| 字符集与编码 | 您所在的位置:网站首页 › utf-16le编码 › 字符集与编码 |
字符集与编码
|
字符集与编码
一、字符集与编码
计算机数据都是二进制数据,人们为了把字符与二进制数据相对应,于是就有了字符集。
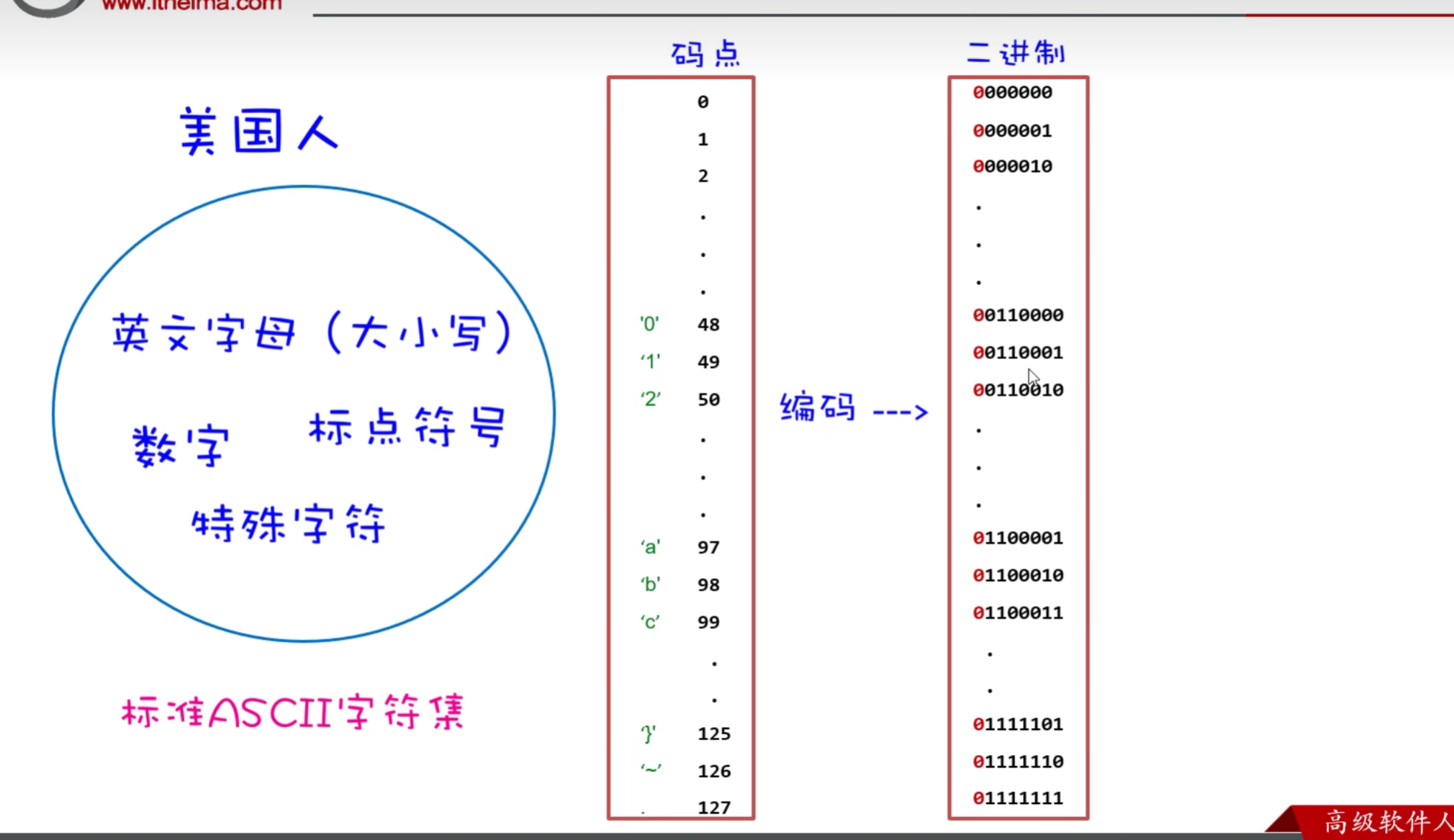
美国人首先发明了ASCII字符集来使用,将字符和数字进行一一对应,这个数字称之为码点,将码点转换为二进制数据这个过程称之为编码,由于美国的字符比较少,每个字符用一个字节表示足矣。不够8位首位补0. 随着计算机的发展,越来越多的人使用计算机 中国随后发明了字符集(GBK),由于汉字数量多,就将一个码点转换为两个字节(16位)。GBK兼容ASCII码,字母数字标点符号,特殊字符还按ASCII码来用一个字节 GBK二进制编码格式 1xxxxxxx xxxxxxxx 当用GBK解码时 当遇到首位是1 就连读2个字节对该字符进行解码 ,当遇到首位是0就读一个字节对该字符进行解码 随后更多的国家发明了自己的字符集 为了统一字符集,ISO(国际标准化组织)发明了Unicode编码(万国码)兼容ASCII码,它可以容纳世界上所有文字和符号。 起初将一个码点转换为四个字节(这个编码称之为UTF-32编码) 显然4个字节表示一个字符是在网络传输中是非常占用内存的 后来就发明了UTF-8编码
UTF-8 解码:当遇到首位是0,就读取一个字节进行这个字节的解码 接着往后读遇到首位是110 就连读2个字节表示一个字符进行这个字符的解码 1110 连读3个字节表示一个字符进行该字符解码 11110 连读4个字节表示一个字符进行该字符解码 注意: ANSI是本土编码 中国是GBK,美国是ASCII码 二、解决javaweb中文乱码问题前景知识: Tomcat服务器默认编码的字符集是ISO8859-1,浏览器默认字符集是Unicode 编码方式是UTF-8 get方法进行参数传递是从消息行带过去的没有封装到request对象里面 post方法进行参数传递是封装到request对象里面。 req.setCharacterEncoding(“UTF-8”); 设置服务器接受request参数传来的数据用UTF-8解码 ==resp.setContentType(“text/html;charset=utf-8”);==设置服务器向浏览器响应编码是UTF-8编码 当在Servlet读取数据时候: get方式不用转码,因为浏览器URL默认是UTF-8编码,Tomcat8.0以后对URL的解码也是UTF-8所以只需设置响应到浏览器编码即可。 post方式需要转码req.setCharacterEncoding(“UTF-8”); 当从浏览器传来数据通过服务器响应回浏览器时候 get和post方式都需要设置Tomcat的响应编码 resp.setContentType(“text/html;charset=utf-8”); |

【本文地址】