| 【精选】SQL:from、where、group by、having、order by的书写与执行顺序 | 您所在的位置:网站首页 › sql字句执行顺序 › 【精选】SQL:from、where、group by、having、order by的书写与执行顺序 |
【精选】SQL:from、where、group by、having、order by的书写与执行顺序
|
1、SQL的书写顺序与执行顺序
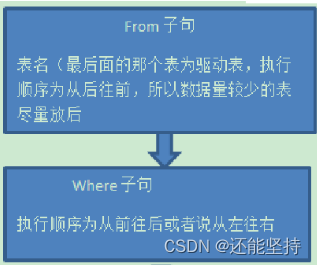
查询中用到的关键词主要包含六个,并且他们的书写顺序依次为: select>from>where>group by>having>order by,其中select和from是必须的,其他关键词是可选的这六个关键词的执行顺序与sql语句的书写顺序并不是一样的,而是按照下面的顺序来执行:from>where>group by>having>select>order by
from:需要从哪个数据表检索数据where:过滤表中数据的条件group by:如何将上面过滤出的数据分组having:对上面已经分组的数据进行过滤的条件select:查看结果集中的哪个列,或列的计算结果order by:按照什么样的顺序来查看返回的数据
当一个查询语句同时出现了where,group by,having,order by的时候,执行顺序和编写顺序是: 1.执行where xx对全表数据做筛选,返回第1个结果集。2.针对第1个结果集使用group by分组,返回第2个结果集。3.针对第2个结集执行having xx进行筛选,返回第3个结果集。4.针对第3个结果集中的每1组数据执行select xx,有几组就执行几次,返回第4个结果集。5.针对第4个结果集排序。数据库SQL语句中 where,group by,having,order by的执行顺序 2、from与where 2.1 from from后面的表关联,是自右向左解析的 from后面需要接多个表,尽量把数据量小的表放在最右边来进行关联(用小表去匹配大表)
更加详细的解释: 可以这样去理解group by和聚合函数 在使用group by的时候,select位置处一般会有聚合语句(例如sum),一些没有聚合的字段必须要加到group by 后边。比如,select a,sum(b) from A group by a //后边必须要有a,否则报错。 关于sql:必须出现在GROUP BY子句中或在聚合函数中使用 3.2.2 常用聚合函数 count() 计数sum() 求和avg() 平均数max() 最大值min() 最小值 3.2.3 SQL中只要用到聚合函数就一定要用到group by 吗?(不一定)当只做聚集函数查询时候,就不需要进行分组了 SELECT SUM(TABLE.A ) FROM TABLE 上述SQL不需要使用Group by 进行分组,因为其中没有非聚合字段,所以不用Group by 也可以。 