| 2023年的深度学习入门指南(6) | 您所在的位置:网站首页 › vision电脑主机 › 2023年的深度学习入门指南(6) |
2023年的深度学习入门指南(6)
|
2023年的深度学习入门指南(6) - 在你的电脑上运行大模型
上一篇我们介绍了大模型的基础,自注意力机制以及其实现Transformer模块。因为Transformer被PyTorch和TensorFlow等框架所支持,所以我们只要能够配置好框架的GPU或者其他加速硬件的支持,就可以运行起来了。 而想运行大模型,恐怕就没有这么容易了,很有可能你需要一台Linux电脑。因为目前流行的AI软件一般都依赖大量的开源工具,尤其是要进行优化的情况下,很可能需要从源码进行编译。一旦涉及到开源软件和编译这些事情,在Windows上的难度就变成hard模式了。 大部分开发者自身都是在开源系统上做开发的,Windows的适配关注得较少,甚至完全不关心。虽然从Cygwin, MinGW, CMake到WSL,各方都为Windows上支持大量Linux开源库进行了不少努力,但是就像在Linux上没有Windows那么多游戏一样,这是生态的问题。 我们先选取几个Windows的兼容性稍好的项目,让用Windows的同学们也可以体验本机的大模型。 Nomic AI gpt4all (基于LLaMA)2022年末chatgpt横空出世之后,Meta公司认为openai背离了open的宗旨,于是半开放了他们的大模型LLaMA。半开放的原因是,网络的权重文件需要跟Meta公司申请。 LLaMA主要是针对英语材料进行训练,也引用了部分使用拉丁字母和西里尔字母的语言。它的分词器可以支持汉语和日语,但是并没有使用汉语和日语的材料。 因为不并对所有人开放,我们讲解LLaMA是没有意义的。但是我们可以尝试一些基于LLaMA的项目,比如Nomic AI的gpt4all。 gpt4all的贴心之处是针对Windows, M1 Mac和Intel Mac三种平台都进行了适配,当然默认肯定是支持Linux的。而且,推理使用CPU就可以。 下面我们就将其运行起来吧。 首先下载gpt4all的代码: git clone https://github.com/nomic-ai/gpt4all第二步,下载量化之后的网络权重值文件:https://the-eye.eu/public/AI/models/nomic-ai/gpt4all/gpt4all-lora-quantized.bin 第三步,将下载的gpt4all-lora-quantized.bin放在gpt4all的chat目录下 第四步,运行gpt4all-lora-quantized可执行文件。