| 分类性能度量指标:准确性(AC)、敏感性(SE)、特异性(SP)、F1评分、ROC曲线、PR(Precision | 您所在的位置:网站首页 › tbdna阳性准确吗 › 分类性能度量指标:准确性(AC)、敏感性(SE)、特异性(SP)、F1评分、ROC曲线、PR(Precision |
分类性能度量指标:准确性(AC)、敏感性(SE)、特异性(SP)、F1评分、ROC曲线、PR(Precision
|
一:比较容易理解的比喻
以糖尿病人的筛查为例。第一个钟形代表正常人,第二个钟形代表糖尿病人。 那理解了上面的解释,先看一下计算公式,咱们再解释: 准确性(AC)、敏感性(SE)、特异性(SP)和F1评分。首先计算真阳性(TP)、真阴性(TN)、假阳性(FP)和假阴性(FN) 在机器学习中,ROC(Receiver Operator Characteristic)曲线被广泛应用于二分类问题中来评估分类器的可信度,但是当处理一些高度不均衡的数据集时,PR曲线能表现出更多的信息,发现更多的问题。 1.ROC曲线和PR曲线是如何画出来的? 在二分类问题中,分类器将一个实例的分类标记为是或否,这可以用一个混淆矩阵来表示。混淆矩阵有四个分类,如下表: 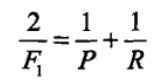 例如:某工厂购进材料三批,每批价格及采购金额资料如下表: 例如:某工厂购进材料三批,每批价格及采购金额资料如下表:  那么调和平均值为: 那么调和平均值为:  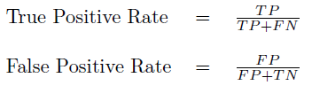 在ROC曲线中,以FPR为x轴,TPR为y轴。FPR指实际负样本中被错误预测为正样本的概率。TPR指实际正样本中被预测正确的概率。如下图: 在ROC曲线中,以FPR为x轴,TPR为y轴。FPR指实际负样本中被错误预测为正样本的概率。TPR指实际正样本中被预测正确的概率。如下图:  在PR曲线中,以Recall(貌似翻译为召回率或者查全率)为x轴,Precision为y轴。Recall与TPR的意思相同,而Precision指正确分类的正样本数占总正样本的比例。如下图: 在PR曲线中,以Recall(貌似翻译为召回率或者查全率)为x轴,Precision为y轴。Recall与TPR的意思相同,而Precision指正确分类的正样本数占总正样本的比例。如下图:
当阈值为0.5时,TPR=6/(6+0)=1,FPR=FP/(FP+TN)=2/(2+2)=0.5,得到ROC的一个坐标为(0.5,1);Recall=TPR=1,Precision=6/(6+2)=0.75,得到一个PR曲线坐标(1,0.75)。同理得到不同阈下的坐标,即可绘制出曲线 在ROC空间,ROC曲线越凸向左上方向效果越好。与ROC曲线左上凸不同的是,PR曲线是右上凸效果越好。 ROC和PR曲线都被用于评估机器学习算法对一个给定数据集的分类性能,每个数据集都包含固定数目的正样本和负样本。而ROC曲线和PR曲线之间有着很深的关系。 定理1:对于一个给定的包含正负样本的数据集,ROC空间和PR空间存在一一对应的关系,也就是说,如果recall不等于0,二者包含完全一致的混淆矩阵。我们可以将ROC曲线转化为PR曲线,反之亦然。 定理2:对于一个给定数目的正负样本数据集,一条曲线在ROC空间中比另一条曲线有优势,当且仅当第一条曲线在PR空间中也比第二条曲线有优势。(这里的“一条曲线比其他曲线有优势”是指其他曲线的所有部分与这条曲线重合或在这条曲线之下。) 证明过程见文章《The Relationship Between Precision-Recall and ROC Curves》 当正负样本差距不大的情况下,ROC和PR的趋势是差不多的,但是当负样本很多的时候,两者就截然不同了,ROC效果依然看似很好,但是PR上反映效果一般。解释起来也简单,假设就1个正例,100个负例,那么基本上TPR可能一直维持在100左右,然后突然降到0.如图,(a)(b)分别为正负样本1:1时的ROC曲线和PR曲线,二者比较接近。而©(d)的正负样本比例为1:1,这时ROC曲线效果依然很好,但是PR曲线则表现的比较差。这就说明PR曲线在正负样本比例悬殊较大时更能反映分类的性能。 AUC(Area Under Curve)即指曲线下面积占总方格的比例。有时不同分类算法的ROC曲线存在交叉,因此很多时候用AUC值作为算法好坏的评判标准。面积越大,表示分类性能越好。 4.混淆矩阵混淆矩阵是除了ROC曲线和AUC之外的另一个判断分类好坏程度的方法。下面给出二分类的混淆矩阵 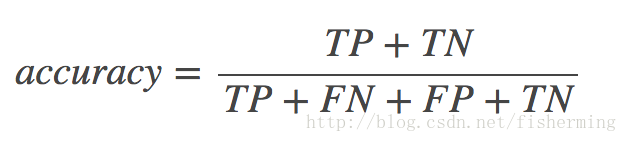 平均准确率(Average per-class accuracy):每个类别下的准确率的算术平均,即: 平均准确率(Average per-class accuracy):每个类别下的准确率的算术平均,即:
