| 东南大学漆桂林团队大模型评测 | 您所在的位置:网站首页 › transfer的词组 › 东南大学漆桂林团队大模型评测 |
东南大学漆桂林团队大模型评测
|
作者: @漆桂林 (已授权转载)链接:https://zhuanlan.zhihu.com/p/613649876 点击关注@LiteAI,跟进最新Efficient AI & 边缘AI & 模型轻量化技术,跟进最新DL & CV技术。 作者:谭亦鸣、闵德海、李煜、李文博、胡楠、陈永锐、漆桂林作者单位:东南大学 知识科学与工程实验室 论文地址: https://arxiv.org/abs/2303.07992 摘要ChatGPT是一种强大的大型语言模型(LLM),在自然语言理解方面取得了显著进展。然而,该模型的性能和限制仍需要广泛评估。由于ChatGPT覆盖了Wikipedia等资源并支持自然语言问答,因此它已引起关注,作为传统基于知识的问答(KBQA)模型的潜在替代品。 复杂问答是KBQA的一个具有挑战性的任务,它全面测试了模型在语义解析和推理方面的能力。为了评估ChatGPT作为问答系统(QAS)利用其自身知识的表现,我们提出了一个框架,评估其回答复杂问题的能力。我们的方法涉及将复杂问题的潜在特征分类,并使用多个标签描述每个测试问题,以识别组合推理。 按照Ribeiro等人[1]提出的CheckList的黑盒测试规范,我们开发了一种评估方法,以衡量ChatGPT在推理回答复杂问题方面的功能和可靠性。我们使用所提出的框架评估ChatGPT在8个KB-based CQA数据集上的问答表现,包括6个英文和2个多语言数据集,共约190,000个测试案例。我们比较了ChatGPT、GPT3.5、GPT3和FLAN-T5的评估结果,以挖掘LLMs长期存在的历史问题。我们收集的数据集和代码公开在:https://github.com/tan92hl/Complex-Question-Answering-Evaluation-of-ChatGPT 研究介绍ChatGPT 在人机交互测试中展现了强大的自然语言理解能力。研究者对这种大型语言模型在现有自然语言处理任务中的表现和局限性很感兴趣。Petroni等人[2]的研究表明,语言模型可以被视为知识库(KB),以支持下游任务。作为一个大型语言模型,ChatGPT通过利用自身的知识展现出强大的问答能力。因此,考虑到其对维基百科的广泛覆盖和卓越的自然语言理解能力,ChatGPT是否能够取代传统的KBQA模型已成为一个热门话题。 在各种类型的KBQA任务中,复杂问答(基于知识库的复杂问答,KB-based CQA)是一个具有挑战性的任务,要求问答模型具有组合推理的能力,以回答需要多跳推理、属性比较、集合操作和其他复杂推理的问题。我们认为,评估ChatGPT利用自身知识回答复杂问题的能力可以帮助我们回答ChatGPT是否能够取代传统的KBQA模型的问题。此评估从两个方面评估ChatGPT:1)分析其对于复杂问题的语义解析能力;2)测试其通过组合推理过程使用自身知识回答问题的可靠性。 经过对ChatGPT相关论文的仔细审查,我们发现许多评估工作,Omar等人[3]在手动评估了约200个测试用例后指出,与传统的KBQA模型相比,ChatGPT的稳定性较低。Bang等人[4]分析了30个样本后指出,ChatGPT是一个懒惰的推理器,在归纳推理面表现很差。 现有的工作通常依靠小规模采样测试和人工评估相结合的方法来完成对ChatGPT性能的评估,因为API的限制和通过Exact Match (EM)评估生成答案的困难。因此,往往得到的是粗略的和经验性的发现,而不是可量化的结果。因此,需要进一步的验证以确保这些结论的普适性。 在这项工作中,我们利用ChatGPT自身的知识作为知识库,在基于知识的问答(CQA)方面对其进行全面评估,并将其优点和限制与其他类似的大型语言模型(LLMs)和现有的基于知识的问答(KBQA)模型进行比较。我们的评估框架由两个主要步骤组成:首先,受HELM[21]的场景驱动评估策略的启发,我们设计了一种基于特征的多标签注释方法来标记测试问题中涉及的答案类型、推理操作和语言。这些标签不仅有助于我们逐个分析ChatGPT的推理能力,而且它们的组合也可以帮助我们发现许多ChatGPT擅长或不擅长的潜在QA场景。然后,遵循CheckList[22]的测试规范,测试目标分为三个部分:最小功能测试(MFT)、不变性测试(INV)和方向性期望测试(DIR)。第一个反映了模型执行各种推理任务的准确性,而第二个和第三个反映了推理的可靠性。