下的逗号表示空单元格。 一个逗号表示一个空单元格。 2.5 实操练习3新建一个【Excel】表格 点击打开 在A1单元格中输入姓名,在B1单元格中输入成绩。 点击【文件】-【另存为】 【文件类型(T)】中选择【CSV(逗号分隔)】 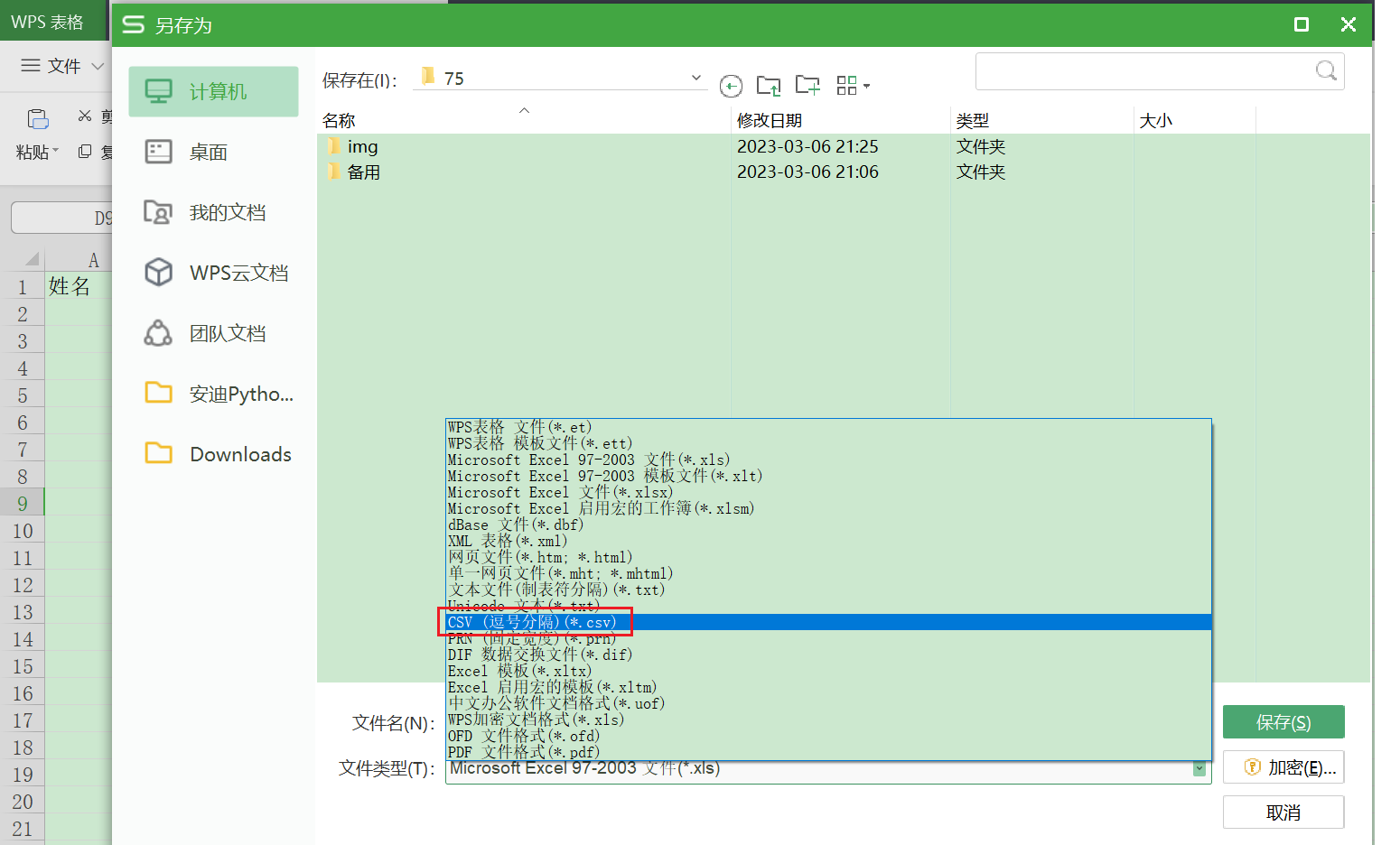 5.【文件类型(T)】中选择【CSV(逗号分隔)】
【文件名(N)】中输入2班成绩单
5.【文件类型(T)】中选择【CSV(逗号分隔)】
【文件名(N)】中输入2班成绩单
这样我们就新建了一个CSV文件。 通过以上的练习,我们应该了解了CSV文件的手动操作。 下面我们来学习代码操作CSV文件。 3. os模块文件操作我们首先用os模块来创建所需的文件夹和删除刚才新建的CSV文件。 3.1 准备工作用VScode编辑器打开75文件夹。 在75文件夹里新建一个75.py文件。 大家在75.py文件里编写代码。 3.2 os模块知识回顾os 是 operation system 的缩写。 operation [ˌɒpəˈreɪʃn]:操作。 system [ˈsɪstəm]:系统。 os 模块支持文件和目录操作,进程管理,环境变量管理等功能。 调用模块下的函数语法:模块名.函数名(): 3.3 模块导入语法os 是内置模块,import导入即可使用。 【语法】 import + 模块名 import [ˈɪmpɔːt]:导入。 【示例】 import os 3.4 os.getcwd()获取当前工作目录cwd 是 current working Directory 的缩写,译为当前工作目录。 当前工作目录就是我们现在编写代码的文件所在的文件夹。 # 导入os模块import os# getcwd作用是获取当前工作目录os.getcwd( )【终端输出】 'd:\\75'终端输出的'd:\\75'就是我当前的工作目录,即D盘下的75文件夹。 3.5 os.remove()删除指定文件remove[rɪˈmuːv]:去掉、废除。 我们用os.remove()将刚在在75文件夹里新建的2个csv文件和1个xlsx文件删除。 【删除前】 # 调用模块的函数# 模块名.函数名# remove 的作用是删除指定文件os.remove("1班成绩单.csv")os.remove("2班成绩单.csv")os.remove(r"D:\75\新建 XLSX 工作表.xlsx") 运行代码后,大家看你VScode编辑器左侧的资源管理器里只有一个75.py文件了。 【语法解析】 os.remove("1班成绩单.csv")os.remove("2班成绩单.csv")这里remove括号中的参数为要删除文件的相对路径。 os.remove(r"D:\75\新建 XLSX 工作表.xlsx")这里remove括号中的参数为要删除文件的绝对路径。 我这里写2种路径是为回顾路径的相关知识点,实操中大家结合自己的需要自行选择。 路径前的r表示路径转义,加了这个r就可以不用考虑路径参数中的转义字符。 【VScode查看路径的方法】 点击VScode左上角的【资源管理器】 右键点击【一班成绩单.csv】 选择【复制路径】或【复制相对路径】,然后粘贴就能快速得到文件的路径。 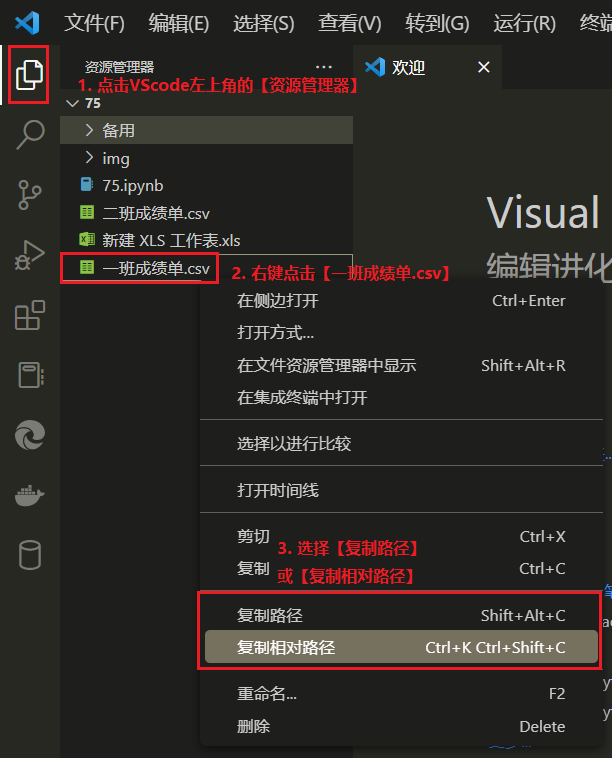 7.复制路径
3.6 os.mkdir()新建目录
7.复制路径
3.6 os.mkdir()新建目录
