| Split() | 您所在的位置:网站首页 › split例句 › Split() |
Split()
|
今天是圣诞节,我是中国人,无视圣诞节。 文章可能有点长,看下来必定有所收获。 没有学过正则表达式的去b站看,一个半小时应该可以看完,要看请点这里 这是必备的前置技能,不懂得话没法真正明白split用法 方法1:split(String regex)split()方法:分割字符串,参数regex称为分割符,可以使用正则表达式来表示 public String[] split(String regex) { return split(regex, 0); } 入门案例1分割符可以是任意字母,符号,数字,字符串等等,这个基本都会 @Test public void splitDemo1(){ String str= "1a2"; String[] split = str.split("a"); //split:{"1","2"} for (int i = 0; i String str= "a33b444c555d"; //正则表达式中\d+表示一个或多个数字,java中\\表示一个普通\ //String[] split = str.split(Pattern.compile("\\d+").toString()); //两种写法都是一样的,下面写法简洁 String[] split = str.split("\\d+"); for (int i = 0; i String str= "aaa|bbb|ccc"; //使用|作为分隔符,其余特殊字符同理 String[] split = str.split("\\|"); for (int i = 0; i String str= "aaa,bbb#ccc"; //使用,和#分割字符串 String[] split = str.split(",|#"); for (int i = 0; i String str= "19997"; String[] split = str.split("9"); for (int i = 0; i String str= "yky"; String[] split = str.split("y"); System.out.println(split.length); System.out.println(Arrays.toString(split)); }运行结果: 