| Spark 本地提交、WebUI全攻略 | 您所在的位置:网站首页 › spark页面 › Spark 本地提交、WebUI全攻略 |
Spark 本地提交、WebUI全攻略
|
本地提交:
Local提交方式主要用于快速入门,开发阶段测试。用该模式提交,开箱即用,不用启动Spark的Master、Worker守护进程( 只有集群的Standalone方式时,才需要这两个角色),也不用启动Hadoop的各服务(除非你要用到HDFS) 提交命令:提交java spark-submit --class com.WordCount --master local /usr/local/spark/bin/spark-test-1.0-SNAPSHOT.jar提交python spark-submit --master local /usr/local/spark-2.3.1-bin-hadoop2.7/examples/src/main/python/wordcount.py /usr/local/spark-2.3.1-bin-hadoop2.7/bin/word.txt spark-submit --master -local这个SparkSubmit进程又当爹、又当妈,既是客户提交任务的Client进程、又是Spark的driver程序、还充当着Spark执行Task的Executor角色。 该模式被称为Local[N]模式,是用单机的多个线程来模拟Spark分布式计算,直接运行在本地,便于调试,通常用来验证开发出来的应用程序逻辑上有没有问题。其中N代表可以使用N个线程,每个线程拥有一个core。如果不指定N,则默认是1个线程(该线程有1个core)。如果是local[*],则代表 Run Spark locally with as many worker threads as logical cores on your machine. Web-UI界面想通过WebUI控制台页面来查看具体的job运行细节,正在运行时的任务可以通过访问http:ip/4040(一旦任务结束,该端口将会自动关闭),有时需要查看历史的job,这时需要用到spark-history-server.sh服务,操作如下: 1、修改spark-env.sh进入spark安装目录下,找到spark-env.sh文件,在末尾添加 export **SPARK_HISTORY_OPTS**="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=3 -Dspark.history.fs.logDirectory=/usr/local/spark/spark-events"Dspark.history.ui.port: 默认值:18080 //HistoryServer的web端口 Dspark.history.retainedApplications 设置缓存Cache中保存的应用程序历史记录的个数,默认50,如果超过这个值,旧的将被删除。 Dspark.history.fs.logDirectory 存放历史记录文件的目录 2、修改spark-defauls.conf默认不存在该文件,从spark-defauls.conf.teamplate拷贝一个,修改如下: spark.eventLog.enabled true spark.eventLog.dir /usr/local/spark/spark-eventsspark.eventLog.enabled 是否记录Spark事件,用于应用程序在完成后的筹够WebUI。 spark.eventLog.dir 设置spark.eventLog.enabled为true后,该属性为记录spark时间的根目录。在此根目录中,Spark为每个应用程序创建分目录,并将应用程序的时间记录到此目录中。用户可以将此属性设置为HDFS目录,以便History Server读取。 每个任务的历史信息被保存在了该目录下: 在sbin目录下,启动spark-history-server.sh,然后访问http:ip:18080/,效果如下: |

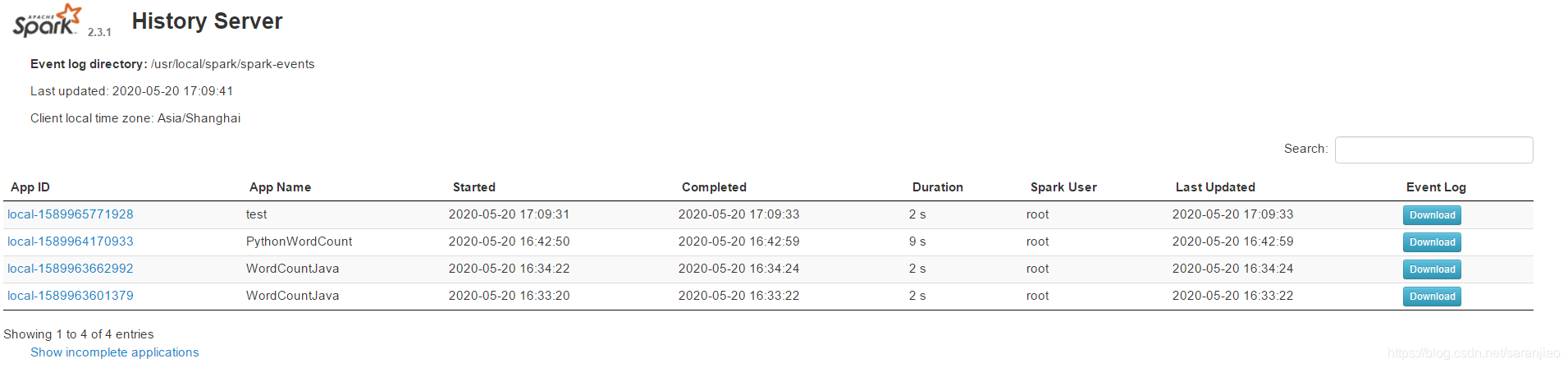 参考: Spark配置History服务 Spark运行模式_local(本地模式) Spark入门 - History Server配置使用
参考: Spark配置History服务 Spark运行模式_local(本地模式) Spark入门 - History Server配置使用【本文地址】