| Apache Spark 架构 | 您所在的位置:网站首页 › spark概述与特点 › Apache Spark 架构 |
Apache Spark 架构
|
Apache Spark 是一个开源集群计算框架,它正在点燃大数据的世界。根据Spark 认证专家的说法,与 Hadoop 相比,Sparks 在内存中的性能提高了 100 倍,在磁盘上的性能提高了 10 倍。 在这篇博客中,我将简要介绍 Spark 架构和 Spark 架构的基础知识。 在这篇 Spark 架构文章中,我将涵盖以下主题: Spark及其特点 Spark 架构概述 Spark Eco-System 弹性分布式数据集 (RDD) Spark架构的工作 在 Spark Shell 中使用 Scala 的示例 Spark及其特点Apache Spark 是一个用于实时数据处理的开源集群计算框架。Apache Spark 的主要特性是其 内存集群计算 ,可提高应用程序的处理速度。Spark 提供了一个接口,用于对具有隐式数据并行性和容错性的整个集群进行编程。它旨在涵盖广泛的工作负载,例如批处理应用程序、迭代算法、交互式查询和流媒体。 Apache Spark 的特点:
Apache Spark 具有定义明确的分层架构,其中所有 Spark 组件和层都是松散耦合的。该架构进一步与各种扩展和库集成。Apache Spark 架构基于两个主要抽象: 弹性分布式数据集 (RDD) 有向无环图 (DAG)