为了在INV和DIR测试中获得更多可分析的结果,我们采用了Chain-of-Thought(CoT)[5]方法,设计提示模板以建立其他测试用例。 要建立这样的评估框架,需要解决两个主要的挑战。 第一:是多源数据集的统一注释。由于数据集发布时间的差异,现有的KB-based CQA数据集使用了不同形式的答案,并且只提供了(问题,答案)对或其他推理路径如SPARQL等。为了实现统一的注释,我们选择了带有SPARQL的KBQA数据集作为这项工作的测试数据集,使用SPARQL的关键字来识别测试问题所包括的潜在推理操作。利用测试问题文本中的句法结构和问题关键词语,我们实现了答案类型的自动识别,并且多语言数据集中的语言标签直接由数据集提供。 第二:评估任务涉及将生成式文本答案与答案短语进行匹配。ChatGPT等LLMs通常生成的是包含相关信息的文本形式的答案,而KB-based CQA数据集提供的是具体的答案短语(Golden Answers)。两者之间的差距使得直接使用传统的精确匹配(EA)难以实现较高的准确度。因此,我们采用了基于短语的答案匹配策略。利用成分句法解析树[6]的方法,我们将LLMs的输出处理成一组名词短语,然后通过Wikidata获得答案短语(Golden Answers)的多语言别名集合。此外,我们还设置了短语向量相似度的阈值。当短语集合之间没有精确匹配,但有相似度高于阈值的短语对时,我们通过人工评估来补充对样本的最终判断。 最后,我们收集了6个单语英语数据集和2个多语言数据集作为本次评估实验的测试数据,规模约为19万个问题,其中包括约12,000个涵盖13种语言的多语言问题。作为对比的LLMs包括GPT3[7]、GPT3.5[8]和FLAN-T5[9]。我们还引入了所测数据集的当前SOTA作为比较,以补充ChatGPT在相关任务上与监督模型和无监督模型的表现对比。 我们的主要发现和见解如下: 在单语言的问答测试中,ChatGPT的大多数表现优于类似模型,但在回答数字或基于时间的问题时表现并不是最佳的。此外,在涉及多跳或星型事实推理的问题时,其表现也不如GPT3.5 V3。在多语言测试中,ChatGPT对于回答低资源语言问题表现更为优秀。在CheckList测试中,我们发现ChatGPT在知识库问答方面存在一些限制,包括:1. MTF测试结果显示,它不擅长回答只涉及一种类型推理的问题。2. INV测试结果表明,与传统的KBQA相比,ChatGPT在处理相似或几乎相同的输入时不够稳定。3. DIR测试显示,ChatGPT并不总是对正确提示提供积极反馈。当面对修改后的测试样本时,其输出的变化并不总是符合我们的预期。使用CoT(思路链)提示来引导ChatGPT逐步回答问题是有用的,特别是在增强需要使用计数获取答案的问题的解决能力方面表现出特别的功效。背景和相关工作大语言模型和prompt自然语言处理领域的研究表明,语言模型可以通过文本指令执行各种下游NLP任务。指示学习(Prompt Learning)和LLM的研究已经取得了显著进展,其中改进提示(Prompt)可以使LLM中包含的信息更准确地应用于目标任务。随着更强大的LLM的出现,它们显著增强的自然语言交互能力使得指示设计不再需要以任务为中心,而是通过建立一个Chain-of-Thought来引导LLM生成中间的推理步骤。同时,LLM的自然语言理解能力是指示学习的有效性的关键因素。为了改进LLM,许多工作[10,11]都致力于扩展LLM。其中,ChatGPT是目前受到最多关注的模型之一,它具有高质量的输入响应、通过对话进行自我纠正的能力以及拒绝不适当问题的能力。大语言模型的评估最近出现了许多旨在评估LLM的作品,它们使用现有的NLP数据集构建大规模基准,包括BIG-Bench、AILMHarness和SuperGLUE等大规模基准[12,13,14],以HELM[15]等全面评估LLM在各种任务场景下表现的方法。受到这个想法的启发,本文建立了一个以特征为驱动的评估系统,以全面评估LLM面对各种复杂问题特征时的问题理解和答案生成能力。其他一些作品也通过基于人类的输入作为案例分析,评估了ChatGPT的具体能力,如数学能力和推理能力[16]。NLP模型的黑盒测试由于训练LLM的高昂成本,目前LLM的评估工作主要集中在黑盒测试上。有许多有价值的方法可以作为参考,例如用于评估鲁棒性的方法[17]、用于对抗性变化的方法[18]、关于注意力和可解释性的工作[19]等。目前最全面的方法是CheckList协议,将评估目标分为MFT、INV和DIR三个部分。在本工作中,我们遵循这个评估计划,并使用CoT提示生成INV和DIR的测试用例。 评估框架我们的评估框架由两个阶段组成。