2 [, k] //按照我们的结论,返回的数组应该是["",k,""]才对其实不是结论错了,而是参数limit的问题,接下来 点进去split方法查看,发现调用的是另一个重载方法split(String regex, int limit) 分割时末尾的字符串被丢弃了 public String[] split(String regex) { return split(regex, 0); //3.如果 n = 0,匹配到多少次就切割多少次,数组可以是任何长度,并且结尾空字符串将被丢弃。 } 方法2:split(String regex,int limit) public String[] split(String regex) { return split(regex, 0); }可以看出只填一个正则表达式的话,limit默认是0,regex表示正则表达式,limit参数控制分割的次数 limit用法:1.如果 limit > 0,(从左到右)最多分割 n - 1 次,数组的长度将不会大于 n,结尾的空字符串不会丢弃 2.如果 limit < 0,匹配到多少次就分割多少次,而且数组可以是任何长度。结尾的空字符串不会丢弃 3.如果 limit = 0,匹配到多少次就分割多少次,数组可以是任何长度,并且结尾空字符串将被丢弃。 也就是说,使用split方法时,如果只填一个正则表达式,结尾空字符串将被丢弃 看看源码大概怎么说的 ArrayList matchList = new ArrayList(); //...... int resultSize = matchList.size(); if (limit == 0) while (resultSize > 0 && matchList.get(resultSize-1).equals("")) resultSize--; String[] result = new String[resultSize]; //...先从ArrayList的长度开始遍历,如果发现是空字符串,则长度-1,该长度也等于字符串数组的长度 进阶案例: limit>0限制分割次数1.