图:Spark 架构 但在深入研究 Spark 架构之前,让我解释一些 Spark 的基本概念,如 Spark 生态系统和 RDD。这将帮助您获得更好的见解。 我先解释一下什么是Spark生态系统。 Spark Eco-System如下图所示,spark 生态系统由各种组件组成,如 Spark SQL、Spark Streaming、MLlib、GraphX 和 Core API 组件。
图:Spark 生态系统 Spark CoreSpark Core 是大规模并行和分布式数据处理的基础引擎。此外,构建在核心顶部的其他库允许用于流、SQL 和机器学习的各种工作负载。它负责内存管理和故障恢复、调度、分发和监控集群上的作业以及与存储系统的交互。 Spark StreamingSpark Streaming 是Spark 的组件,用于处理实时流数据。因此,它是对核心 Spark API 的有用补充。它支持实时数据流的高吞吐量和容错流处理。 Spark SQLSpark SQL 是 Spark 中的一个新模块,它将关系处理与 Spark 的函数式编程 API 集成在一起。它支持通过 SQL 或 Hive 查询语言查询数据。对于熟悉 RDBMS 的人来说,Spark SQL 将是您早期工具的轻松过渡,您可以在其中扩展传统关系数据处理的边界。 GraphXGraphX 是用于图形和图形并行计算的 Spark API。