第一阶段旨在通过使用多个标签来描述测试问题,包括问题类型、组合推理类型和语言特征;第二阶段根据CheckList框架评估LLM对测试问题的每个标签的功能性、QA的鲁棒性和输出内容的可控性。接下来将详细解释这些阶段的设计,其过程如图1所示。 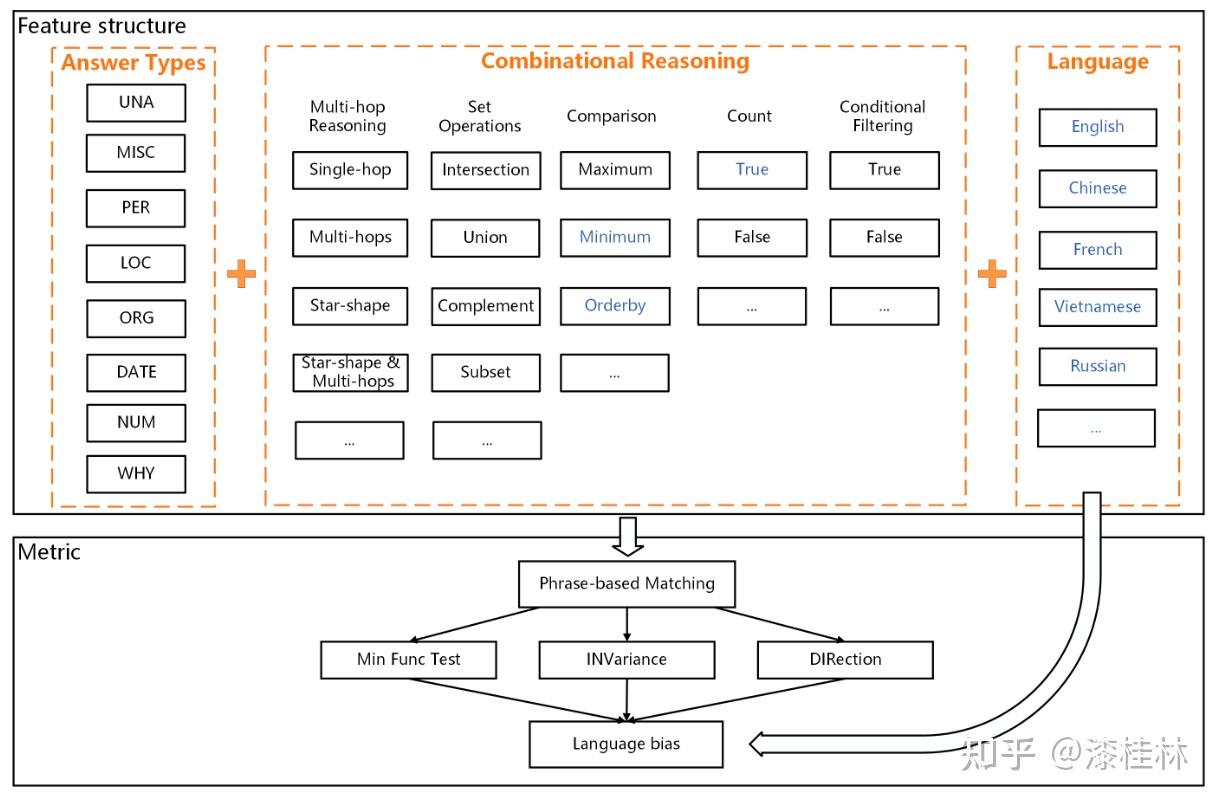 图1 评估框架概述特征驱动的多标签问题分类由于现有数据集通常使用不同的标签来识别答案类型或推理类型等,为了在评估中进行统一分析,我们需要标准化这些特征类型的标签。我们设计了三种类别的标签,包括“答案类型”、“推理类型”和“语言类型”,用于描述复杂问题中包含的特征。这些特征反映了问题中提到的主题类型、获取答案的方式和问题的语言形式。通常,这些特征对应于QA系统的子功能。每个问题通常只包含一个“答案类型”标签。基于使用命名实体识别(NER)定义事实类型的类型定义、基于英语疑问词分类的问题类型分类以及从现有KBQA数据集中归纳出答案类型,我们将答案类型设置为以下八种类型:日期/时间(DATE)、地点(LOC)、人名(PER)、原因(WHY)、是/否(Boolean)、其他事实(MISC)、数字(NUM)或无法回答(UNA)。基于KBQA数据集提供的SPARQL查询,我们还归纳出了八个“推理类型”标签,包括集合操作(SetOperation)、条件过滤(CondFilter)、计数(COUNT)、极值/排序(Comparative)、单跳推理(Single-hop)、多跳推理(Multi-hop)和星型事实推理(Star-shape)。而“语言类型”标签则反映了用于编写问题的语言。图2展示了本文收集的数据的标签分布情况。 图1 评估框架概述特征驱动的多标签问题分类由于现有数据集通常使用不同的标签来识别答案类型或推理类型等,为了在评估中进行统一分析,我们需要标准化这些特征类型的标签。我们设计了三种类别的标签,包括“答案类型”、“推理类型”和“语言类型”,用于描述复杂问题中包含的特征。这些特征反映了问题中提到的主题类型、获取答案的方式和问题的语言形式。通常,这些特征对应于QA系统的子功能。每个问题通常只包含一个“答案类型”标签。基于使用命名实体识别(NER)定义事实类型的类型定义、基于英语疑问词分类的问题类型分类以及从现有KBQA数据集中归纳出答案类型,我们将答案类型设置为以下八种类型:日期/时间(DATE)、地点(LOC)、人名(PER)、原因(WHY)、是/否(Boolean)、其他事实(MISC)、数字(NUM)或无法回答(UNA)。基于KBQA数据集提供的SPARQL查询,我们还归纳出了八个“推理类型”标签,包括集合操作(SetOperation)、条件过滤(CondFilter)、计数(COUNT)、极值/排序(Comparative)、单跳推理(Single-hop)、多跳推理(Multi-hop)和星型事实推理(Star-shape)。而“语言类型”标签则反映了用于编写问题的语言。图2展示了本文收集的数据的标签分布情况。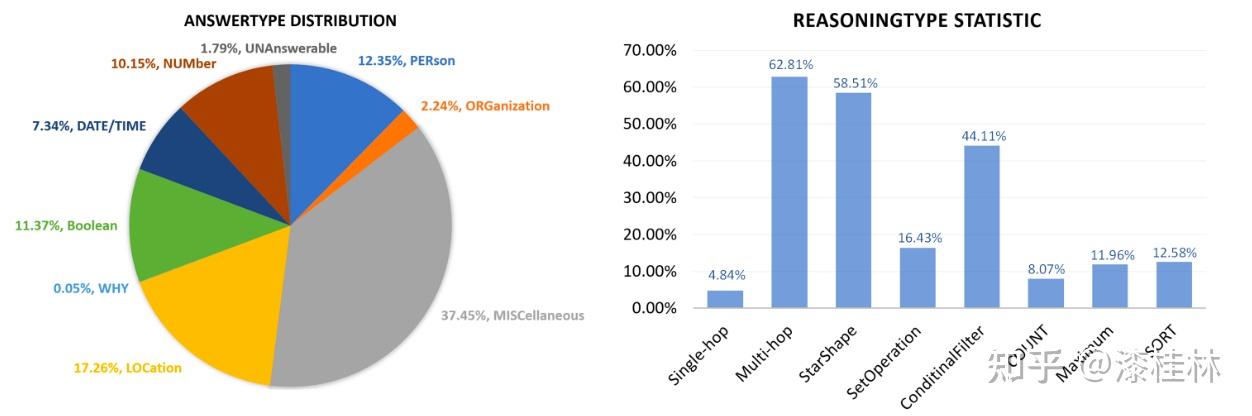 图2: 特征标签在收集的 KB-based CQA 数据集中的分布衡量方法 图2: 特征标签在收集的 KB-based CQA 数据集中的分布衡量方法通常有两种策略来评估基于知识的问答系统(KBQA)的输出:SPARQL匹配和答案匹配。然而,ChatGPT在生成具有统一实体和关系ID的SPARQL查询方面存在困难,使得SPARQL匹配难以自动化。因此,在我们主要实验的QA评估部分中,我们采用了答案匹配策略。作为补充,我们在DIR部分设置了带有SPARQL输出的测试用例,以手动评估ChatGPT识别问题中包含的推理操作的能力。 与现有的KBQA模型不同,ChatGPT在问答场景下的输出一般是一段包含了答案的文本,难以直接与数据集提供的答案做精确匹配从而得到模型的精准率。而由于采样的数据规模较小,已有的ChatGPT评估工作一般通过人工评价来计算模型的性能。因此,我们需要建立一套大部分自动化的答案评测方法。 我们采用了一个朴素的通过扩充匹配范围的思路来强化答案匹配的泛化性,具体包括以下两个操作,如图3所示: 通过成分句法解析树提供的子树标签,可以提取文本答案中的所有名词短语。如图3中所示,我们按照粒度的升序(从单词到名词短语,甚至短句)获得了名词短语列表。通过利用Wikidata和WordNet,我们收集了Golden Answer的其他答案列表,包括多语言的别名和同义词。名词短语列表与答案列表之间的精确匹配显著提高了答案匹配的概括性。