mkdir是 make directory 的缩写,译为创建目录。 mkdir 的作用就相当于新建文件夹。 【目标任务】 在当前文件夹下用相对路径新建一个【各班级成绩】文件夹。 在当前文件夹下用绝对路径新建一个【会员表】文件夹。 import os# 调用模块的函数# 模块名.函数名# mkdir作用是创建目录# 相对路径os.mkdir("各班级成绩") # 绝对路径os.mkdir(r"D:\75\会员表") 运行上述代码后,大家看左侧的资源管理器里多了2个文件夹。 一个是【各班级成绩】文件夹。 os.mkdir("各班级成绩")mkdir的参数为文件夹名称,表示在当前文件夹下创建目录。 os.mkdir(r"D:\75\会员表")mkdir的参数为绝对路径,表示在D盘下的75文件夹下创建一个名为【会员表】的目录。 4. CSV文件的写入【体验代码】 # 导入 csv 模块import csv# 用字典存储要写入CSV文件的信息dict1 = {'姓名': '刘一', '成绩': '100'}dict2 = {'姓名': '陈二', '成绩': '90'} # 设置文件的表头,即列名header = ['姓名', '成绩'] # 文件的相对路径file_path = r'各班级成绩\1班成绩单.csv' # 以自动关闭文件的方式创建文件对象with open(file_path, 'w', encoding='utf-8', newline="") as f: # 实例化类 DictWriter(),得到 DictWriter 对象 dw = csv.DictWriter(f, fieldnames=header) # 写入文件的表头 dw .writeheader() # 写入内容,每次写入一行 dw.writerow(dict1) dw.writerow(dict2) 【终端显示】 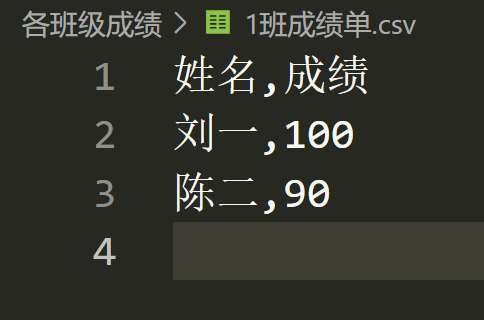 8.运行结果
8.运行结果
运行上述的代码后,我们在【各班级成绩】文件夹下新建了一个【1班成绩单.csv】文件。 并把字典的内容成功写入了CSV文件。 字典的键姓名,成绩就是CSV文件的列名。 字典的值100,90是CSV文件每列相对应的值。 我们只需要10行代码就能完成文件的创建和值的写入。 下面我们来拆解这10行代码。 5. CSV模块知识csv模块是Python的内置模块,不需要安装,import导入就能直接使用。 【导入语法】 import csv我们在71节《库与模块》中学过一个.py文件就是一个模块。 我们在第73节《python第三方库安装教程》也讲到过安装完Python后电脑会有有一个文件夹用来存放模块的源代码。 下面是我电脑csv.py存储的路径。 C:\Users\XXXX\AppData\Local\Programs\Python\Python39\Lib 【CSV模块的部分源代码】 class DictReader: def __init__(self, f, fieldnames=None, restkey=None, restval=None, dialect="excel", *args, **kwds): self._fieldnames = fieldnames # list of keys for the dict self.restkey = restkey # key to catch long rows self.restval = restval # default value for short rows self.reader = reader(f, dialect, *args, **kwds) self.dialect = dialect self.line_num = 0def __iter__(self): return self @property def fieldnames(self): if self._fieldnames is None: try: self._fieldnames = next(self.reader) except StopIteration: pass self.line_num = self.reader.line_num return self._fieldnames @fieldnames.setter def fieldnames(self, value): self._fieldnames = value def __next__(self): if self.line_num == 0: # Used only for its side