因此,它使用弹性分布式属性图扩展了 Spark RDD。在高层次上,GraphX 通过引入弹性分布式属性图(具有附加到每个顶点和边的属性的有向多重图)扩展了 Spark RDD 抽象。 MLlib(机器学习)MLlib 代表机器学习库。Spark MLlib 用于在 Apache Spark 中执行机器学习。 SparkR是一个提供分布式数据帧实现的 R 包。它还支持选择、过滤、聚合等操作,但在大型数据集上。如您所见,Spark 带有高级库,包括对 R、SQL、Python、Scala、Java 等的支持。这些标准库增加了复杂工作流中的无缝集成。除此之外,它还允许各种服务集与其集成,如 MLlib、GraphX、SQL + 数据帧、流服务等,以增加其功能。 现在,让我们讨论 Spark 的基本数据结构,即 RDD。 弹性分布式数据集 (RDD)RDD 是任何 Spark 应用程序的构建块。RDD 代表: 弹性: 容错并且能够在故障时重建数据 分布式: 集群中多个节点之间的分布式数据 数据集: 带值的分区数据的集合
它是分布式集合上的抽象数据层。它本质上是不可变的,并且遵循 惰性转换。 现在您可能想知道它的工作原理。好吧,RDD 中的数据基于一个键被拆分成块。RDD 具有高弹性,即它们能够从任何问题中快速恢复,因为相同的数据块在多个执行器节点之间复制。因此,即使一个执行器节点发生故障,另一个仍将处理数据。这使您可以通过利用多个节点的功能非常快速地对数据集执行功能计算。 