如果 limit > 0,(从左到右)最多分割 limit - 1 次,数组的长度将不会大于limit,结尾的空字符串不会丢弃 limit=1,分割0次,即不分割,将原字符串装进数组并返回 limit如果太大超出了匹配次数,匹配到多少次就分割多少次 String[] split = "abc".split("b",999); //limit=999,但是b只匹配到一次,所以只能分割一次 //split:{"a","c"} String[] split2 = "abc".split("b",1); //不切割 //split2:{"abc"}结尾的空字符串不会丢弃 @Test public void demo1(){ //limit=3,切割2次,末尾会分割出一个""空字符串 String[] split = "abcb".split("b",3); System.out.println(split.length); //数组长度是3 //split:{"a","c",""} } limit //分割符是#,但是只要#后面跟123的那个#,其余#不要 String str= "22222#123#2234"; String[] split = str.split("#(?=123)"); for (int i = 0; i //\r\n在window时回车+换行的意思 String str = "#第一章\r\n#第二章"; Pattern pattern =Pattern.compile("^#",Pattern.MULTILINE); String[] split = str.split(pattern.toString(),-1); //String[] split = str.split("^#",-1); for (int i = 0; iidea通过快捷键crtl + alt + B看接口的实现关系 运行结果 str数组的长度是:4 str2数组的长度是:4 str3数组的长度是:4 str4数组的长度是:2 str5数组的长度是:2结论:除了字符串开头是行首,\r,\n,\r\n后面都可以当成行首 $表示匹配字符串结束的地方,开启多行模式后,每一行都相当于一个字符串 \r,\n,\r\n前面,和字符串最末尾都可以当成行尾被匹配到 @Test public void demo3(){ Pattern pattern =Pattern.compile("章$",Pattern.MULTILINE); String str = "#第一章\r\n#第二章\r\n#第三章"; String[] split = pattern.split(str, -1); System.out.println("数组的长度是:"+split.length); for (int i = 0; i < split.length; i++) { System.out.print(split[i]); } }运行结果 数组的长度是:4 #第一 #第二 #第三 学以致用写这么多不是白写的,真正使用的地方到了,也是我研究正则表达式一天的目的:整理md文档 读写文件用到io流,这里推荐hutool工具包,方便快捷,先导入依赖 cn.hutool hutool-all 5.5.4代码: /** * * @param src 文件的来源 * @param dest 文件目的地 */ public void mdTitleClean(String src,String dest){ //默认UTF-8编码,可以在构造中传入第二个参数做为编码 //输入流:将md文档一次性读进内存,返回一个String FileReader fileReader = new FileReader(src); String result = fileReader.readString(); StringBuilder sb=new StringBuilder(); //输出流,将字符串打印到文件中,该流使用完会自动关闭 FileWriter writer = new FileWriter(dest); //md标题一共有6级,#空格后面写标题,我们想匹配到这个位置,所以是(?=(^#{1,6}\s+)) Pattern p =Pattern.compile("^\\r?\\n(?=(^#{1,6}\\s+))",Pattern.MULTILINE); String[] split = p.split(result); for (int i = 0; i continue; } //先清除字符串前后的所有空格,空行,再加4个\r\n,相当于每个标题之间空三行 sb.append(split[i].trim()).append("\r\n\r\n\r\n\r\n"); } writer.write(sb.toString()); System.out.println(sb.toString()); }代码不难,只需要解释两行 Pattern p =Pattern.compile("\r?