对于未能匹配的样本,我们基于短语向量之间的余弦相似度设置了一个阈值,以获取潜在匹配项。超过此阈值的部分随后将进行手动判断其正确性。对于具有“DATE”、“Boolean”和“NUM”类型答案的QA,我们已基于其Golden Answer的特征建立了特殊的判断程序。由于我们的度量方法本质上仍然是精确匹配,因此在实验部分,我们使用准确率(Acc)作为模型之间性能比较的指标。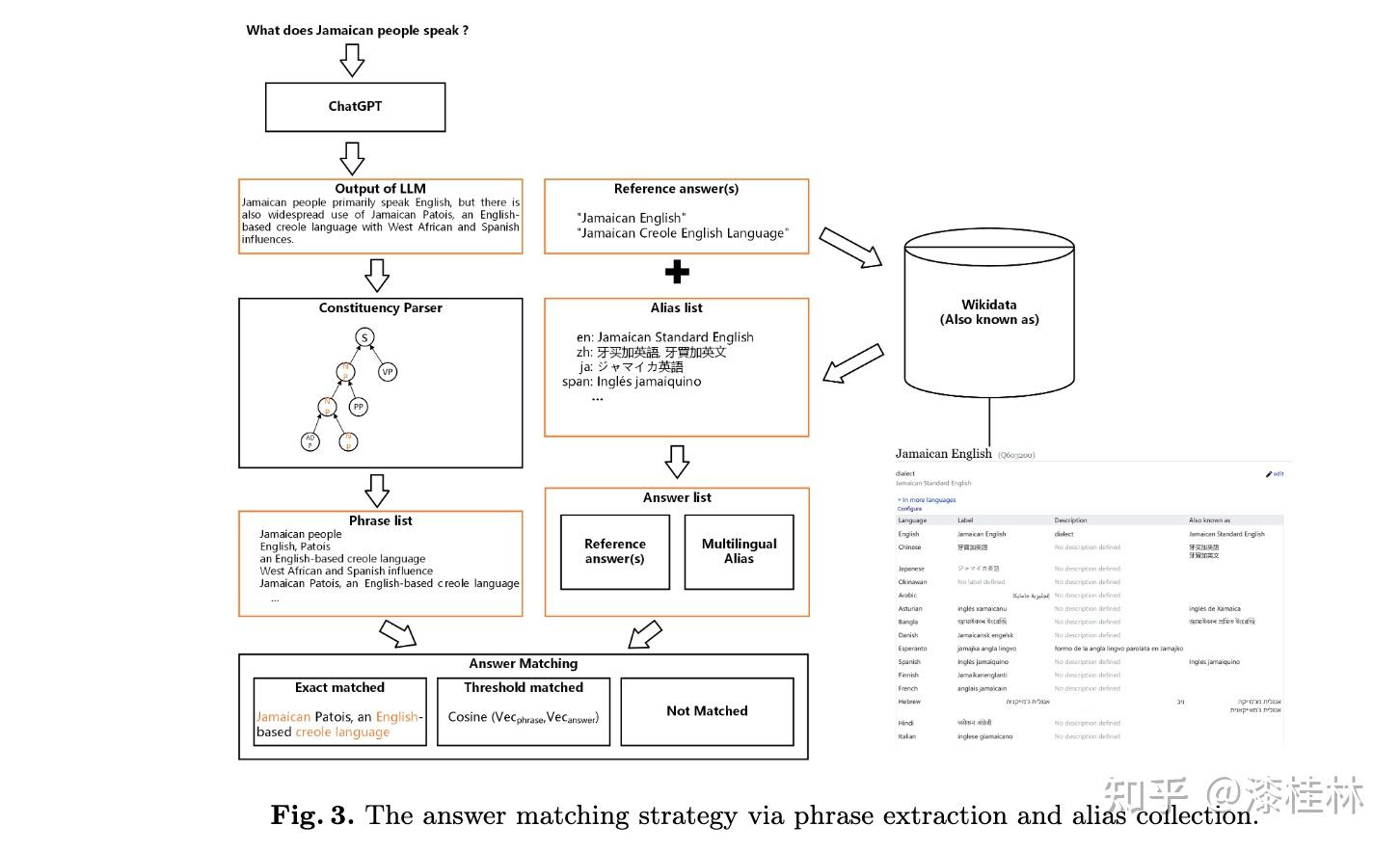 图3: 通过短语提取和别名收集的答案匹配策略基于prompt的CheckList策略参照CheckList 框架的的思路,我们也设置了三个评估目标来评估ChatGPT:通过最小功能测试(MFT)评估LLM在KB-based CQA场景下处理每个特征的能力;通过不变性测试(INV)评估LLM处理KB-based CQA场景中各种特征的能力的稳健性;通过有向期望测试(DIR)评估LLM是否能产生符合人类期望的经过修改的输入输出,即ChatGPT的可控性。 图3: 通过短语提取和别名收集的答案匹配策略基于prompt的CheckList策略参照CheckList 框架的的思路,我们也设置了三个评估目标来评估ChatGPT:通过最小功能测试(MFT)评估LLM在KB-based CQA场景下处理每个特征的能力;通过不变性测试(INV)评估LLM处理KB-based CQA场景中各种特征的能力的稳健性;通过有向期望测试(DIR)评估LLM是否能产生符合人类期望的经过修改的输入输出,即ChatGPT的可控性。图4中给出的一个INV和DIR的测试实例。 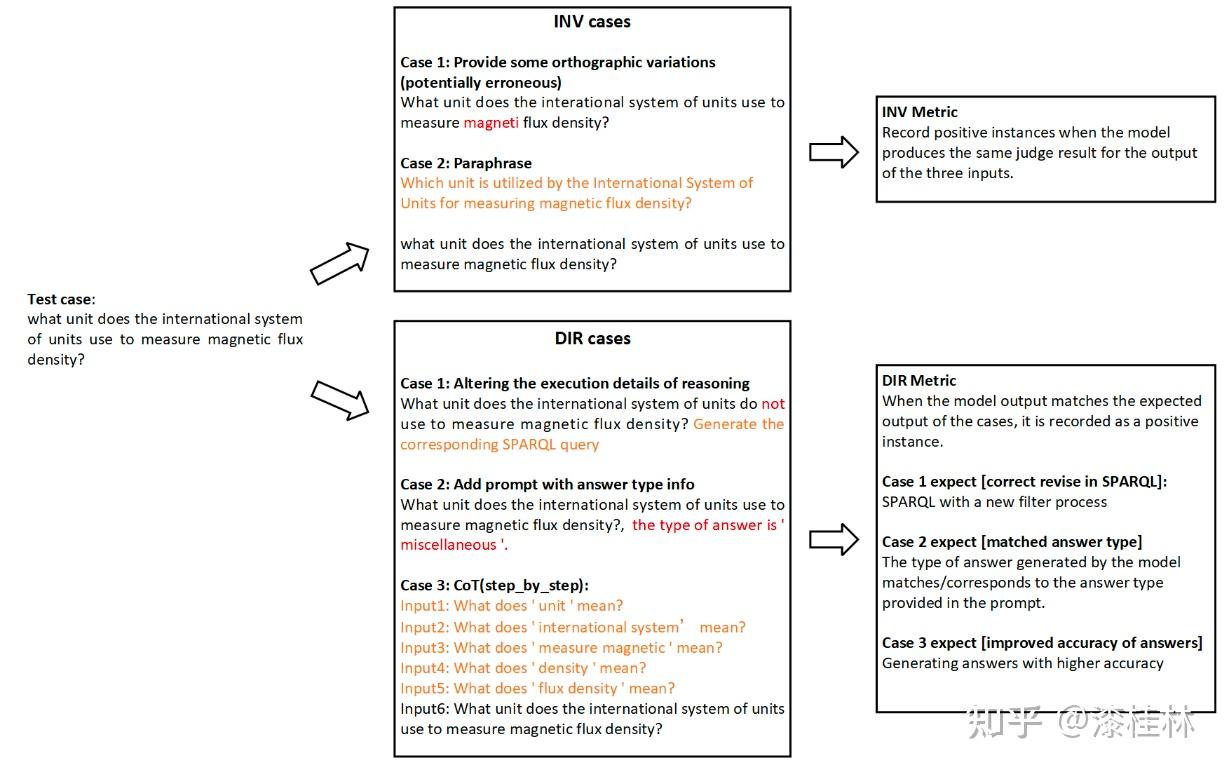 图4: 用于 INV 和 DIR 测试的测试用例设计最小功能测试(MFT) 图4: 用于 INV 和 DIR 测试的测试用例设计最小功能测试(MFT)MFT是一组简单的示例,以及它们各自的标签,旨在验证给定能力中的特定行为。在这项工作中,我们使用标签选择仅包含单一推理类型的样本,并将它们形成MFT测试用例,以检查ChatGPT在执行基本函数(例如“多跳推理”、“计数”、“排序”等)方面的性能。表5提供了测试用例的示例。 不变性测试(INV)INV是指对模型的输入施加微小的扰动,同时期望模型的输出正确性保持不变。不同的扰动函数需要针对不同的能力,例如修改命名实体识别(NER)能力中的地名或引入错别字以评估鲁棒性能力。 在本文中,我们设计了两种方法来生成INV测试用例: 在测试的问题句子中随机引入拼写错误;对测试的问题生成一个语义等效的同义复述的问题。随后,我们通过检查ChatGPT在三个输入(原始测试用例、添加拼写错误的版本和同义复述版本)时产生的输出的一致性来评估ChatGPT的不变性。 定向期望测试(DIR)DIR是类似于INV的方法,其不同之处在于期望标签以某种方式改变。在本研究中,我们探索了三种创建DIR测试用例的方法: 我们替换问题中与推理相关的短语,要求模型生成带有SPARQL查询的答案,以观察ChatGPT的输出逻辑操作是否与我们的修改相对应。我们在输入中添加包含答案类型的提示,以检查ChatGPT是否能够根据提示控制输出答案类型。受到CoT的启发,我们使用通用的多轮提示来重写测试用例,允许ChatGPT通过“逐步”过程获取答案,以观察ChatGPT对不同类型问题的CoT提示的敏感性。实验与分析数据集在这项工作中,我们将ChatGPT和对比语言模型视为带有知识库的无监督问答模型。模型接受自然语言问题作为输入,并生成包含其自身知识覆盖的答案的文本段落。鉴于ChatGPT(以及对比LLM)的训练数据广泛涵盖Wikipedia,我们采用流行的大规模、多语言、开放领域的复杂问答数据集来评估模型,这些数据集与Wikipedia相关。具体来说,我们收集了6个单语言数据集和2个多语言数据集,如下表所示: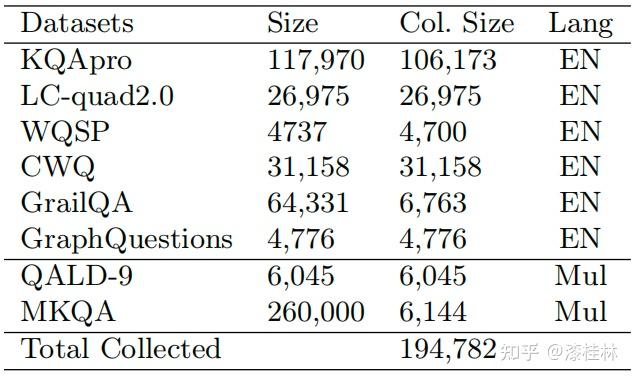 表1 KB-based CQA 数据集的统计对比模型我们对比了目前主流的LLM,包括GPT3(Davinci-001),GPT3.5(Davinci-002,Davinci-003)以及开源的FLAN-T5模型(FLAN-T5-xxl).实验结果主要结果各个模型在数据集上的准确率以及SOTA的对比:我们比较了 ChatGPT 与类似 LLM 的性能,包括 FLAN-T5、GPT3.0 和 GPT3.5 变体,并评估了它们与当前最佳微调 (FT) 和零样本 (ZS) 模型的偏差. 