effect. self.fieldnames row = next(self.reader) self.line_num = self.reader.line_num # unlike the basic reader, we prefer not to return blanks, # because we will typically wind up with a dict full of None # values while row == []: row = next(self.reader) d = dict(zip(self.fieldnames, row)) lf = len(self.fieldnames) lr = len(row) if lf lr: for key in self.fieldnames[lr:]: d[key] = self.restval return d class DictWriter: def __init__(self, f, fieldnames, restval="", extrasaction="raise", dialect="excel", *args, **kwds): self.fieldnames = fieldnames # list of keys for the dict self.restval = restval # for writing short dicts if extrasaction.lower() not in ("raise", "ignore"): raise ValueError("extrasaction (%s) must be 'raise' or 'ignore'" % extrasaction) self.extrasaction = extrasaction self.writer = writer(f, dialect, *args, **kwds) def writeheader(self): header = dict(zip(self.fieldnames, self.fieldnames)) return self.writerow(header) def _dict_to_list(self, rowdict): if self.extrasaction == "raise": wrong_fields = rowdict.keys() - self.fieldnames if wrong_fields: raise ValueError("dict contains fields not in fieldnames: " + ", ".join([repr(x) for x in wrong_fields])) return (rowdict.get(key, self.restval) for key in self.fieldnames) def writerow(self, rowdict): return self.writer.writerow(self._dict_to_list(rowdict)) def writerows(self, rowdicts): return self.writer.writerows(map(self._dict_to_list, rowdicts)) 上面的代码是我从Python的csv.py模块的源代码中复制出来的部分代码。 这里的展示源代码的目的: 一是为了让大家更深入的理解什么是模块。 二是为了让大家更直观的感受CSV模块的的类与方法。 知其然并知其所以然,这样就不存在记忆代码这种说法。 【CSV的类】 class DictReader: class DictWriter:class关键字,首字母D大写我们能很准确的确定这是2个类名。 dictionary [ˈdɪkʃənri]:字典。 reader [ˈriːdə]:读者。 writer [ˈraɪtə]:写手。 DictReader:用字典的形式读取。 DictWriter:以字典的形式写入。 