| 激活函数与损失函数 | 您所在的位置:网站首页 › sigmoid公式 › 激活函数与损失函数 |
激活函数与损失函数
|
目录: sigmoidtanhReLuLReLuPReLusoftmax对数损失函数交叉熵损失函数总结在深度学习中,输入值和矩阵的运算是线性的,而多个线性函数的组合仍然是线性函数,对于多个隐藏层的神经网络,如果每一层都是线性函数,那么这些层在做的就只是进行线性计算,最终效果和一个隐藏层相当!那这样的模型的表达能力就非常有限 。 实际上大多数情况下输入数据和输出数据的关系都是非线性的。所以我们通常会用非线性函数对每一层进行激活,大大增加模型可以表达的内容(模型的表达效率和层数有关)。 这时就需要在每一层的后面加上激活函数,为模型提供非线性,使得模型可以表达的形式更多,同时也可以更改模型的输出值,使模型可以实现回归或者分类的功能。常见的激活函数有sigmoid、tanh、relu和softmax。下面分别对其进行介绍。 1、sigmoid输入值与权重矩阵进行计算得到的输出值范围很大,为了实现分类任务,需要使用激活函数sigmoid 把这些值压缩到0-1之间,表示某个分类的概率,通常用于二分类。sigmoid 的函数表达式如下: \sigma (x) = \dfrac {1}{1 + e^{-x}} \\ 对应的函数曲线为: 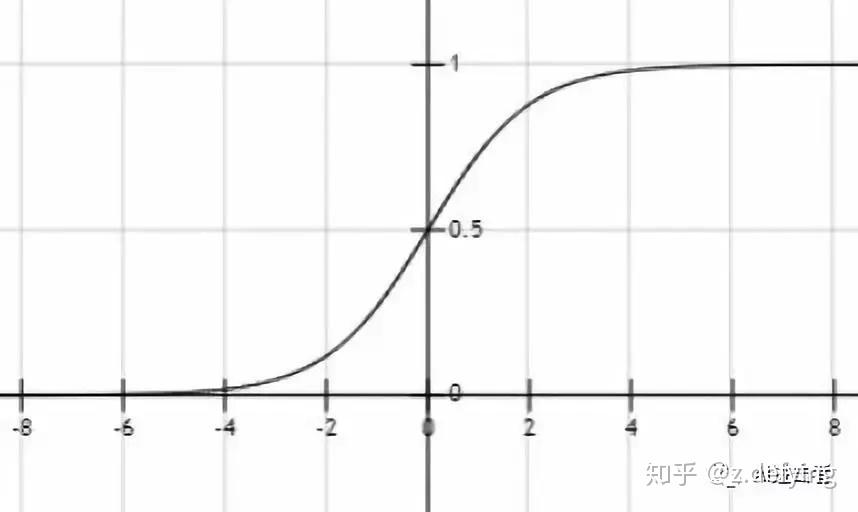 2、tanh 2、tanh双曲正切函数 tanh 和 sigmoid 类似,区别就在于输出值范围由 (0,1) 变为了 (-1,1),可以把 tanh 函数看做是 sigmoid 向下平移和拉伸后的结果。tanh对应的函数表达式: tanh(x) = \dfrac {e^x - e^{-x}}{e^x + e^{-x}} \\ tanh 和 sigmoid 的关系如下: tanh(x) = \dfrac {2}{1 + e^{-2x}} - 1 \\ 对应的函数曲线为:  在隐藏层中使用 tanh 函数的效果总体上是优于 sigmoid 函数的。 因为函数值域在 -1 到 +1 之间的激活函数,它的输出是以零为中心的。在训练一个算法模型时,如果使用 tanh 函数代替 sigmoid 函数,就会使得输出数据的平均值更接近 0 而不是 0.5。即输入为负数的话,输出也为负数;同理输入为正数,输出也为正数。 但是 sigmoid 和 tanh 有相同的缺点,在值非常大的时候,函数的导数会变得特别小(由两者的函数曲线可知),甚至接近于 0,使得梯度下降的速度减缓,导致模型学习的效率降低,这种现象称为梯度消失,在多层线性网络中,情况更严重。而 ReLu 激活函数可以解决这个问题。 3、ReLu修正线性单元的函数 ReLu 的函数表达式为 relu = max(0, x),也就是取 x 和 0 的最大值,函数曲线如下图:  从图中可以看出对于所有为正值的输入,其梯度都为1,不会变小;对于小于0的数据,梯度都为0.。所谓非线性,就是一阶导数不为常数。对ReLU求导,在输入值分别为正和为负的情况下,导数是不同的,即ReLU的导数不是常数,所以ReLU是非线性的。 ReLU 实现非常简单,没有指数运算等耗费计算资源的操作,ReLU 不会出现梯度消失的问题,对于梯度下降的收敛有加速作用。在实践中,使用 ReLu 激活函数的神经网络通常会比使用 sigmoid 或者 tanh 激活函数学习的更快更好,它几乎用于所有的卷积神经网络或深度学习。 3.1、Leaky ReluRelu 有一个问题就是所有负值输入后都立即变为零,这降低了模型根据数据进行适当拟合或训练的能力。这意味着任何给 ReLU 激活函数的负输入都会立即把值变成零。而且当 Relu 进入负半区的时候,梯度为 0,神经元此时不会训练,就会产生所谓的稀疏性。 Leaky Relu 是 Relu 的改进版本,当输入值是负值时,函数值不等于 0,给了一个很小的负数梯度值, \alpha 通常为 0.1。这个函数通常比 Relu 激活函数效果要好,但是效果不是很稳定,所以在实际中 Leaky ReLu 使用的并不多。 