表1 KB-based CQA 数据集的统计对比模型我们对比了目前主流的LLM,包括GPT3(Davinci-001),GPT3.5(Davinci-002,Davinci-003)以及开源的FLAN-T5模型(FLAN-T5-xxl).实验结果主要结果各个模型在数据集上的准确率以及SOTA的对比:我们比较了 ChatGPT 与类似 LLM 的性能,包括 FLAN-T5、GPT3.0 和 GPT3.5 变体,并评估了它们与当前最佳微调 (FT) 和零样本 (ZS) 模型的偏差.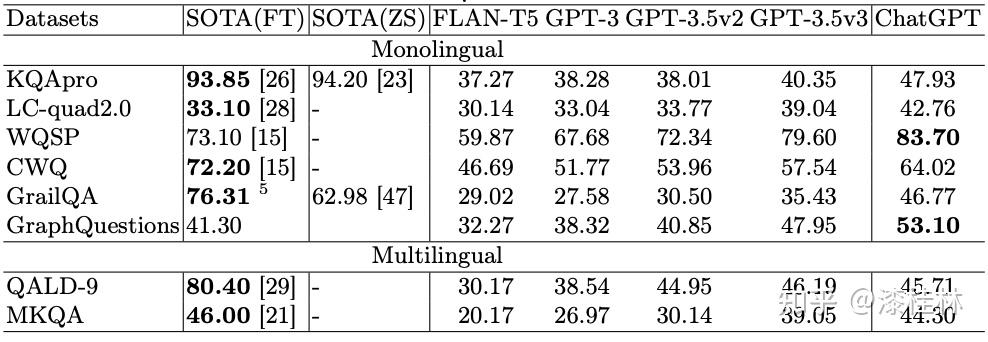 表2 评估的主要结果 表2 评估的主要结果主要实验结果见表2。结果表明,ChatGPT在7个测试数据集上显著优于其他参与的LLM,并在WQSP和GraphQuestions数据集上超越当前的SOTA (Fine-tune)。然而,在其他数据集上,ChatGPT的表现仍然显著劣于传统模型的SOTA,特别是在实体丰富的测试集中,比如KQApro、LC-quad2.0和GrailQA。各个模型在不同答案类型和推理类型问题上的表现: 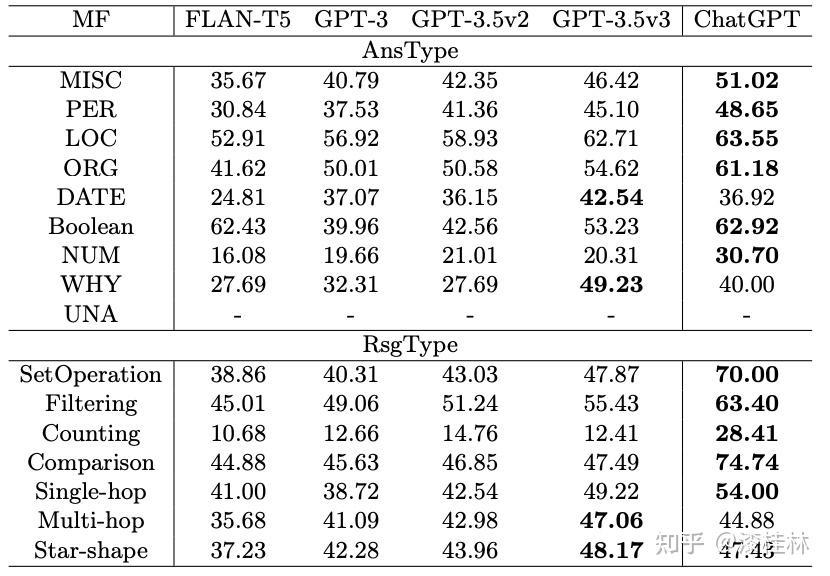 表3 面向答案类型 (AnsType) 和推理类型 (RsgType) 的结果 表3 面向答案类型 (AnsType) 和推理类型 (RsgType) 的结果从答案类型的角度来看:依赖自身训练数据作为知识库的大型语言模型无法准确回答各种基于事实的问题。这在需要数值、因果和时间答案的测试集中尤为明显,所有 LLM 都表现不佳。性能对比上,ChatGPT在大部分问题类型上都优于比较模型,但是在回答答案类型为DATE和WHY的问题时,ChatGPT落后于GPT-3.5 V3。另外在涉及多跳和Star-shape的问题上,ChatGPT也没有展现出突出的优势。从推理类型的角度来看: 参与测试的 LLM 都在 COUNT 类型的问题上表现不佳,这与他们在 NUM 答案类型上的表现是一致的。综上所述,ChatGPT 在某些类型的推理方面的进步几乎是具有突破性的贡献,其在涉及集合运算和比较的问题中的显着卓越准确性 (Acc) 证明了这一点,与其他竞争对手相比,差距超过 20%。原因可能是代码训练的引入显着提高了 ChatGPT 的逻辑推理能力。[20]但是,ChatGPT 在链式多跳推理或星形事实推理方面实际上落后于 GPT-3.5 V3,造成这种现象的原因在于 ChatGPT 无法充分区分它所学的混淆实体。各个模型在各种语言精度上的对比: 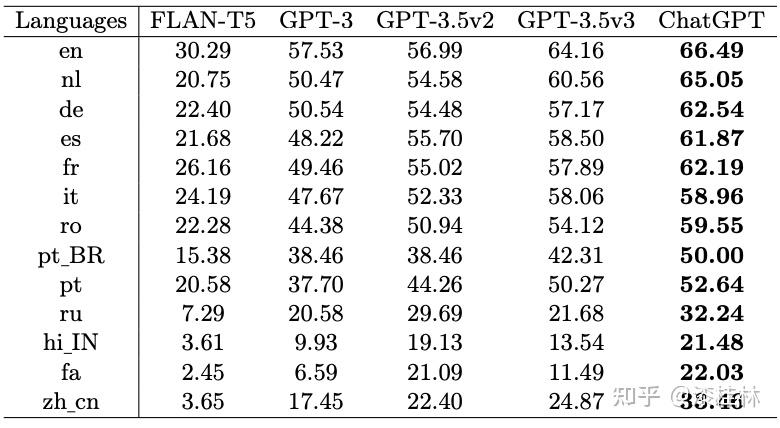 表4 多语言结果 表4 多语言结果多语言测试集上的实验结果表明,ChatGPT在所有语言的测试上都优于对比模型,尤其在低资源语言上的性能领先更为明显。值得注意的是,“fa”和“hi IN”等低资源语言的显著改进反映了 ChatGPT 利用资源丰富的训练数据来增强低资源模型性能的有效性。然而,中文测试中得分较低的情况让我们感到不解,我们无法确定这种情况是由于“中文资源不足”还是“资源质量不佳”造成的。 MFT结果我们选择仅包含单个推理标签或多个标签的测试用例相同类型(例如SetOperation+比较、SetOperation+过滤),并汇总其结果以获得MFT: 表5 最小功能测试(MFT)结果 表5 最小功能测试(MFT)结果值得注意的是,与之前表3的数据做对比,可以发现SetOperation 和 Comparison 任务的性能大幅下降。这一结果表明 ChatGPT 在复合推理中的集合运算或比较中的表现优于单一推理。我们假设这是由于复合推理过程为 ChatGPT 提供了更多的中间信息,从而缩小了其搜索范围。 INV结果下表显示了ChatGPT在抽样测试用例上的三次运行中的性能,评估了每种答案类型和每种推理类型。其中三次的运行结果分别代表原始问题、添加拼写错误和改写句子以后的运行结果。结果的符号解释为:C表示问题是正确回答,而W表示问题没有正确回答或者没有返回任何有用的答案。这个判断过程涉及人工监督,只有当三轮测试的输出一致时,才认为模型在其对应的功能类别中是稳定的。总体而言,这两个表显示 ChatGPT 在复杂的问答任务中表现出大约 79.0% 的可靠性。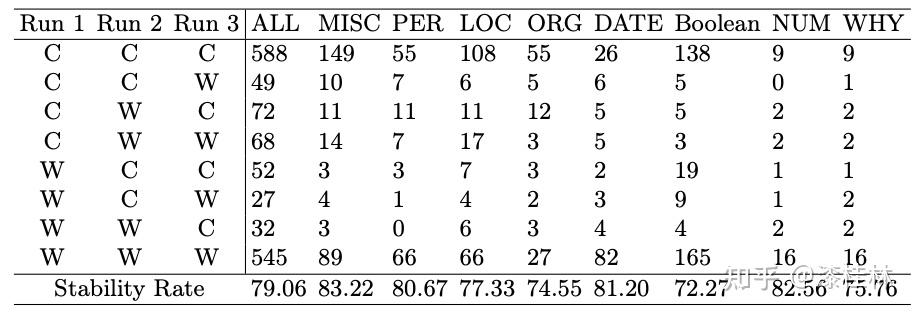 表6 AnsType 的 INV 结果 表6 AnsType 的 INV 结果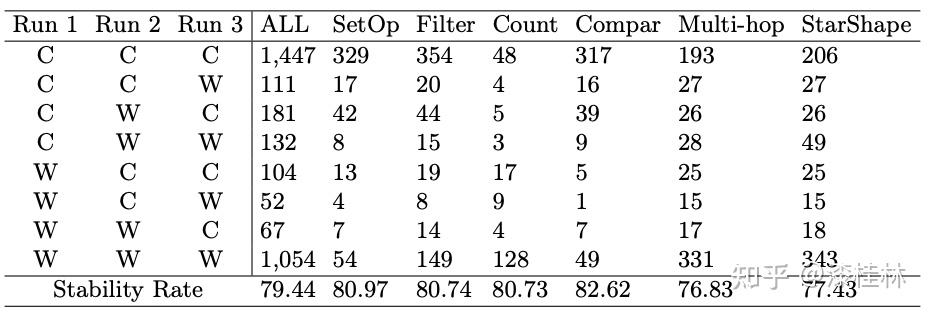 表7 RsgType 的 INV 结果DIR结果 表7 RsgType 的 INV 结果DIR结果我们设计了三种形式的定向期望测试,分别考察ChatGPT在答案类型识别、推理、CoT提示响应方面的能力。