此外,一旦你创建了一个 RDD,它就会变成不可变的。不可变我的意思是,一个对象在创建后其状态不能被修改,但它们肯定可以被转换。 说到分布式环境,RDD中的每个数据集都被划分为逻辑分区,可以在集群的不同节点上进行计算。因此,您可以对完整数据并行执行转换或操作。此外,您不必担心分布,因为 Spark 会处理这些问题。
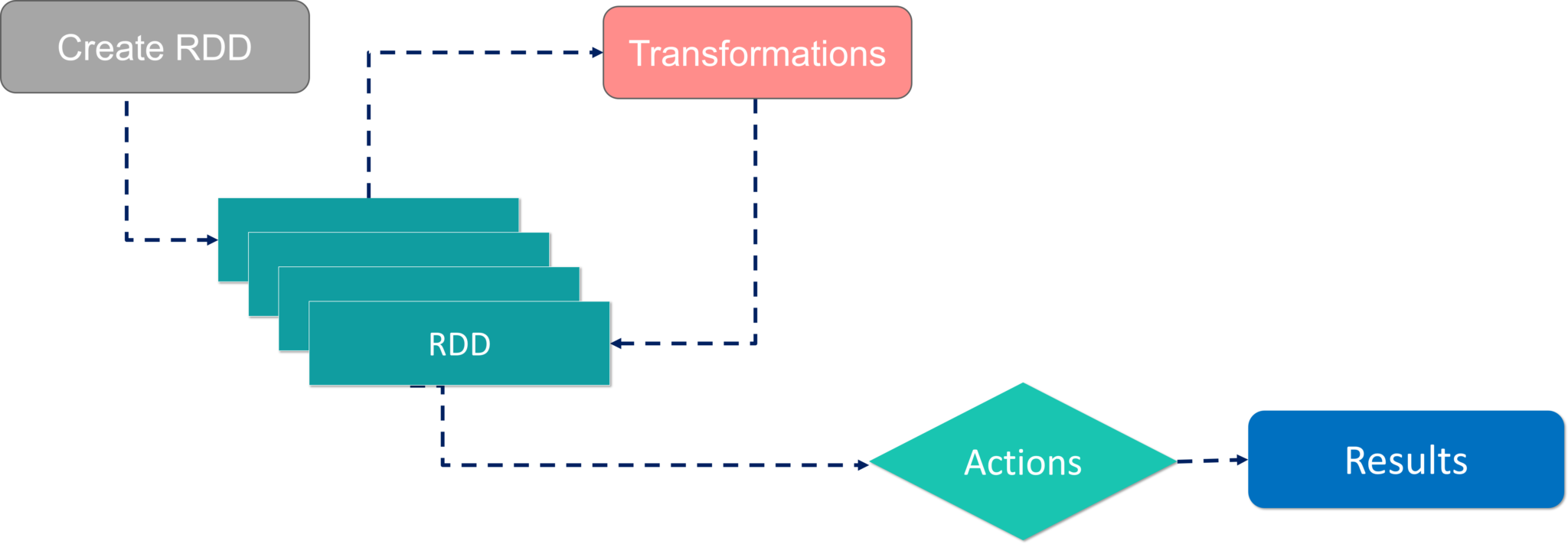
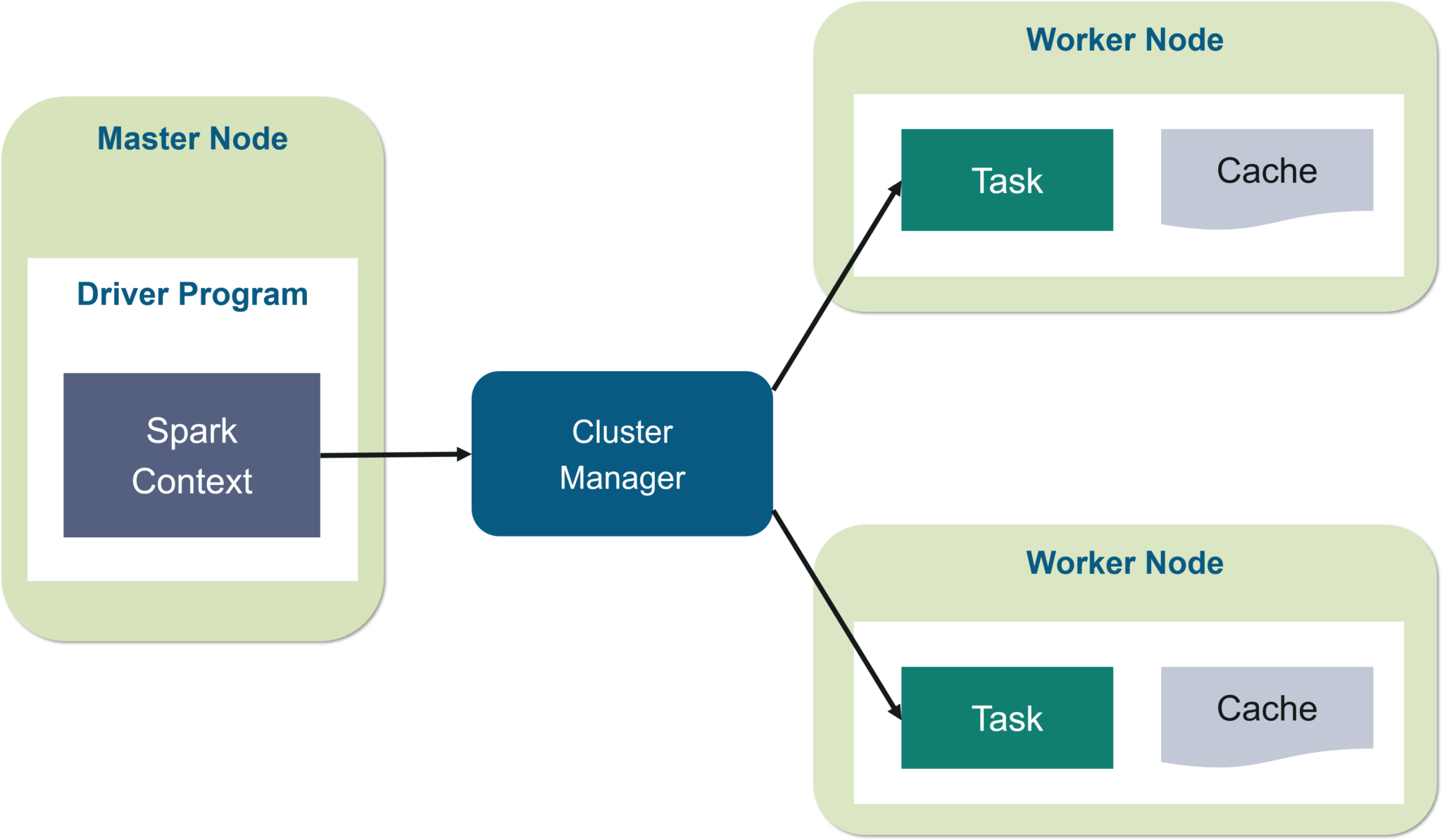
RDD的工作流程 有两种创建 RDD 的方法 - 在驱动程序中并行化现有集合,或者通过引用外部存储系统中的数据集,例如共享文件系统、HDFS、HBase 等。 使用 RDD,您可以执行两种类型的操作: 转换:它们是用于创建新 RDD 的操作。 操作: 它们应用于 RDD 以指示 Apache Spark 应用计算并将结果传递回驱动程序。我希望你对 RDD 的概念有一个透彻的理解。现在让我们更进一步,看看 Spark 架构的工作原理。 Spark架构的工作正如您已经看到了 Apache Spark 的基本架构概述,现在让我们更深入地了解它的工作原理。 在您的主节点中,您有驱动程序,它驱动您的应用程序。您正在编写的代码充当驱动程序,或者如果您使用交互式 shell,则 shell 充当驱动程序。
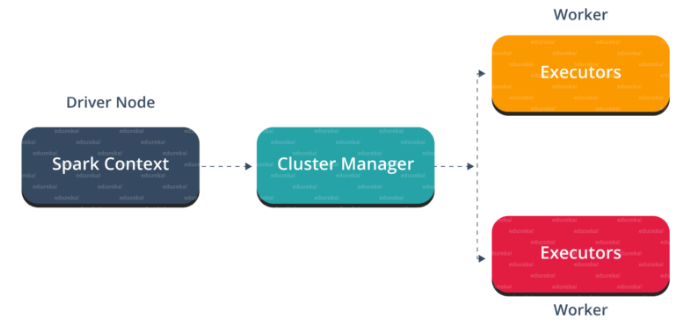