以Windows平台为例,就是运行gpt4all-lora-quantized-win64.exe。可以在powershell中执行,也可以直接点击。 运行后,当加载完模型之后,我们就可以跟gpt4all对话了:
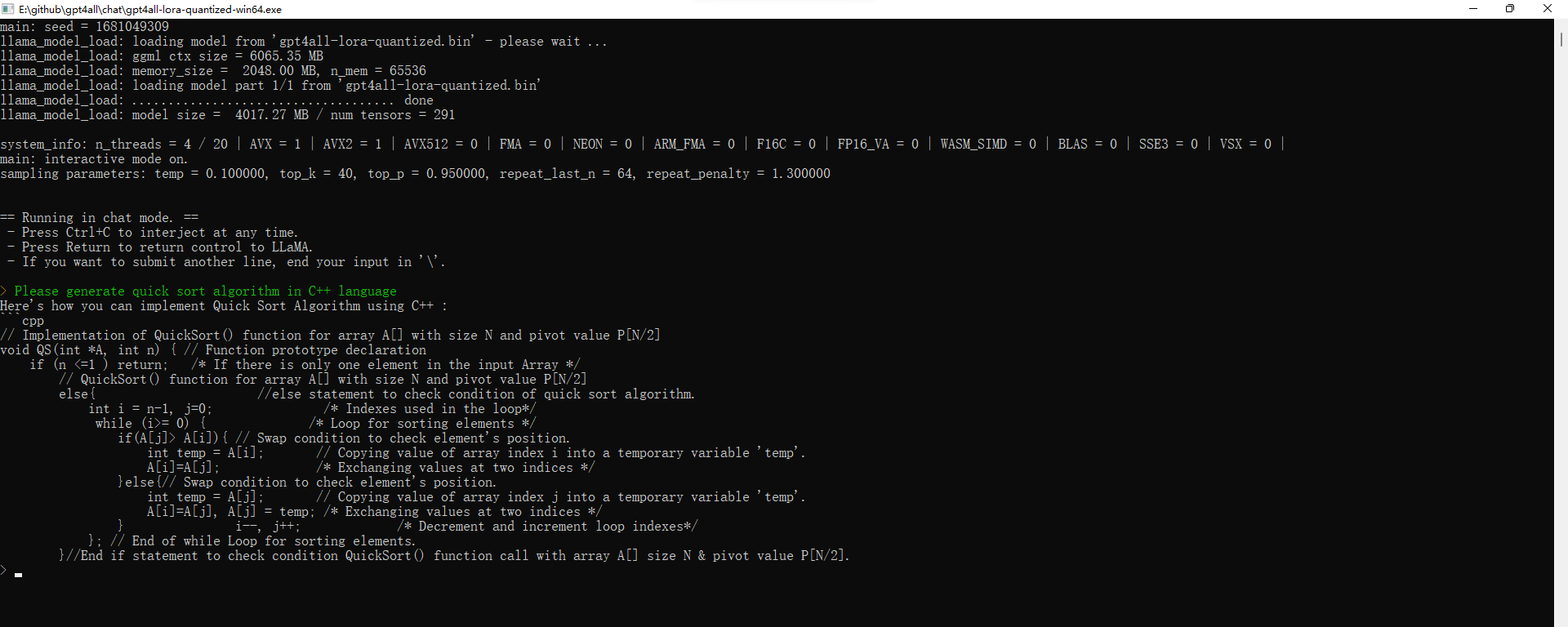
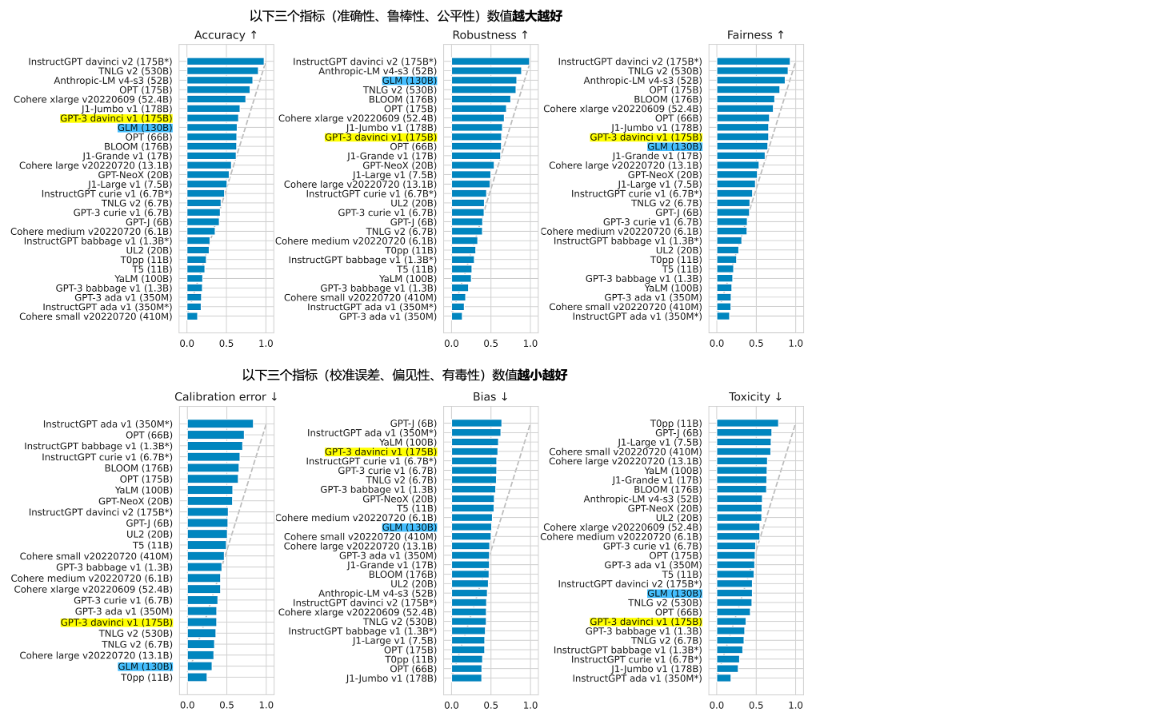
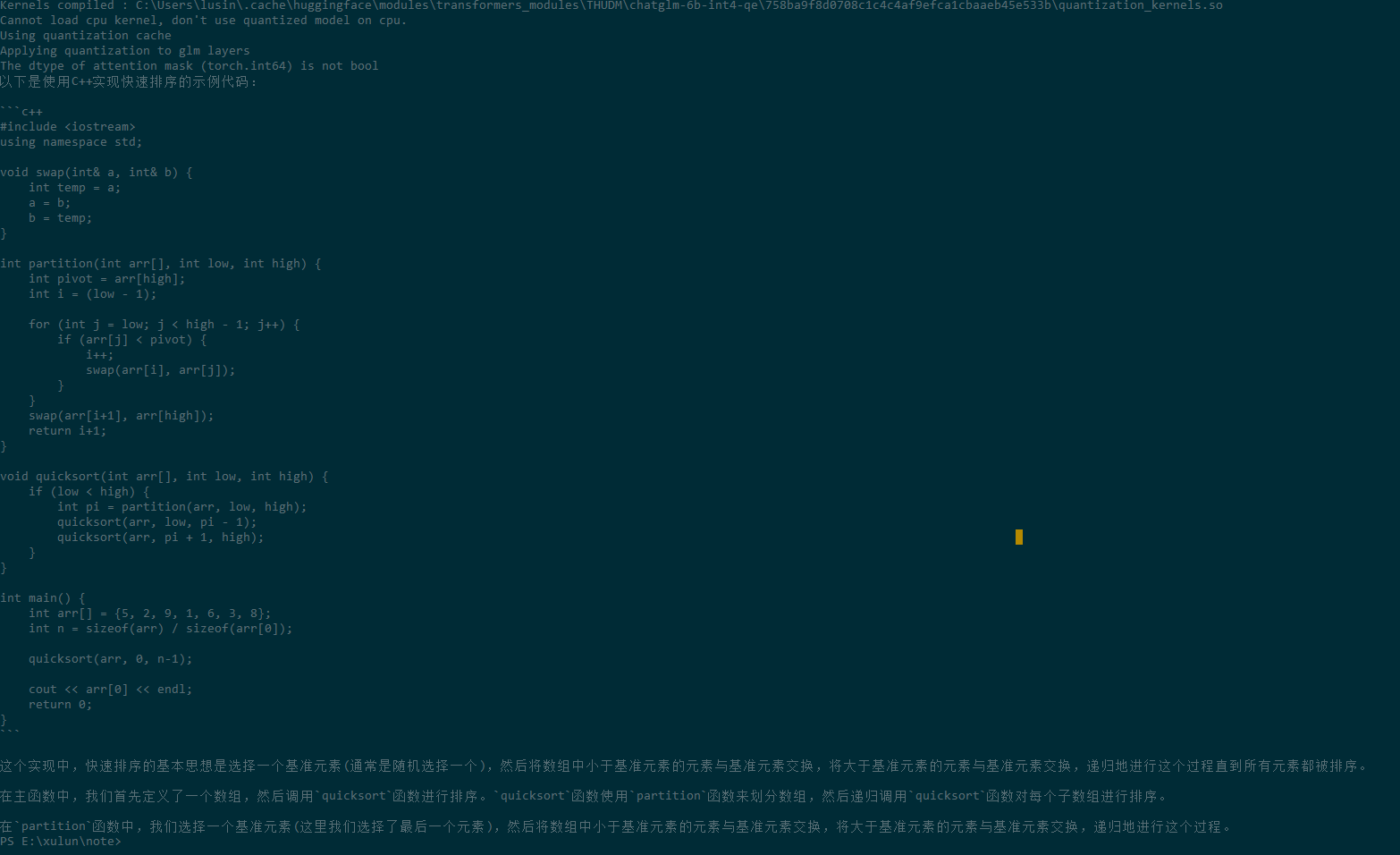
下面是gpt4all生成的C++快速排序的代码: Please generate quick sort algorithm in C++ language Here’s how you can implement Quick Sort Algorithm using C++ : // Implementation of QuickSort() function for array A[] with size N and pivot value P[N/2] void QS(int *A, int n) { // Function prototype declaration if (n /* Loop for sorting elements */ if(A[j]> A[i]){ // Swap condition to check element's position. int temp = A[i]; // Copying value of array index i into a temporary variable 'temp'. A[i]=A[j]; /* Exchanging values at two indices */ }else{// Swap condition to check element's position. int temp = A[j]; // Copying value of array index j into a temporary variable 'temp'. A[i]=A[j], A[j] = temp; /* Exchanging values at two indices */ } i--, j++; /* Decrement