首先,对于侧重于答案类型的 DIR 测试,我们使用了一个简单的提示来告知 ChatGPT 当前问题的答案类型,期望它利用此信息将候选答案范围限制为特定类型。如图8所示,结果表明告知答案类型对于具有布尔值和 NUM 答案的问题特别有用。但是,总体而言,我们的提示对大多数问题类型都无效,甚至导致答案类型识别错误较多。 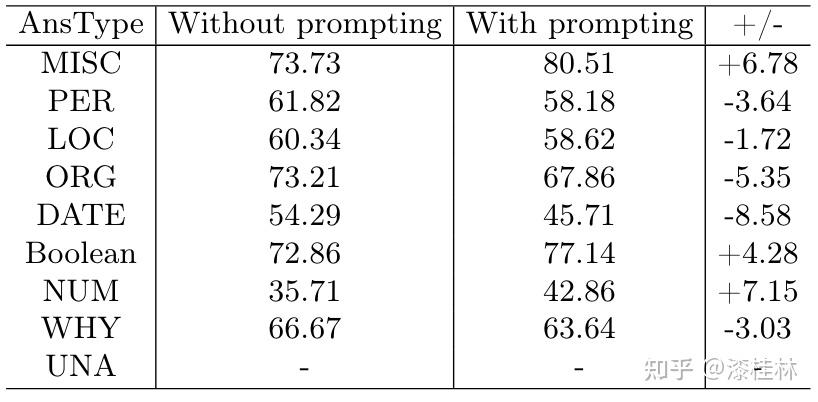 表8 AnsType 提示的 DIR 结果 表8 AnsType 提示的 DIR 结果在针对推理功能的DIR测试中,我们先向ChatGPT输入一对(问题,SPARQL查询),然后修改问题中与推理操作相关的短语,肯定变否定,否定变肯定,在同一个对话轮次中输入到ChatGPT,请求它返回相应的 SPARQL。随后,我们将返回的 SPARQL 与预期的 SPARQL 进行比较。 SPARQL 的匹配过程是手动进行的。为了评估其性能,我们进行了一项测试实验,其中包含针对四种推理类型中的每一种的二十个样本问题:集合运算、条件过滤、计数和比较。评估指标是失败率,它反映了 SPARQL 中输出错误的比例。表 9 中显示的结果表明,在大部分情况下ChatGPT 会对我们的修改提供积极反馈,但是,将此过程用作复杂问答任务的中间步骤可能会导致严重的错误累计。 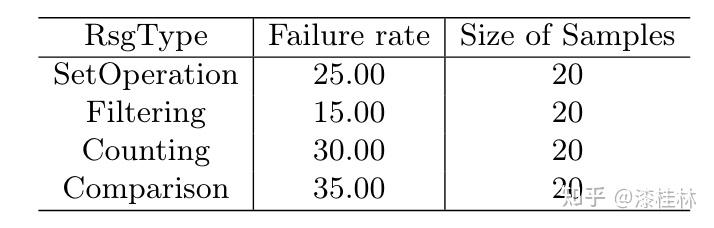 表9 推理类型的DIR结果 表9 推理类型的DIR结果在这项研究中,我们建立了一个简单的 CoT 提示来指导 ChatGPT 在回答复杂问题之前收集与复杂问题相关的信息和概念,也就是句子当中名词。我们认为,这个过程与人类收集信息以回答问题的方式有些相似。表 10 中的结果表明,即使是最简单的 CoT 也可以对大多数类型的问题产生积极影响。特别的是,CoT 导致了 Acc在NUM 类问题的提升超过了 30%,这也体现在 ChatGPT 表现不佳的 COUNT 类问题中。 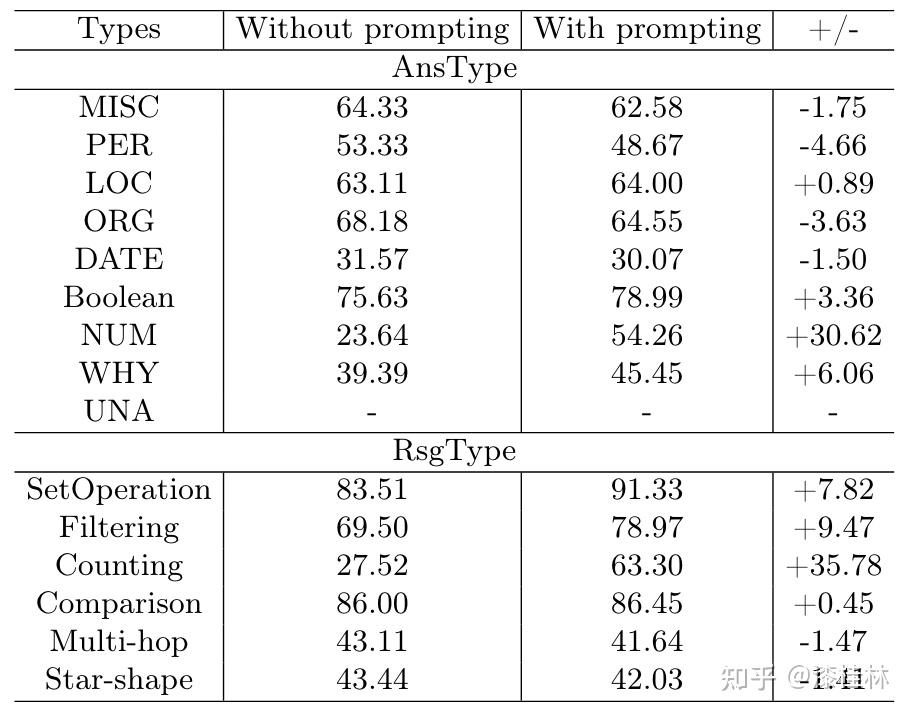 表10 CoT提示的DIR结果结论 表10 CoT提示的DIR结果结论本文介绍了对ChatGPT在回答复杂问题时使用自己的知识库的性能进行大规模实验分析,与类似的大语言模型和当前最先进的模型(SOTA)进行了比较。分析突出了ChatGPT的优点、局限性和不足之处。同时,我们也使用Checklist框架对ChatGPT在处理各种答案类型和推理要求时的基本性能、稳定性和可控性进行了详细的测试和分析。我们相信这些发现将为以ChatGPT为代表的大规模语言模型的开发和下游研究提供有价值的见解和参考。 参考文献1.Ribeiro, M.T., Wu, T., Guestrin, C., Singh, S.: Beyond accuracy: Behavioral testing of nlp models with checklist. In: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. pp. 4902–4912 (2020) 2.Petroni, F., Rocktäschel, T., Riedel, S., Lewis, P., Bakhtin, A., Wu, Y., Miller, A.: Language models as knowledge bases? In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). pp. 2463–2473 (2019) 3.Omar, R., Mangukiya, O., Kalnis, P., Mansour, E.: Chatgpt versus traditional question answering for knowledge graphs: Current status and future directions towards knowledge graph chatbots. arXiv e-prints pp. arXiv–2302 (2023) 4.Bang, Y., Cahyawijaya, S., Lee, N., Dai, W., Su, D., Wilie, B., Lovenia, H., Ji,Z., Yu, T., Chung, W., et al.: A multitask, multilingual, multimodal evaluation of chatgpt on reasoning, hallucination, and interactivity. arXiv e-prints pp. arXiv–2302 (2023) 5.Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E.H., Le, Q.V., Zhou,D., et al.: Chain-of-thought prompting elicits reasoning in large language models.In: Advances in Neural Information Processing Systems 6.He, H., Choi, J.D.: The stem cell hypothesis: Dilemma behind multi-task learning with transformer encoders. In: Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. pp. 5555–5577 (2021) 7.Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J.D., Dhariwal, P., Nee-lakantan, A., Shyam, P., Sastry, G., Askell, A., et al.: Language models are few-shot learners. Advances in neural information processing systems. 33, 1877–1901 (2020) 8.Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C.L., Mishkin, P., Zhang,C., Agarwal, S., Slama, K., Ray, A., et al.: Training language models to follow instructions with human feedback. arXiv e-prints pp. arXiv–2203 (2022) 9.Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li,W., Liu, P.J.: Exploring the limits of transfer learning with a unified text-to-text transformer. The Journal of Machine Learning Research 21(1), 5485–5551 (2020) 10.Rae, J.W., Borgeaud, S., Cai, T., Millican, K., Hoffmann, J., Song, F., Aslanides,J., Henderson, S., Ring, R., Young, S., et al.: Scaling language models: Methods,analysis & insights from training gopher. arXiv e-prints pp. arXiv–2112 (2021) 11.Chowdhery, A., Narang, S., Devlin, J., Bosma, M., Mishra, G., Roberts, A.,Barham, P., Chung, H.W., Sutton, C., Gehrmann, S., et al.: Palm: Scaling language modeling with pathways. arXiv e-prints pp. arXiv–2204 (2022) 12.Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown,A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. arXive-prints pp. arXiv–2206 (2022) 13.Gao, L., Tow, J., Biderman, S., Black, S., DiPofi, A., Foster, C., Golding, L., Hsu,J., McDonell, K., Muennighoff, N., et al.: A framework for few-shot language model evaluation. Version v0. 