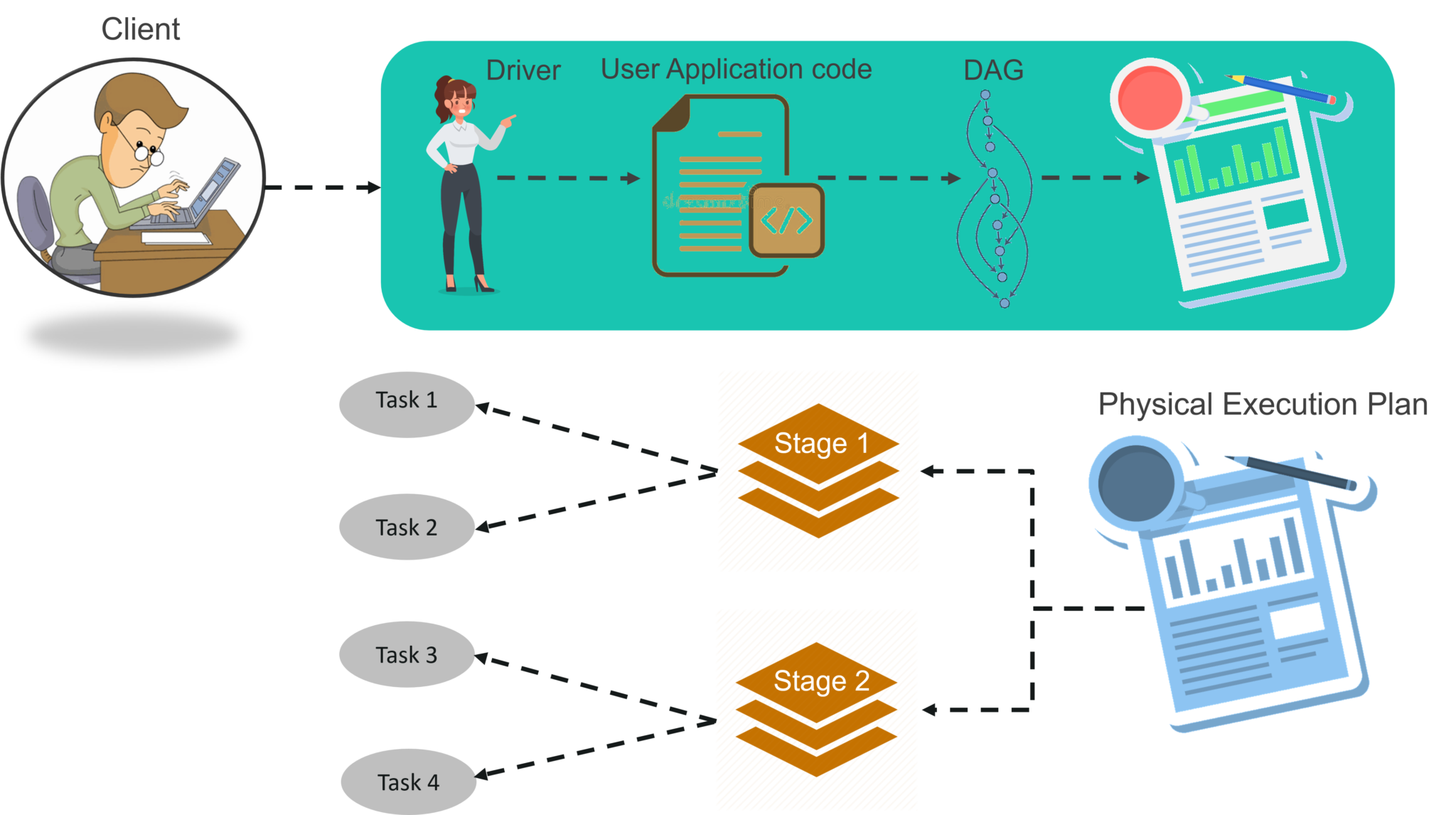
图:Spark 架构 我n面的驱动程序,你要做的第一件事是,你创建 一个星火语境。假设 Spark 上下文是通往所有 Spark 功能的网关。它类似于您的数据库连接。您在数据库中执行的任何命令都通过数据库连接。同样,您在 Spark 上所做的任何事情都经过 Spark 上下文。 现在,这个 Spark 上下文与集群管理器一起管理各种作业。驱动程序和 Spark 上下文负责集群内的作业执行。一个作业被分成多个任务,这些任务分布在工作节点上。任何时候在 Spark 上下文中创建 RDD,它都可以分布在各个节点上并可以缓存在那里。 w ^ orker节点是从节点,其任务是执行基本任务。然后在工作节点中的分区 RDD 上执行这些任务,从而将结果返回给 Spark 上下文。 Spark Context 接受工作,在任务中中断工作并将它们分发到工作节点。这些任务在分区的 RDD 上工作,执行操作,收集结果并返回到主 Spark 上下文。 如果增加工作线程的数量,则可以将作业划分为更多分区并在多个系统上并行执行。会快很多。 随着工作人员数量的增加,内存大小也会增加,您可以缓存作业以更快地执行它。 要了解 Spark Architecture 的工作流程,您可以查看下面的信息图:
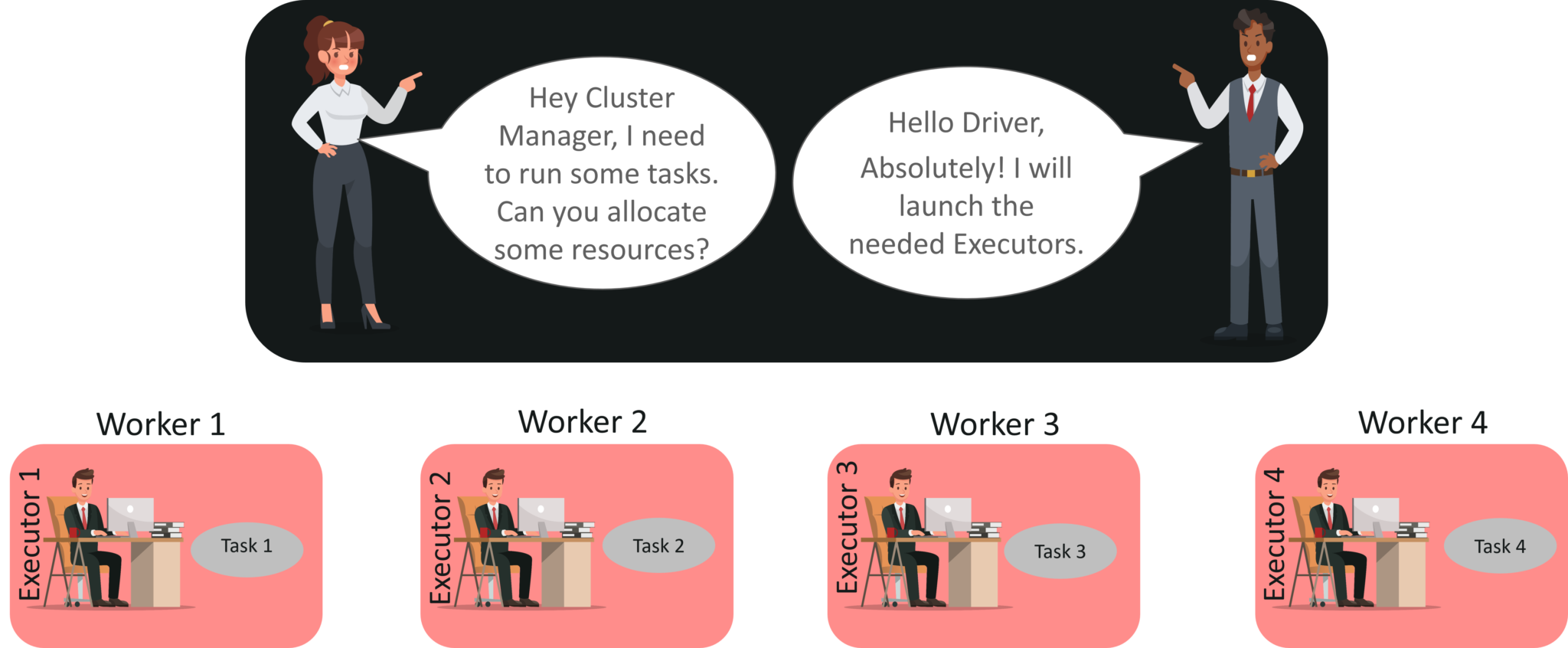