这2个类的作用顾名思义就是读取和写入。 【CSV的函数】 def writeheader(self):def writerow(self, rowdict):def writerows(self, rowdicts):以def开头的即是自定义函数。 在类中定义的函数我们称为方法。 上述3行代码就是在DictWriter类中定义的3个方法。 header [ˈhedə(r)]:头。 row [rəʊ]:行。 writeheader:写入头(这里的头指表格的表头,即列名)。 writerow:写入一行, writerows:写入多行。 上述内容是我个人的理解,仅供大家参考。 【调用模块或库中的类、函数、变量】 调用模块或库的类:模块名.类名(),如 csv.DictReader() 调用模块或库的函数:模块名.函数名(),如 csv.writerow 6.语法解析 6.1 导入模块 # 导入 csv 模块import csv处理CSV文件需要用csv模块。 6.2 新建字典 # 用字典存储要写入CSV文件的信息dict1 = {'姓名': '刘一', '成绩': '100'}dict2 = {'姓名': '陈二', '成绩': '90'}字典是一种数据类型。 字典用英文大括号{}表示; 字典的键和值之间用英文冒号:分隔; 键值对之间英文逗号,分隔; 字典的键是就是文件的列名,也就是表头的意思。 这里的键是姓名和成绩。 字典的值就是每列对应的值。 姓名对应的值是刘一和陈二。 成绩对应的值是100和90。 作者:安迪的python学习笔记 xyz77520520 6.3 确定表头 # 设置文件的表头,即列名header = ['姓名', '成绩']header [ˈhedə(r)]:头。 header是变量名,它存储的是一个列表。 列表里的元素就是要写入的表头。  10.表头
10.表头
注意这个表头就是字典的键。 表头和字典的键要一一对应起来,否则程序会找不到要写入的值。 6.4 确定文件的路径确定文件名:1班成绩单.csv。 这里我是要写到csv文件里,那文件扩展名就用.csv。 1班成绩单是我给文件起的名字。 我要在【75】文件夹里的【各班级成绩】文件夹里新建文件,该文件的路径应该写为: 【相对路径】 # 文件的相对路径file_path = r'各班级成绩\1班成绩单.csv'如果你的编辑器打开的不是【75】文件,则相对路径就不是上面这个。 【绝对路径】 # 设置文件路径file_path = r'D:\75\各班级成绩\1班成绩单.csv'字母r起到路径转义的作用,有了r可以不用考虑路径参数里的转义字符。 6.5 创建文件对象日常工作中我们要往一个文件里写入内容,我们首先要创建一个文件,才能写入。 Python也是一样,我们要写入东西,往哪里写呢?我们首先得有一个对象,对吧? 因此我们需要创建一个文件对象。 Python一切皆对象就是这个意思。 我们在第69节《open函数—打开文件并返回文件对象》和第70节《with open( ) as 以自动关闭文件的方式打开文件》中学过,open语句和with open 语句都能创建一个文件对象。 # 以自动关闭文件的方式创建文件对象with open(file_path, 'w', encoding='utf-8', newline="") as f:with open as f : 和 open语句的参数是一样的,区别是 with open 语句可以自动关闭文件。 【open语句的参数】 open(file, mode='', encoding='utf-8', newline="", errors='None') 参数 file 表示要打开文件的路径。路径我们已经确定好了,就是上面的file_path变量。 参数 mode 决定了打开文件的模式。 11创建文件的方式
11创建文件的方式