其函数图如下:  3.2、Parametric Relu 3.2、Parametric Relu在 Leaky Relu 中会设置一个很小的非零参数 \alpha 作为负输入的梯度,而在 PRelu 中,将 \alpha 作为一个可学习的参数,会在训练的过程中进行更新。 即在 LRelu 中, \alpha 是一个 hyper parameter;而在 RRelu 中, \alpha 是一个 parameter。 4、softmax在二分类任务中,输出层使用的激活函数为 sigmoid,而对于多分类的情况,就需要用到softmax 激活函数给每个类都分配一个概率。 多分类的情况下,神经网络的输出是一个长度为类别数量的向量,比如输出是(1,1,2),为了计算概率,可以将其中的每个除以三者之和,得到 (0.25, 0.25, 0.5)。 但是这样存在一个问题,比如像 (1,1,-2) 这种存在负数的情况,这种方法就不行了。解决办法是先对每个元素进行指数操作,全部转换为正数,然后再用刚才的方法得到每个类别的概率。 softmax 函数将每个单元的输出压缩到 0 和 1 之间,是标准化输出,输出之和等于 1。softmax 函数的输出等于分类概率分布,显示了任何类别为真的概率。softmax 公式如下:  下面是更形象的例子:  图来自《一天搞懂深度学习》 图来自《一天搞懂深度学习》 有了每个类别的概率,就需要计算损失函数。最常用的两个损失函数是均方损失(MSELoss 通常用于回归问题)、对数损失(logLoss 常用于二分类问题)和交叉熵损失(CrossEntropyLoss 常用于多分类问题)。 5、对数损失函数在介绍交叉熵损失函数之前,先看看对数损失函数(logLoss)。 对数损失函数的基本思想是极大似然估计,极大似然估计简单来说,就是一个事件已经发生了,那么就认为这事件发生的概率应该是最大的。似然函数就是这个概率,我们要做的就是基于现有数据确定参数从而最大化似然函数。 在进行似然函数最大化时,会对多个事件的概率进行连续乘法。连续乘法中很多个小数相乘的结果非常接近0,而且任意数字发生变化,对最终结果的影响都很大。为了避免这两种情况,可以使用对数转换将连续乘法转换为连续加法。对数函数是单调递增函数,转换后不会改变似然函数最优值的位置。 再加个负号,从而可以将求解最大似然函数转换为求解最小损失函数。二分类问题的对数损失函数如下:  第一项表示预测正样本得到的损失,第二项表示预测负样本得到的损失。 其中 y表示实际情况下事件是否发生(0或1),p表示事件发生的概率,也就是我们通过深度学习得到的预测概率。 对于单个数据样本,会有如下两种情况(二分类中由sigmoid函数得到概率p): 当y=1时,损失函数为 -ln(p),如果想要损失函数尽可能的小,那么概率p就要尽可能接近1。当y=0时,损失函数为 -ln(1-p),如果想要损失函数尽可能的小,那么概率p就要尽可能接近0。上面只是单个事件对应的损失,如果有m个独立事件,则损失函数公式如下:  通过一个例子来理解上面的公式。假设有三个独立事件,1表示事件发生,现在三个事件发生情况为(1,1,0),通过深度学习得到三个事件发生的概率为(0.8, 0.7, 0.1),使用上面的公式计算损失值为0.69,损失值很小,说明这组概率正确的可能性很大;同样的这组概率,三个事件发生情况为(0,0,1),计算得到的损失值5.12,损失值很大,说明这组概率正确的可能性很小。 6、交叉熵损失函数上面的对数损失函数是针对二分类的,对于多分类问题,需要使用交叉熵损失函数,对数损失函数也被称为二分类的交叉熵损失函数。 多类别中每个类别都对应一个概率,所以k个类别的交叉熵损失函数公式如下:  多分类中每个类的概率就需要用 softmax 激活函数得到,而二分类中的概率是用 sigmoid 激活函数得到的。现在得到了多分类的损失函数,接下来就可以使用梯度下降算法来优化网络参数使得损失函数最小化。 总结对于多层神经网络,用于隐藏层的激活函数通常为ReLu及其变体,这也是最常用的激活函数。 对于二分类网络,使用 sigmoid 作为其输出层的激活函数;对于多分类网络,使用 softmax 作为其输出层的激活函数 逻辑回归就是使用对数损失函数来进行二分类任务,softmax回归是逻辑回归的推广,softmax回归使用交叉熵损失函数来进行多分类任务。 如果觉得有用,点个赞吧(ง •̀_•́)ง。 |
【本文地址】