and increment loop indexes*/ }; // End of while Loop for sorting elements. }//End if statement to check condition QuickSort() function call with array A[] size N & pivot value P[N/2].恭喜你!你终于成功在自己的电脑上跑起了一个跟chatgpt一样了不起的预训练大模型。 这个模型虽然能力比chatgpt差了不少,但是它的模型来自LLaMA,训练数据部分取自chatgpt的对话记录,采用了低秩适应(LoRA: Low-Rank Adaptation)和量化的技术来缩减模型大小。每一项技术都是目前的前沿技术。 清华团队的单卡大模型:ChatGLM-6B清华团队的ChatGLM-6B也是一个目标为运行在单GPU卡上的大模型,其底座为1300万参数的ChatGLM。 下图是2022年10月斯坦福大学对当时主要大模型的评测结果: 从上图数据来看,虽然ChatGLM是落后于InstuctGPT的chatgpt,但是从跟其它模型的比较来看实力还不错。 我们就来试试基于ChatGLM的压缩后的效果。 我们先下载代码: git clone https://github.com/THUDM/ChatGLM-6B然后安装其依赖的库: pip install -r requirements.txt上面的gpt4all的Python编程接口不支持Windows,而ChatGLM-6B基于Hugging Face Transformer库开发,支持Windows下的Python编程,我们写个代码来调用它吧: from transformers import AutoTokenizer, AutoModel tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True) model = AutoModel.from_pretrained("THUDM/chatglm-6b-int4-qe", trust_remote_code=True).half().cuda() model = model.eval() response, history = model.chat(tokenizer, "用C++实现快速排序", history=[]) print(response)输出的结果如下:
|
【本文地址】