| 多期DID模型 | 您所在的位置:网站首页 › stata基本回归中模型的各个数字怎么计算 › 多期DID模型 |
多期DID模型
 摘要:基准回归是多期DID模型实证分析过程中不可缺少一步。本文基于1990-1999年模拟面板数据,采用了四种常用的基准回归方法,对基准回归进行了Stata实操演示,并对运行代码进行了解释,最后提供了本文涉及的所有Stata代码,可供读者一键复制使用。 目录 1 DID基准回归介绍 1.1 回归简介 1.2 回归目的 2 Stata实操 2.1 模拟面板数据 2.2 基准回归Stata演示 3 基准回归Stata代码 Note: 第三部分是对第二部分Stata实操代码的汇总,可以复制粘贴,方便一键提取!!!图中的蓝框为标注,红框为代码!!! 1 DID基准回归介绍 1.1 回归简介 基准回归是一种最为基础、最为普通的回归方式,是其他回归的基础。根据研究需求构造合适的基准回归模型,对恰当的样本数据进行参数回归所得到的结果,可称为基准回归结果。基准回归是一种非线性的回归,可以用来评估模型或数据的准确性,也可以用来计算基准回归模型中变量的参数,从而对回归结果进行实证分析。 1.2 回归目的 在DID模型中,基准回归是与平行趋势检验、安慰剂检验、稳健性检验同等重要的,是DID模型分析中不可缺少的一步。通过对DID模型进行基准回归,得到核心解释变量(交互项)的系数,根据系数的符号、大小、显著性来判断所研究政策对被解释变量的影响,进而确定所研究政策的推行对研究个体的影响。此外,可以选择控制变量、个体固定效应、时间固定效应等进行基准回归,通过比较不同设定下核心解释变量系数的大小和显著性,以确定最合适的DID模型进行实证研究。 2 Stata实操 2.1 模拟面板数据 2.1.1 面板数据格式  本次Stata实操的面板数据格式为:“一对多”,即一个研究个体对应了多个年份数据。例如在上图中,国家A对应了1990—1999年的数据。其中,id为研究个体数值编号;country为研究个体国家;y为被解释变量;x1、x2、x3皆为控制变量。  基础数据.dta,id为国家编号;treat虚拟变量,执行政策(处理组)为1,不执行政策(控制组)为0;time为政策执行时间,对于控制组time为2222,目的在于区分处理组。 2.1.2 模拟数据样本  模拟数据共有70个样本,涉及研究个体7个,每个个体对应10年的研究数据。国家A、D、F政策执行时间为1994年,国家C政策执行时间为1998年。 2.2 基准回归Stata演示 2.2.1 创建面板数据 代码:  在对面板数据进行基准回归前,需要先使用代码xtset创建面板数据,否则回归会报错。“strongly balanced”说明面板数据是平衡数据。 2.2.2 构造核心解释变量(交互项) (1)方法一_匹配法 代码:  将基础数据.dta导入面板数据中,从而可以在不同政策执行年份下构造核心解释变量(交互项)did,后续操作中的核心解释变量(交互项)皆为此。 运行结果:  方法二_直接构造法 方法二_直接构造法代码:  td为核心解释变量(交互项),后续操作中的核心解释变量为方法一中构造的did。 运行结果:  很明显可以看出,国家A与国家C政策执行时间不同,其构造出的交互项也不同。 2.2.3 基准回归 (1)方法一_非聚类回归_高维回归 代码:   未安装的读者首先运用ssc install下载外部命令reghdfe。 运行结果:  (2)方法二_非聚类回归_面板回归 代码:  运行结果: 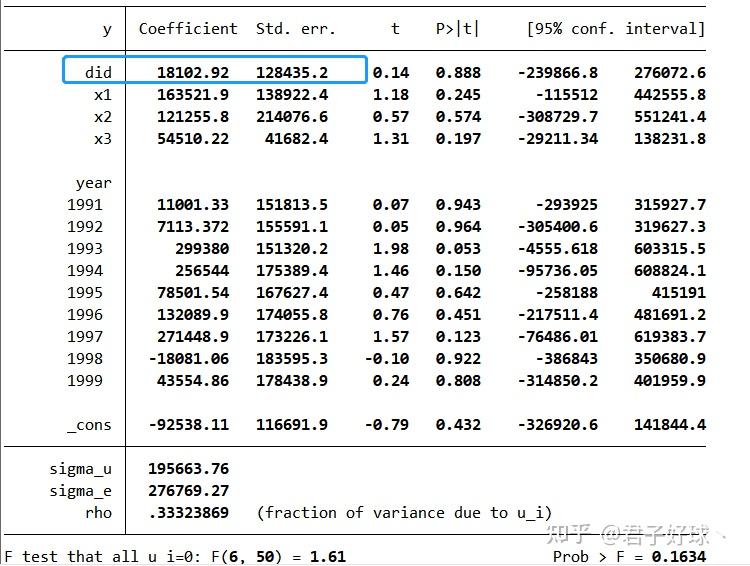 (3)方法三_聚类回归_高维回归 代码:  运行结果:  (4)方法四_聚类回归_面板回归 代码:  运行结果:  四种基准回归方法的“政策效应”都相同,只是在标准误上有略微差距。 3 基准回归Stata代码 ------------------------------------------------------------------------------------------------------- Note: 强烈推荐将上述代码整体复制粘贴到do.文件中查看,效果更加!!!年份、变量根据自身情况替换!!!设置虚拟变量、基准回归的命令包含但不限于本文中的,本文仅供参考!!!本文如有错误和不足,请多多包涵、批评指正,纯是个人理解及错误!!!欢迎互相学习!!! 关注·点赞·收藏·转发 请勿抄袭,违者必究! |
【本文地址】