参考文章: 对混淆矩阵、F1-Score【机器学习】分类性能度量指标 : ROC曲线、AUC值、正确率、召回率、敏感度、特异度知乎:敏感性和特异性ROC曲线和PR(Precision-Recall)曲线的联系 |
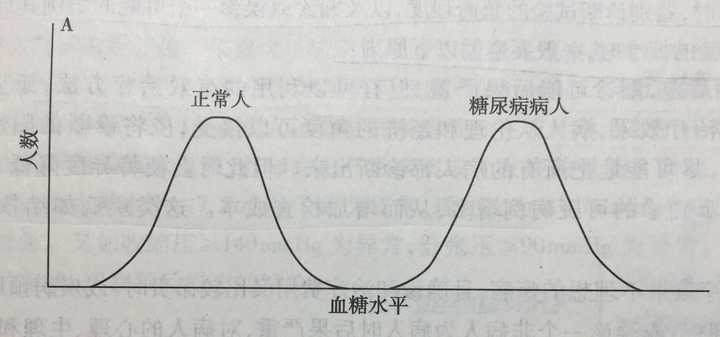 理想中,如果正常人和糖尿病人的血糖范围完全没有重合就好了。这样我就把标准定在中间那个最低点。低于此点的,就是正常人;高于此点的,就是糖尿病人。多好!可惜,现实中,是这样的:
理想中,如果正常人和糖尿病人的血糖范围完全没有重合就好了。这样我就把标准定在中间那个最低点。低于此点的,就是正常人;高于此点的,就是糖尿病人。多好!可惜,现实中,是这样的: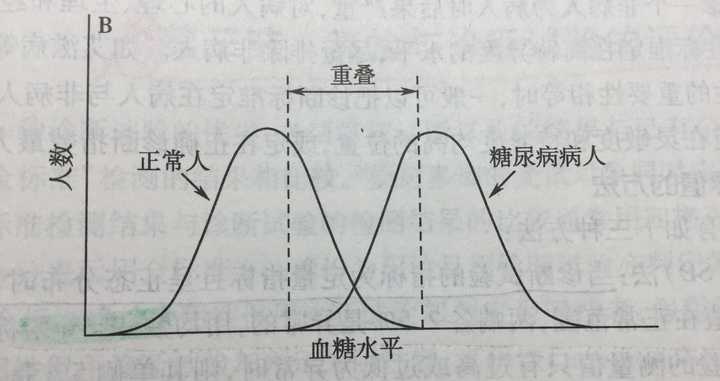 由于人人都是任性的小公举,所以正常人的血糖范围和糖尿病人的血糖范围有一部分是重叠的。那么应该把标准画在哪里比较好呢?如果标准定在左边那条虚线上,凡是低于此点的都是正常人;高于此点的就包括了两类人------糖尿病人和血糖比较高的正常人。这种画法就是灵敏度最高的画法------所以,灵敏度是实际有病而且被正确诊断出来的概率。这种画法没有放过一个患病的人。但是有一部分正常人被认为是糖尿病人了,这一部分叫做假阳性率。
由于人人都是任性的小公举,所以正常人的血糖范围和糖尿病人的血糖范围有一部分是重叠的。那么应该把标准画在哪里比较好呢?如果标准定在左边那条虚线上,凡是低于此点的都是正常人;高于此点的就包括了两类人------糖尿病人和血糖比较高的正常人。这种画法就是灵敏度最高的画法------所以,灵敏度是实际有病而且被正确诊断出来的概率。这种画法没有放过一个患病的人。但是有一部分正常人被认为是糖尿病人了,这一部分叫做假阳性率。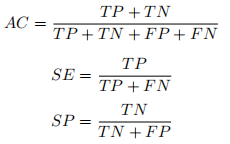
 其中,列对应于实例实际所属的类别,行表示分类预测的类别。
其中,列对应于实例实际所属的类别,行表示分类预测的类别。 绘制ROC曲线和PR曲线都是选定不同阈值,从而得到不同的x轴和y轴的值,画出曲线。例如,一个分类算法,找出最优的分类效果,对应到ROC空间中的一个点。通常分类器输出的都是score,如SVM、神经网络等,有如下预测效果:
绘制ROC曲线和PR曲线都是选定不同阈值,从而得到不同的x轴和y轴的值,画出曲线。例如,一个分类算法,找出最优的分类效果,对应到ROC空间中的一个点。通常分类器输出的都是score,如SVM、神经网络等,有如下预测效果:  True表示实际样本属性,Hyp表示预测结果样本属性,第4列即是Score,Hyp的结果通常是设定一个阈值,比如上表Hyp(0.5)和Hyp(0.6)就是阈值为0.5和0.6时的结果,Score>阈值为正样本,小于阈值为负样本,这样只能算出一个ROC值,
True表示实际样本属性,Hyp表示预测结果样本属性,第4列即是Score,Hyp的结果通常是设定一个阈值,比如上表Hyp(0.5)和Hyp(0.6)就是阈值为0.5和0.6时的结果,Score>阈值为正样本,小于阈值为负样本,这样只能算出一个ROC值, 2.ROC曲线和PR曲线的关系
2.ROC曲线和PR曲线的关系
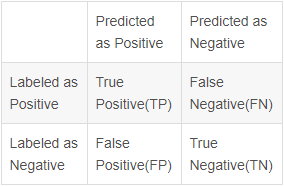 这个矩阵里面的元素我就不再赘述,上面已经讲了, 进一步,由混淆矩阵可以计算以下评价指标:
这个矩阵里面的元素我就不再赘述,上面已经讲了, 进一步,由混淆矩阵可以计算以下评价指标: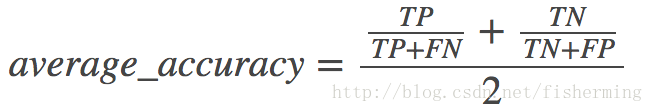
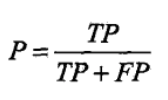
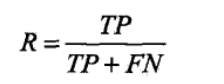
【本文地址】