\n(?=(#{1,6}\s+))",Pattern.MULTILINE); 用到了前面讲的零宽断言字符边界 隔开之后先清除前后空格,再拼接4个\r\n(统一格式),表示每个标题之间空三行 最终效果图 补充一点中文标点符号替换成英文的,要使用io流,记得导hutool工具包依赖 /** * 英文标点符号替换成中文的 * * @param str * @return */ public String punctuationMarksAlter(String str) { str = str.replaceAll("(", "(") .replaceAll(")", ")") .replaceAll(";", ";") .replaceAll("'", "'") .replaceAll("'", "'") .replaceAll(""", "\"") .replaceAll(""", "\"") .replaceAll(":", ":") .replaceAll("?", "?") .replaceAll("[", "[") .replaceAll("]", "]") .replaceAll("!", "!") .replaceAll(".", ".") .replaceAll(",", ","); return str; } /** * * @param src 文件的来源 * @param dest 文件目的地 */ public void mdClean(String src,String dest){ //默认UTF-8编码,可以在构造中传入第二个参数做为编码 FileReader fileReader = new FileReader(src); String result = fileReader.readString(); StringBuilder sb=new StringBuilder(); FileWriter writer = new FileWriter(dest); //md标题一共有6级,#空格后面写标题内容,我们想匹配到这个位置,所以是(?=(^#{1,6}\s+)) Pattern p =Pattern.compile("^\\r?\\n(?