这里我们需要要写入内容,我们可以选择w模式。 w模式在文件不存在的情况下,可以直接创建文件。 参数 encoding 表示文件的编码方式,文件编码方式一般为encoding='utf-8'。 参数 newline 表示用于区分换行符,只对文本模式有效,可以取的值有None,\n,\r。 newline [n'ju:laɪn]:换行。 说人话意思就是如果你在open函数中增加了参数newline="",那写入的内容是没有空行的。 如果没有这个参数,那写入的内容是有空行的(后面做演示)。 errors参数大家不用理会。【f是文件对象】 as f中的f指的是文件对象。 等同于你在电脑上新建的一个文件,只是这个文件是实物,是肉眼可见的。 f 是一个变量名,你可以随意命名。 这个f就是一个我们肉眼看不见的文件对象,我们就是要向这个对象里写入内容。 Python一切皆对象,操作文件要有文件对象,就是这个意思哈。 6.6 实例化类创建对象我们之前讲过,类的作用是创建对象。 对象创建的语法如下: 对象名=类名() # 实例化类 DictWriter(),得到 DictWriter 对象dw = csv.DictWriter(f, fieldnames=header)print(type(dw))dw是对象名,你可随意起名。 csv是模块名。 这里我们调用的是模块里的类,因此语法为模块名.类名 DictWriter是类名,作用是用字典的形式写入。 括号的第1个参数是文件对象, 括号的第2个参数是字段名称,我们可以理解成表头或列名。 我们将确定好的表头,即变量header赋值给参数fieldnames。 fieldnames=headerfield[fiːld]:字段。 fieldnames 字段名称 我多加了下面这行代码: print(type(dw))加入这行代码后,程序会输出dw的数据类型。 【终端输出】 观看输出,大家就能明白dw就是类实例化后创建的DictWriter对象。 6.7 写入内容文件对象创建成功后,又实例化了一个可以用字典写入的对象。 下面我们就往这个对象里写入内容。 写入内容那我们就需要用调用类的方法了。 作者:安迪的python学习笔记 xyz77520520 【调用类的方法】 对象名.方法名(值,...) # 写入文件的表头dw.writeheader()# 写入文件的单行内容dw.writerow(dict1)dw.writerow(dict2) dw是我给类实例化后创建的对象起的名字。 writeheader是类的方法名,作用是写入表头。 表头在实例化的时候已经赋值给参数fieldnames,因此这里的参数为空。 writerow类的方法名,作用是写入行,即一次写入一行。 dict1和dict2是要写入的值。 newline参数和writerows下节再讲。 7. 代码总结 # 导入os 模块,用于创建文件目录import os# 导入 csv 模块,用于操作CSV文件import csv# mkdir作用是创建目录# 相对路径os.mkdir("各班级成绩2") # 用字典存储要写入CSV文件的信息dict1 = {'姓名': '刘一', '成绩': '100'}dict2 = {'姓名': '陈二', '成绩': '90'} # 设置文件的表头,即列名header = ['姓名', '成绩'] # 文件的相对路径file_path = r'各班级成绩2\1班成绩单.csv' # 以自动关闭文件的方式创建文件对象with open(file_path, 'w', encoding='utf-8', newline="") as f: # 实例化类 DictWriter(),得到 DictWriter 对象 dw = csv.DictWriter(f, fieldnames=header) # 写入文件的表头 dw .writeheader() # 写入内容,每次写入一行 dw.writerow(dict1) dw.writerow(dict2) 【备注】 这一节构思了许久,看着好像没什么大工程,但我总共花了差不多7个小时。 如果笔记对你有帮助,请帮忙点个在看或分享给其他小伙伴。 你的分享是我持续创作的动力哦!!!感恩你的喜欢!!! 因为有文章被不知名转载,文中加入了作者。 |
【本文地址】