| 详解各种LLM系列|LLaMA 2模型架构、 预训练、SFT内容详解 (PART1) | 您所在的位置:网站首页 › sft指令的作用 › 详解各种LLM系列|LLaMA 2模型架构、 预训练、SFT内容详解 (PART1) |
详解各种LLM系列|LLaMA 2模型架构、 预训练、SFT内容详解 (PART1)
|
作者 | Sunnyyyyy 整理 | NewBeeNLP https://zhuanlan.zhihu.com/p/670002922 大家好,这里是 NewBeeNLP。之前我们分享了详解各种LLM系列|LLaMA 1 模型架构、预训练、部署优化特点总结 今天来看看Llama 2,是Meta在LLaMA基础上升级的一系列从 7B到 70B 参数的大语言模型。Llama2 在各个榜单上精度全面超过 LLaMA1,Llama 2 作为开源界表现最好的模型之一,目前被广泛使用。 为了更深入地理解Llama 2的技术特点,特地在此整理了Llama 2模型架构、 预训练、SFT、RLHF内容详解,也从安全性角度进行了分析。 话不多说,直接上干货啦  一、LLaMA 2简介论文:https://arxiv.org/abs/2307.09288Github:GitHub \- facebookresearch/llama: Inference code for LLaMA models[1] 一、LLaMA 2简介论文:https://arxiv.org/abs/2307.09288Github:GitHub \- facebookresearch/llama: Inference code for LLaMA models[1]Meta 在原本的LLaMA 1的基础上,增加了预训练使用的token数量;同时,修改了模型的架构,引入了Group Query Attention(GQA)。 并且,在Llama 2的基础上,Meta同时发布了 Llama 2-Chat。其通过应用监督微调来创建 Llama 2-Chat 的初始版本。随后,使用带有人类反馈 (RLHF) 方法的强化学习迭代地改进模型,过程中使用了拒绝采样和近端策略优化 (PPO)。 Llama 2-Chat的训练主要流程如下: 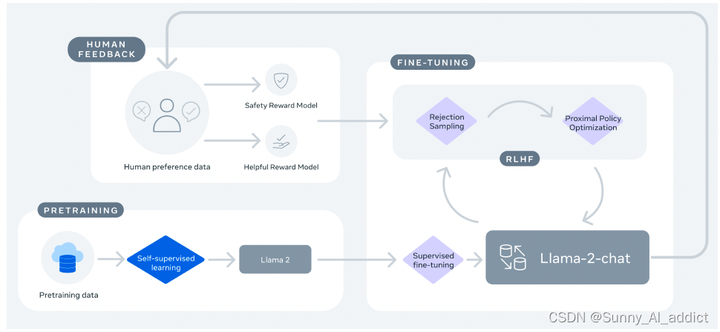 Llama 2-Chat的训练主要流程 二、模型架构2.1 主要架构Llama 2采用LLaMA 1的大部分预训练设置和模型架构,包括: Tokenzier: 和LLaMA 1一样的 tokenizer,使用 SentencePiece 实现的 BPE 算法。与LLaMA 1一样,将所有数字拆分为单个数字并使用字节来分解未知的 UTF-8 字符。总词汇量为 32k个 token。 (关于BPE,可参考BPE 算法原理及使用指南【深入浅出】 - 知乎[2]) Pre-normalization :为了提高训练稳定性,LLaMa 对每个 Transformer 子层的输入进行归一化,而不是对输出进行归一化。LLaMa 使用了 RMSNorm 归一化函数。 (关于Pre-norm vs Post-norm,可参考为什么Pre Norm的效果不如Post Norm?- 科学空间|Scientific Spaces[3]) SwiGLU 激活函数: LLaMa 使用 SwiGLU 激活函数替换 ReLU 以提高性能,维度从 4d 变为 \frac{2}{3}4d 。SwiGLU是一种激活函数,它是GLU的一种变体, 它可以提高transformer模型的性能。SwiGLU的优点是它可以动态地调整信息流的门控程度,根据输入的不同而变化,而且SwiGLU比ReLU更平滑,可以带来更好的优化和更快的收敛。 (关于SwiGLU激活函数,可参考激活函数总结(八):基于Gate mechanism机制的激活函数补充\(GLU、SwiGLU、GTU、Bilinear、ReGLU、GEGLU\)\_glu激活-CSDN博客[4]) Rotary Embeddings:LLaMa 没有使用之前的绝对位置编码,而是使用了旋转位置编码(RoPE),可以提升模型的外推性。它的基本思想是通过一个旋转矩阵来调整每个单词或标记的嵌入向量,使得它们的内积只与它们的相对位置有关。旋转嵌入不需要预先定义或学习位置嵌入向量,而是在网络的每一层动态地添加位置信息。旋转嵌入有一些优点,比如可以处理任意长度的序列,可以提高模型的泛化能力,可以减少计算量,可以适用于线性Attention等。 (关于 RoPE 的具体细节,可参考十分钟读懂旋转编码(RoPE) - 知乎[5])2.2 Group Query Attention (GQA)Llama 2与 LLaMA 1 的主要架构差异包括上下文长度和分组查询注意力 (GQA) 的增加,如下图: 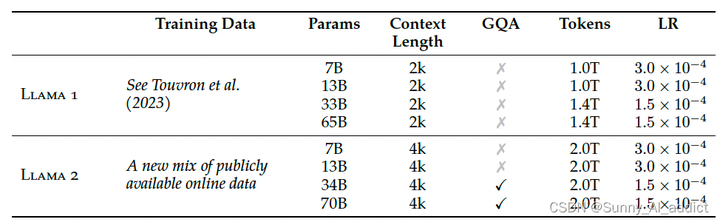 Llama 2与 LLaMA 1 的主要架构差异 GQA: 自回归解码的标准做法是使用KV Cache,即缓存序列中先前token 的键 (K) 和值 (V) 对,以加快后续token的注意力计算。然而,随着上下文窗口或者批量大小的增加,多头注意力(MHA)模型中与KV Cache大小相关的内存成本会显著增加。对于大模型,KV Cache会成为推理时显存应用的一个瓶颈。 对于上述这种情况,有两种主流解决方案: Multi Query Attention (MQA): 如下图所示,MQA在所有的query之间共享同一份键 (K) 和值 (V) 对 Group Query Attention (GQA): 如下图所示,GQA在不同的n (1 |
【本文地址】