=(^#{1,6}\\s+))",Pattern.MULTILINE); String[] split = p.split(result); for (int i = 0; i continue; } //先清除字符串前后的所有空格,空行,再加4个\r\n,相当于每个标题之间空三行 sb.append(split[i].trim()).append("\r\n\r\n\r\n\r\n"); } //中文标点换成英文的 String string = this.punctuationMarksAlter(sb.toString()); writer.write(string); }逻辑可以自行完善 如果把文档看成一个String字符串,那么就可以写java代码来自动整理md文档的格式了,而不用手动调格式,节约时间精力,更多的时间就可以花在学习上。 split讲解到此为此,希望有所收获~ 上篇正则表达式的笔记我已经写好了,但是md图片粘贴在csdn上太麻烦,有时间再弄了。没有学过正则表达式的去b站看,一个半小时应该可以看完,要看请点这里 从圣诞中午12点研究现在的时间是:2020年12月26日01:34:52,虽累也值得 2020年12月28日19:34:21 开始学习jvm中篇[来自b站尚硅谷免费视频] 自从学了正则表达式之后,可以很快速地替换文本 比如下面是笔记的标题 第十八章:Class文件结构 01-JVM中篇内容概述 02-字节码文件的跨平台性 03-了解Java的前端编译器 04-透过亨节码看代码执行细节举例1 05-话过字节码看代码执行细节举例2 06-透过字节码看代码执行细节举例3 07-解读Class文件的三种方式 08-Class文件本质和内部数据类型 09-Class文件内部结构概述 10-字节码数据保存到excel中的操作 11-Class文件的标识:魔数 12-Class文件版本号 13-常量池概述 14-常量池计数器 15-常量池表中的字面量和符号引用 16-解析得到常量池中所有的常量 17-常量池表数据的解读1 18-常量池表数据的解读2 19-常量池表项数据的总结 20-访问标识 21-类索引、父类索引、接口索引集合 22-字段表集合的整体理解 23-字段表数据的解读 24-方法表集合的整体理解 25-方法表数据的解读 26-屈性表集合的整理理解 27-方法中Code属性的解读 28-LineNumberTable和LocalVariableTable属性的解读 29-SourceFile属性的解读 30-Class文件结构的小结 