当聚集函数(sum(B))和非聚集字段(A)出一起出现时,需要将非聚集字段(A)进行group by,分组之后你可以计数(COUNT),求和(SUM),求平均数(AVG)等。 SELECT TABLE.A , MAX(TABLE.B) FROM TABLE GROUP BY TABLE.A 由于B是非聚合字段,则需要使用MAX()或者其他聚合函数进行处理 3.2.4 Group by 与 Distinct 的区别原先代码 自己修改后的代码 CREATE TABLE IF NOT EXISTS `test_users` ( `email_id` int(11) unsigned NOT NULL auto_increment, `email` char(100) NOT NULL, `passwords` char(64) NOT NULL, PRIMARY KEY (`email_id`) ) ENGINE=MyISAM DEFAULT CHARSET=utf8 AUTO_INCREMENT=6 ; INSERT INTO `test_users` (`email_id`, `email`, `passwords`) VALUES (1, '[email protected]', '1e48c4420b7073bc11916c6c1de226bb'), (2, '[email protected]', '5294cef9f1bf1858ce9d7fdb62240546'), (3, '[email protected]', '5294cef9f1bf1858ce9d7fdb62240546'), (4, '[email protected]', null), (5, '[email protected]', null), (6, null, null), (7, null, null); 如果只是为了去重,那么意义是一样的(Group by效率高)group by应用的范围更广泛一些,如分组汇总,或者从聚合函数里筛选数count,distinct和group by对null值的操作distinct 会将选中的所有null视为一项 格式:select distince a,b from talbleName 使用:SELECT DISTINCT email,passwords FROM test_users WHERE 1 = 1 ,输出: group by 将选中的所有null视为一项 格式:select a, b from tableName groupby a,b 使用:SELECT email, passwords, COUNT(*) FROM test_users WHERE 1 = 1 GROUP BY email,passwords 输出: count 不会计算null值项,count(null)=0 1.count(1)与count(*)得到的结果一致,包含null值。 