图:Spark 架构信息图 STEP 1: 客户端提交spark用户应用代码。 当提交应用程序代码时,驱动程序将包含转换和操作的用户代码隐式转换为称为DAG的逻辑有向无环图。 在此阶段,它还执行优化,例如流水线转换。 STEP 2:之后,它将称为 DAG 的逻辑图转换为具有多个阶段的物理执行计划。 转化为物理执行计划后,在每个阶段创建称为任务的物理执行单元。然后将任务捆绑并发送到集群。 第 3 步:现在驱动程序与集群管理器对话并协商资源。 集群管理器代表驱动程序在工作节点中启动执行程序。 此时,驱动程序将根据数据放置将任务发送给执行程序。 当执行程序启动时,他们向驱动程序注册自己。因此,驱动程序将拥有正在 执行任务的执行程序的完整视图。
STEP 4: 在任务执行过程中,驱动程序会监控运行的执行器集合。驱动程序节点还根据数据放置安排未来的任务。 这都是关于 Spark 架构的。现在,让我们来了解一下 Spark shell 的工作原理。 在 Spark shell 中使用 Scala 的示例首先,让我们假设 Hadoop 和 Spark 守护进程已启动并正在运行,从而启动 Spark shell。 Spark 的Web UI端口是localhost:4040。
图:火花壳 启动 Spark shell 后,现在让我们看看如何执行字数统计示例: 在本例中,我创建了一个简单的文本文件并将其存储在 hdfs 目录中。您也可以使用其他大型数据文件。