31-javac -g操作的说明 32-javap主要参数的使用 33-javap解析得到的文件结构的解读 34-javap使用小结 第十九章:字节码指令集与解析举例 35-字节码指令集的概述 36-指令与数据类型的关系及指令分类 37-加载与存储指令概述 38-再谈操作数栈与局部变量表 39-局部变量压栈指令 40-常量入栈指令 41-出栈装入局部变量表指令 42-算术指令及举例 43-算法指令再举例 44-彻底搞定++运算符 45-比较指令的说明 46-宽化类型转换 47-窄化类型转换 48-创建类和数组实例的指令 49-字段访问指令 50-数组操作指令 51-类型检查指令 52-方法调用指令 53-方法返回指令 54-操作数栈管理指令 55-比较指令 56-条件跳转指令 57-比较条件跳转指令 58-多条件分支跳转指令 59-无条件跳转指令 60-抛出异常指令 61-异常处理与异常表 62-同步控制指令 第二十章:类的加载过程详解 63-类的生命周期概述 64-加载完成的操作及二进制的获取方式 65-类模型与Class实例的位置 66-链接之验证环节 67-链接之准备环节 68-链接之解析环节 69-初始化过程与类初始化方法 70-初始化阶段赋值与准备阶段赋值的对比 71-类初始化方法clinit(的线程安全性 72-何为类的主动使用和被动使用 73-类的主动使用1 74-类的主动使用2 75-类的主动使用3 76-类的主动使用4 77-类的被动使用 78-类的使用介绍 79-类的卸载相关问题 第二十一章:再谈类的加载器 80-类加载器的概述 81-命名空间与类的唯一性 82-类的加载器的分类 83-引导类加载器的说明 84-扩展类加载器的说明 85-系统类加载器的说明 86-用户自定义类加载器的说明 87-测试不同类使用的类加载器 88-ClassLoader与Launcher的初步剖析 89-ClassLoader的源码解析1 90-ClassLoader的源码解析2 91-ClassLoader子类的结构剖析 91-ClassLoader子类的结构剖析 92-双亲委派机制的优势与劣势 93-三次双亲委派机制的破坏 94-热替换的代码实现 95-沙箱安全机制 96-自定义类加载器的好处和应用场景 97-自定义类加载器的代码实现 98-Java9的新特性我们想要在每一行的前面加个#,意思是一级标题,就不用自己手动加了,使用正则表达式轻而易举的事 |