2.count(字段)不计算null值 3.count(null)结果恒为0 select count(*) from test_users union all SELECT count(distinct email, passwords) FROM test_users union all select count(*) from ( SELECT email,passwords FROM test_users group by email,passwords ) a;
我们现在有一张dept_emp表共四个字段,分别是emp_no(员工编号),dept_no(部门编号),from_date(起始时间),to_date(结束时间),记录了员工在某一部门所处时间段,to_date等于9999-01-01的表示目前还在职。 
我们上一步分组之后得到的结果是部门编号,下一步我们可以通过departments去关联出部门名称,语句如下: 筛选在职员工 where to_date=‘9999-01-01’;对部门进行分组group by dept_no对员工进行计数 count(emp_no),关联departments表找处部门名字SELECT (SELECT d.dept_name FROM departments d WHERE de.dept_no = d.dept_no) AS 部门, count(de.emp_no) AS 人数 FROM dept_emp de WHERE de.to_date = '9999-01-01' GROUP BY de.dept_no // ❌❌❌❌错误做法(dept_emp表没有部门名字)❌❌❌❌ SELECT de.dept_name AS 部门, count( de.emp_no ) AS 人数 FROM dept_emp de WHERE de.to_date = '9999-01-01' GROUP BY de.dept_no
我们现在有一张dept_emp表共四个字段,分别是emp_no(员工编号),dept_no(部门编号),from_date(起始时间),to_date(结束时间),记录了员工在某一部门所处时间段,to_date等于9999-01-01的表示目前还在职。  5、order by
5.2 升序或降序排列
根据输入的多个字段,按照升序或降序排列
5、order by
5.2 升序或降序排列
根据输入的多个字段,按照升序或降序排列
出错代码 改正后的代码 讨论:若不使用Distinct关键字,则order by后面的字段不一定要放在seletc中 |



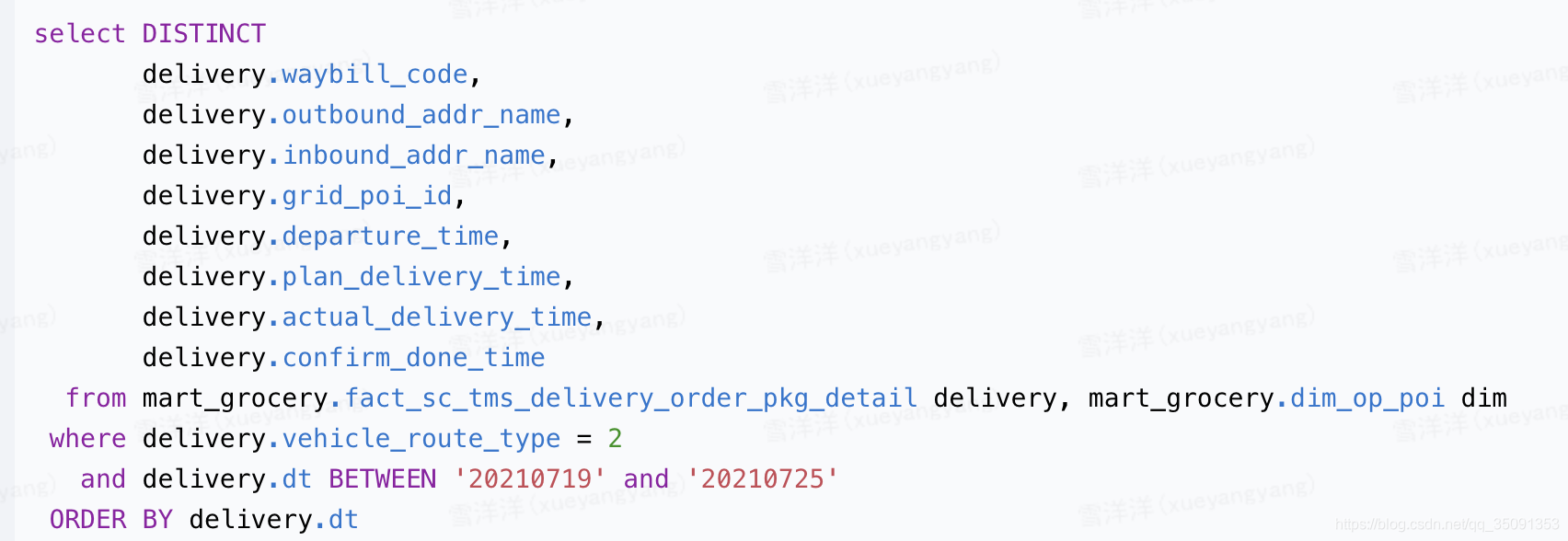
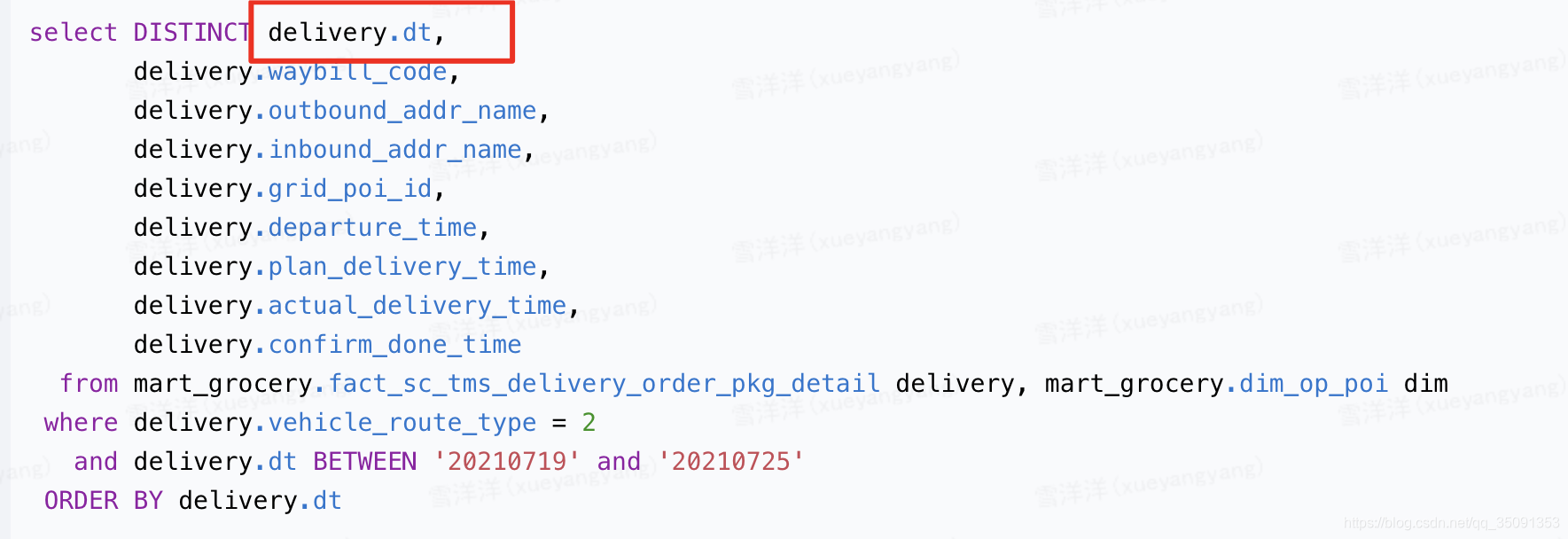
 我们现在想知道每个部门有多少名在职员工,步骤如下:
我们现在想知道每个部门有多少名在职员工,步骤如下:

【本文地址】