2、一旦 spark shell 启动, 让我们创建一个 RDD。为此,您必须 指定输入文件路径并应用转换flatMap()。下面的代码说明了相同的内容: scala> var map = sc.textFile("hdfs://localhost:9000/Example/sample.txt").flatMap(line => line.split(" ")).map(word => (word,1));3. 执行此代码时,将创建一个 RDD,如图所示。
图:RDD创建 4. 之后,您需要将操作reduceByKey()应用于创建的RDD。 scala> var counts = map.reduceByKey(_+_);应用动作后,如下所示开始执行。
图:shell中的Spark执行 5. 下一步是将输出保存在文本文件中并指定存储输出的路径。
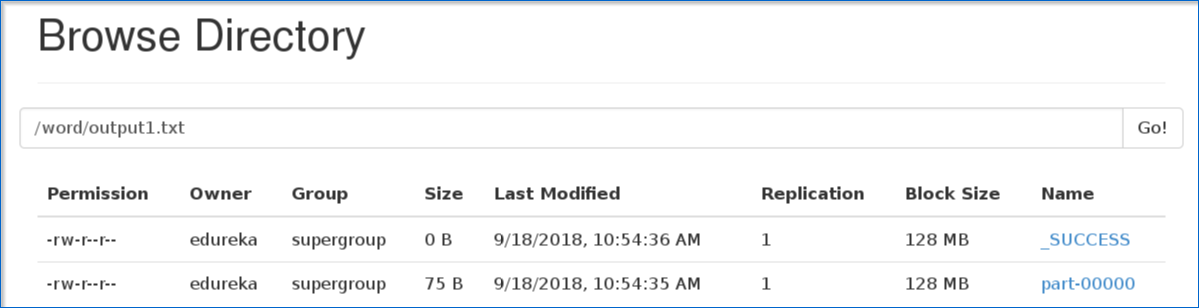
图:指定输出路径 6.指定输出路径后,进入 hdfs网页浏览器localhost:50040。在这里您可以看到“零件”文件中的输出文本,如下所示。
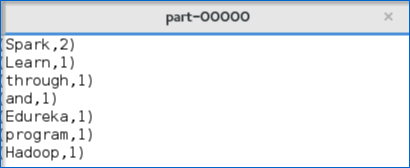
图:输出零件文件 7. 下图显示了“零件”文件中的输出文本。
图:输出文本 我希望您已经了解如何创建 Spark 应用程序并获得输出。 现在,让我带您通过 Spark 的 Web UI 来了解已执行任务的 DAG 可视化和分区。