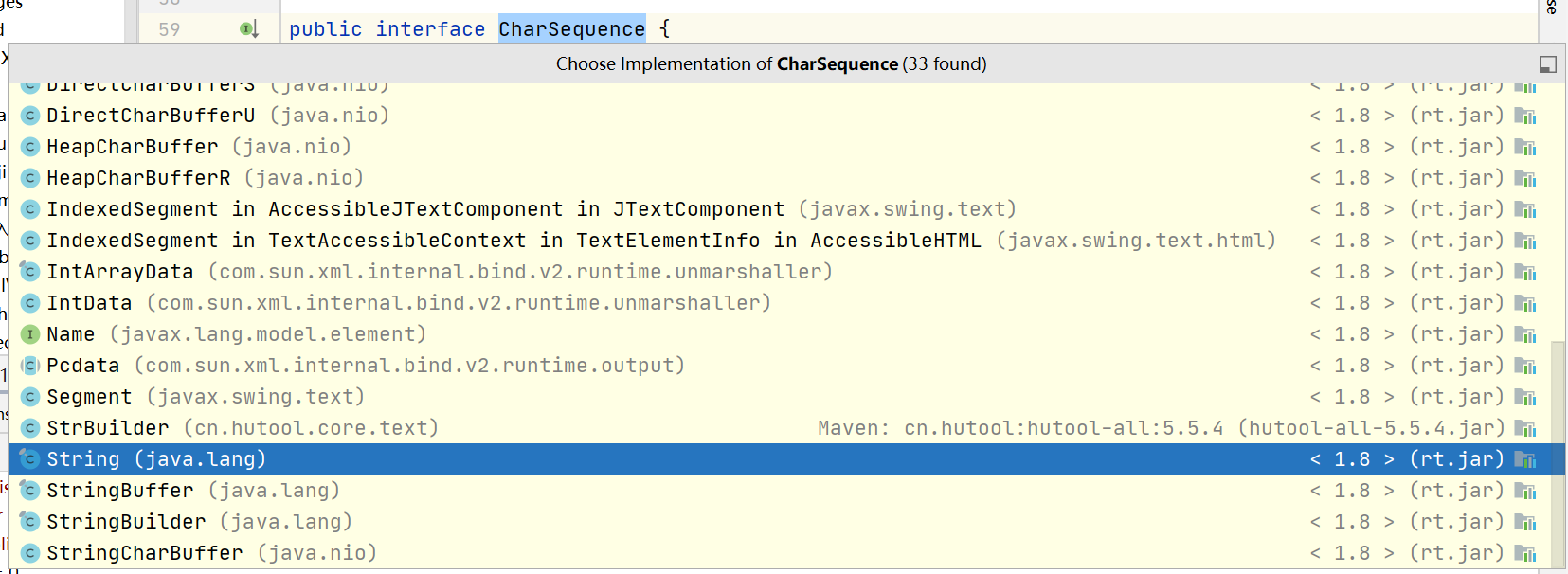 我发现String类实现了这个CharSequence接口,那参数的意思是输入一个String字符串,而匹配规则已经写在Pattern类里了。
我发现String类实现了这个CharSequence接口,那参数的意思是输入一个String字符串,而匹配规则已经写在Pattern类里了。 ^\r?\n表示字符串开头是换行符 (?=(^#{1,6}\s+)) 表示匹配开头是# ,## ,### 的位置,即一级标题-六级标题 最终的效果是以一级标题-六级标题前面的\r\n作为分隔符,把整个文档按照标题进行隔开。
^\r?\n表示字符串开头是换行符 (?=(^#{1,6}\s+)) 表示匹配开头是# ,## ,### 的位置,即一级标题-六级标题 最终的效果是以一级标题-六级标题前面的\r\n作为分隔符,把整个文档按照标题进行隔开。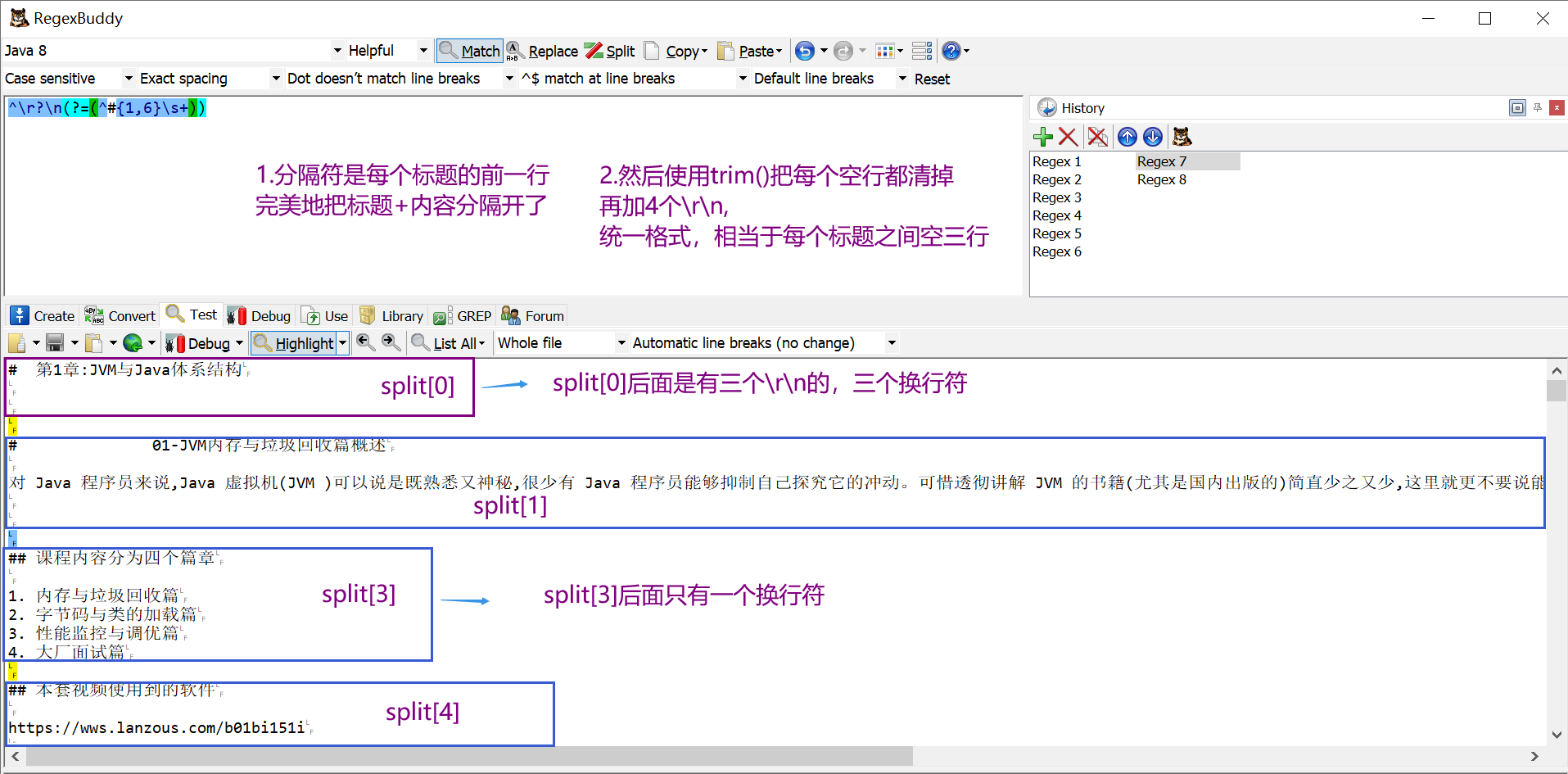 sb.append(split[i].trim()).append("\r\n\r\n\r\n\r\n");
sb.append(split[i].trim()).append("\r\n\r\n\r\n\r\n");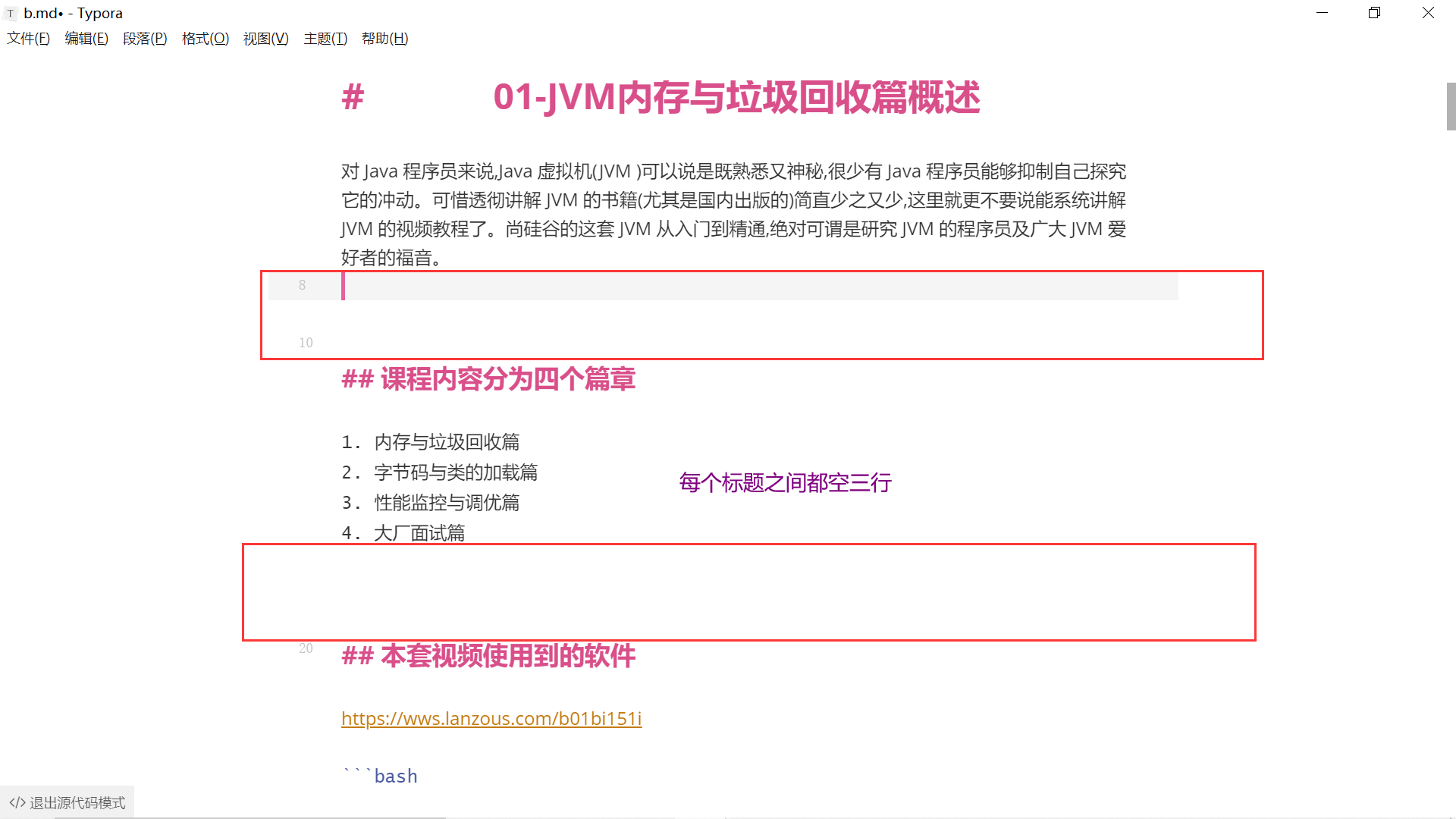 以后写md文档就不用太关注格式了,写完用代码整理一下即可,注意在文档中使用#时,不要放在开头就行了。
以后写md文档就不用太关注格式了,写完用代码整理一下即可,注意在文档中使用#时,不要放在开头就行了。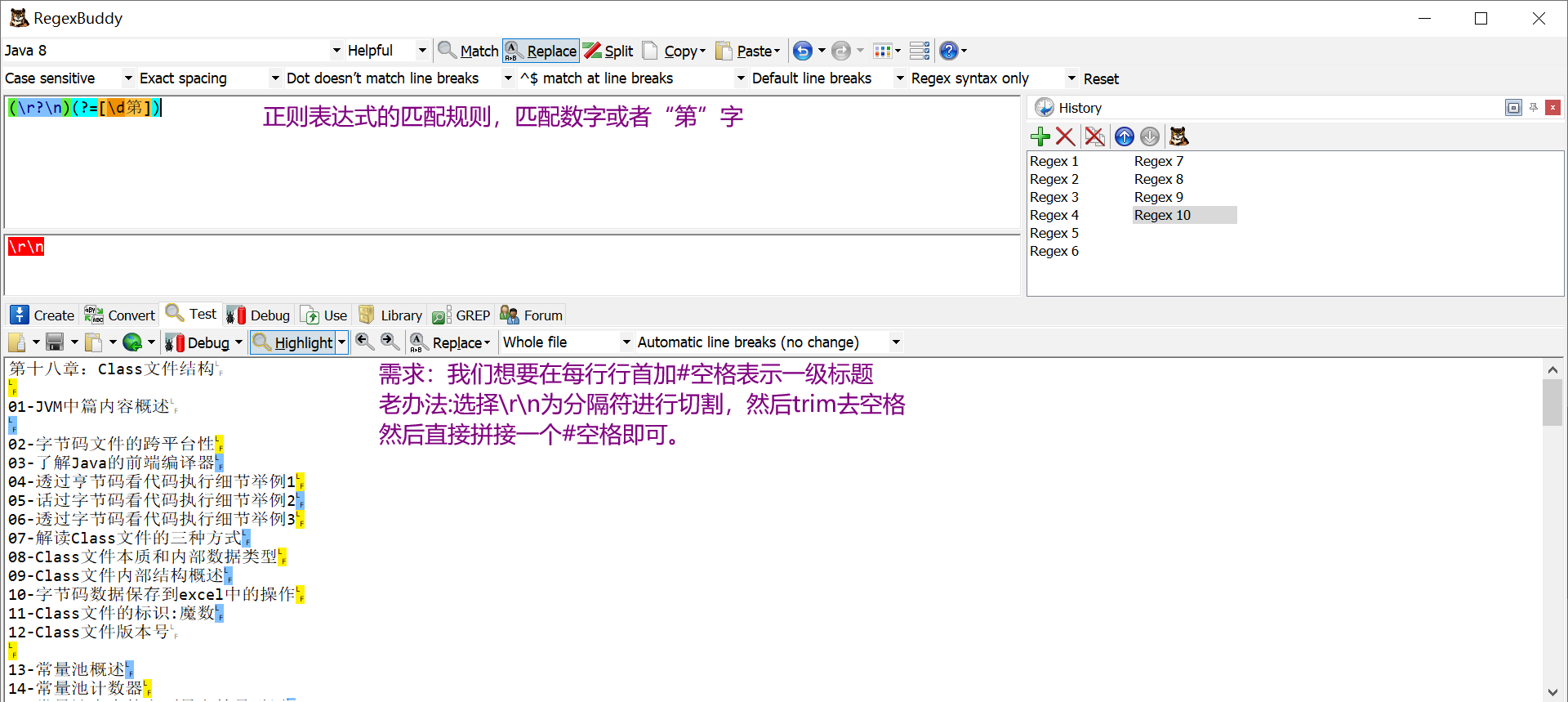 效果图
效果图 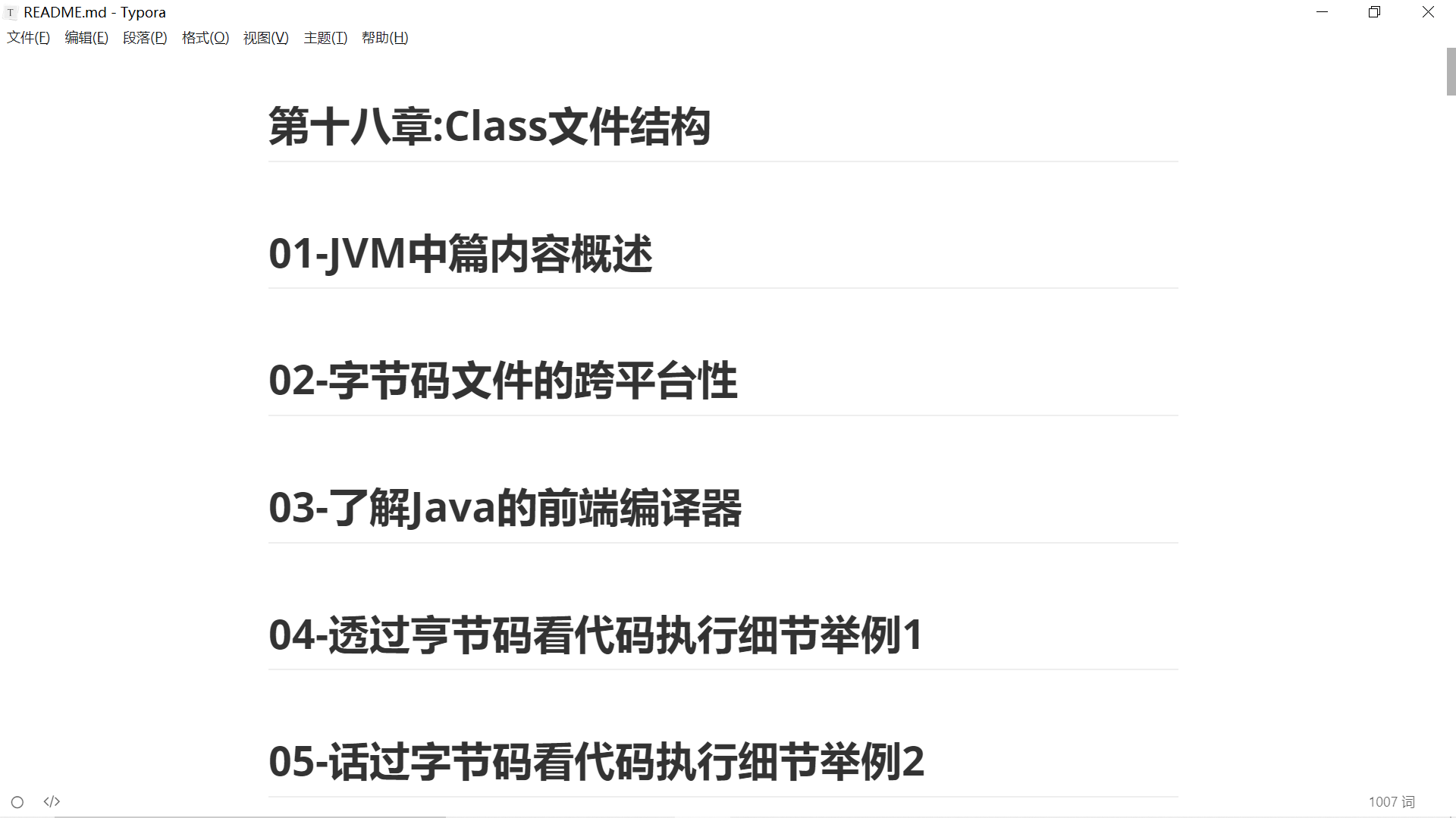 代码:用之前的代码随便改了下 主要是正则表达式的匹配规则 分隔符是(\r?\n)(?=[\d第]) 使用hutool工具包只是为了省几行代码,其实可以用传统io流,就不用导包了
代码:用之前的代码随便改了下 主要是正则表达式的匹配规则 分隔符是(\r?\n)(?=[\d第]) 使用hutool工具包只是为了省几行代码,其实可以用传统io流,就不用导包了【本文地址】
| 今日新闻 |
| 推荐新闻 |
| 专题文章 |