0.1. Sept (2021) 14.Wang, A., Pruksachatkun, Y., Nangia, N., Singh, A., Michael, J., Hill, F., Levy,O., Bowman, S.R.: Superglue: a stickier benchmark for general-purpose language understanding systems. In: Proceedings of the 33rd International Conference on Neural Information Processing Systems. pp. 3266–3280 (2019) 15.Liang, P., Bommasani, R., Lee, T., Tsipras, D., Soylu, D., Yasunaga, M., Zhang, Y.,Narayanan, D., Wu, Y., Kumar, A., et al.: Holistic evaluation of language models.arXiv e-prints pp. arXiv–2211 (2022) 16.Frieder, S., Pinchetti, L., Griffiths, R.R., Salvatori, T., Lukasiewicz, T., Petersen,P.C., Chevalier, A., Berner, J.: Mathematical capabilities of chatgpt. arXiv e-prints pp. arXiv–2301 (2023) 17.Belinkov, Y., Glass, J.: Analysis methods in neural language processing: A survey.Transactions of the Association for Computational Linguistics 7, 49–72 (2019) 18.Wu, T., Ribeiro, M.T., Heer, J., Weld, D.S.: Errudite: Scalable, reproducible, and testable error analysis. In: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. pp. 747–763 (2019) 19.Wang, A., Pruksachatkun, Y., Nangia, N., Singh, A., Michael, J., Hill, F., Levy,O., Bowman, S.R.: Superglue: a stickier benchmark for general-purpose language understanding systems. In: Proceedings of the 33rd International Conference on Neural Information Processing Systems. pp. 3266–3280 (2019) 20.Fu, Y., Peng, H., Khot, T.: How does gpt obtain its ability? tracing emergent abilities of language models to their sources. Yao Fu’s Notion (2022) 21.Liang, P., Bommasani, R., Lee, T., Tsipras, D., Soylu, D., Yasunaga, M., Zhang, Y.,Narayanan, D., Wu, Y., Kumar, A., et al.: Holistic evaluation of language models. arXiv e-prints pp. arXiv–2211 (2022) 22.Ribeiro, M.T., Wu, T., Guestrin, C., Singh, S.: Beyond accuracy: Behavioral testing of nlp models with checklist. In: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. pp. 4902–4912 (2020) |
【本文地址】