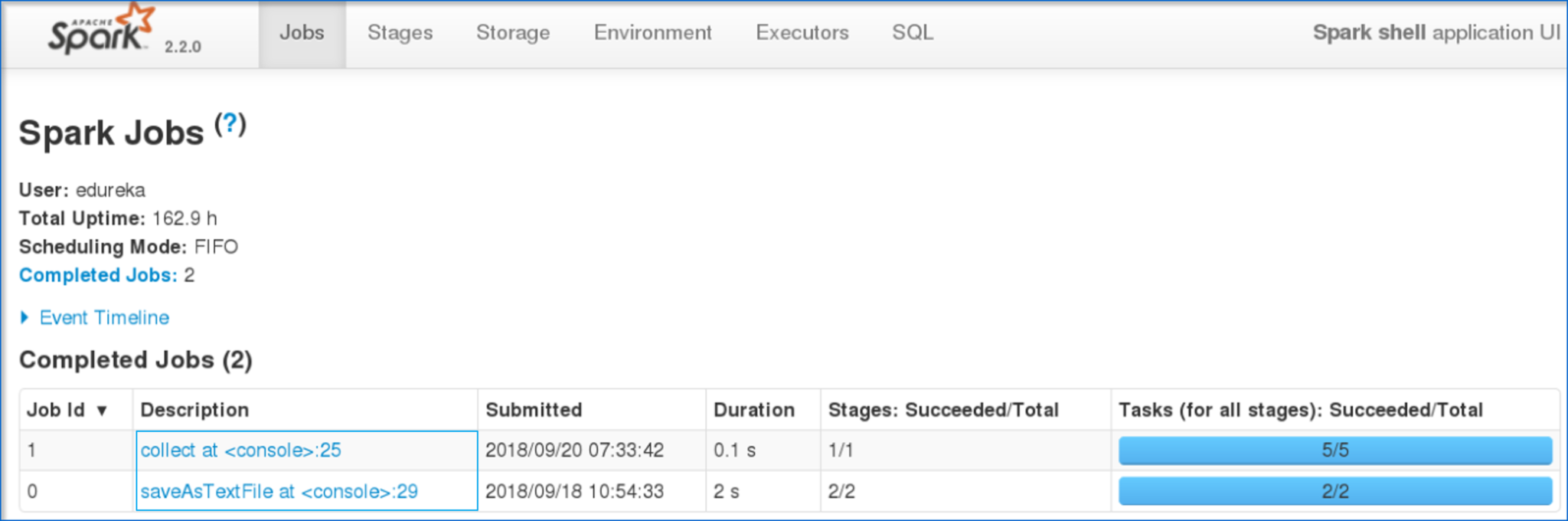
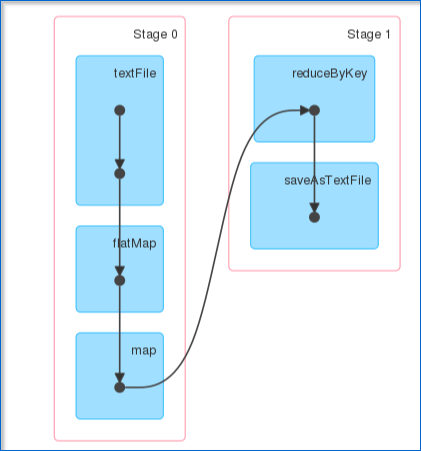
图:Spark Web 用户界面 单击您提交的任务后,您可以查看已完成作业的有向无环图 (DAG)。
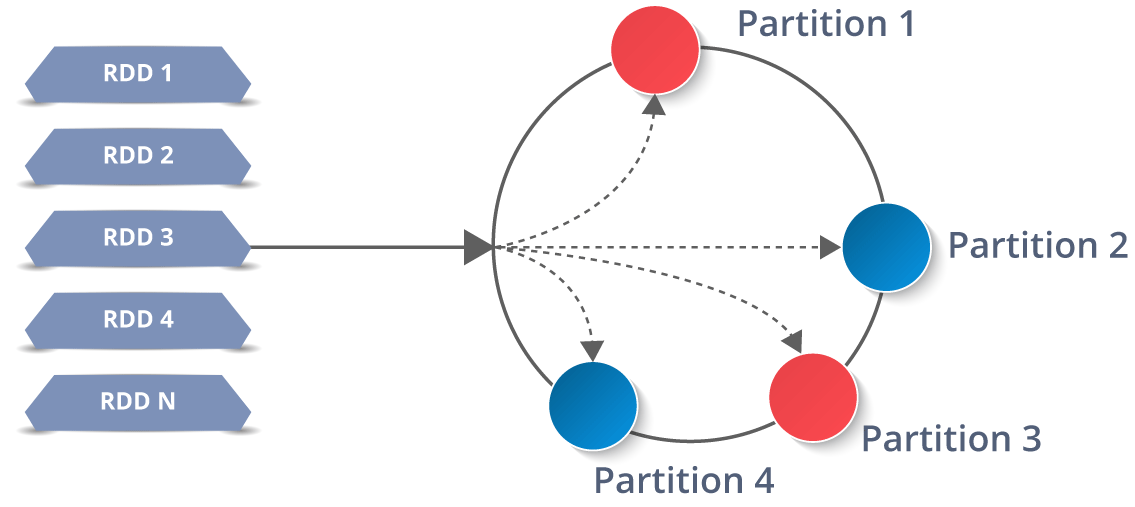
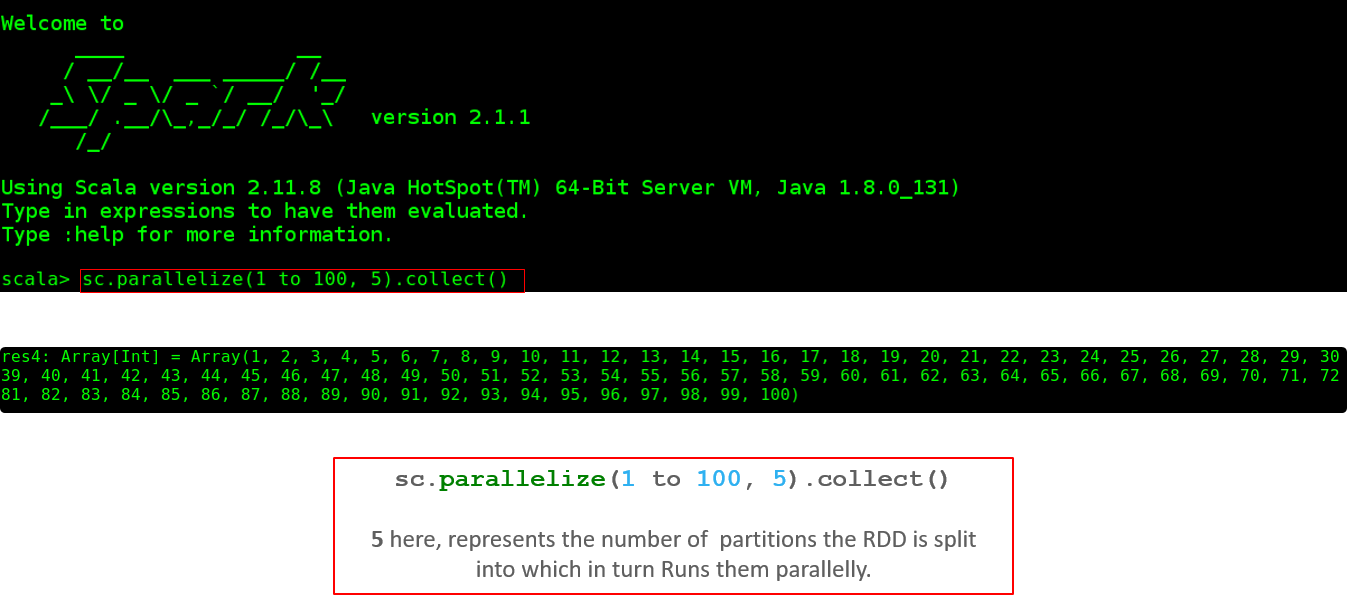
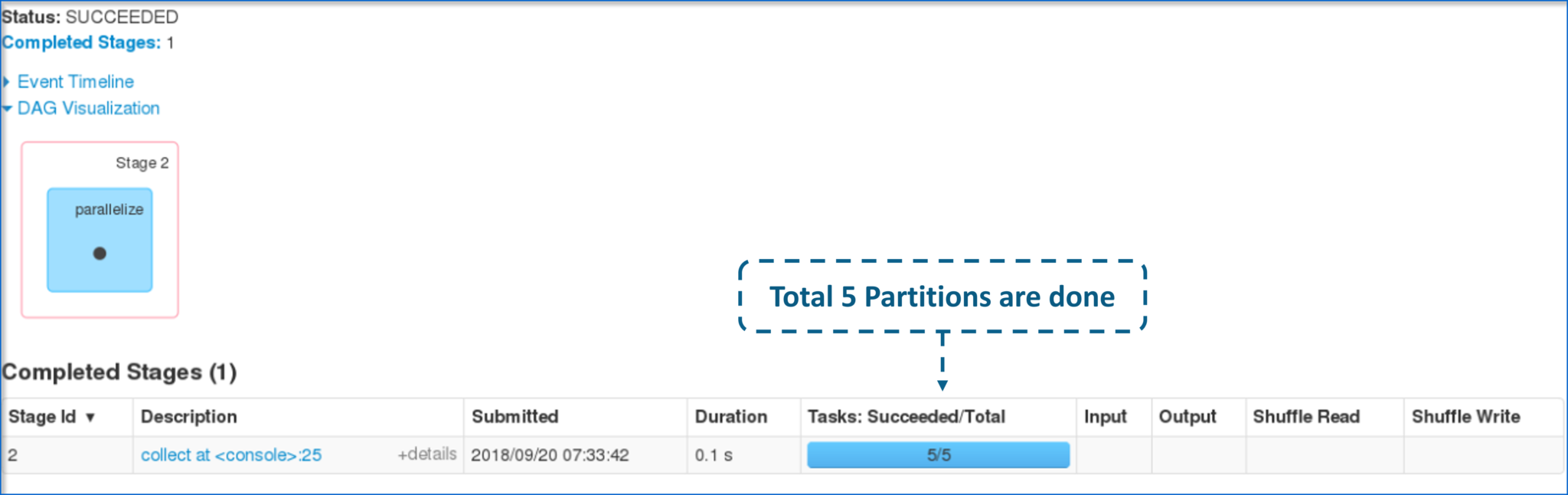
图:DAG 可视化 此外,您还可以查看已执行任务的摘要指标,例如 - 执行任务所花费的时间、作业 ID、已完成的阶段、主机 IP 地址等。现在,让我们了解 RDD 中的分区和并行性。 甲分区是一个逻辑 块a的大 分布式 数据 集。 默认情况下,星火试图读取 数据 到 一个 RDD从节点是接近 到 它。现在,让我们看看如何在 shell 中执行并行任务。
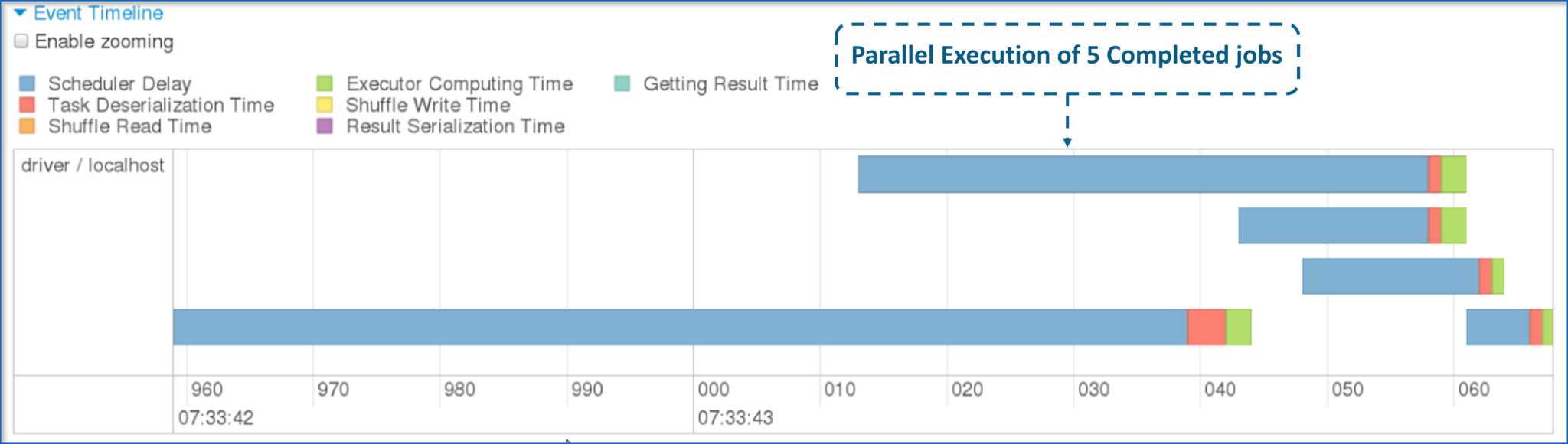
图:已完成任务的分区 现在,让我向您展示 5 个不同任务的并行执行是如何出现的。
图:5个已完成任务的并行度 到此,我们就到了有关 Apache Spark 架构的博客的结尾。我希望这个博客能提供信息并为您的知识增加价值。 |





【本文地址】