| Scala函数式编程 | 您所在的位置:网站首页 › scala函数式编程pdf下载 › Scala函数式编程 |
Scala函数式编程
|
目录
1 函数式编程1.1 遍历 | foreach1.2 使用类型推断简化函数定义1.3 使用下划线来简化函数定义
2 映射 | map2.1 用法2.2 案例一2.3 案例二
3 扁平化映射 | flatMap3.1 定义3.2 案例
4 过滤 | filter4.1 定义4.2 案例
5 排序5.1 默认排序 | sorted5.2 指定字段排序 | sortBy5.3 自定义排序 | sortWith
6 分组 | groupBy6.1 定义6.2 示例
7 聚合操作7.1 聚合 | reduce7.1.1 定义7.1.2 案例
7.2 折叠 | fold7.2.1 定义7.2.2 案例
1 函数式编程
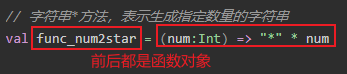
所谓的函数式编程指定就是 方法的参数列表可以接收函数对象 . 例如 : add(10, 20)就不是函数式编程, 而 add( 函数对象) 这种格式就叫函数式编程. 我们将来编写 Spark/Flink的大量业务代码时, 都会使用到函数式编程。下面的这些操作是学习的重点。
之前,学习过了使用for表达式来遍历集合。我们接下来将学习scala的函数式编程,使用foreach方法来进行遍历、迭代。它可以让代码更加简洁。 方法签名 foreach(f: (A) ⇒ Unit): Unit //函数是对象 //函数对象就是函数表达式
说明 foreachAPI说明参数f: (A) ⇒ Unit接收一个函数对象函数的输入参数为集合的元素,返回值为空返回值Unit空foreach执行过程
示例 有一个列表,包含以下元素1,2,3,4,请使用foreach方法遍历打印每个元素 参考代码 // 定义一个列表 scala> val a = List(1,2,3,4) a: List[Int] = List(1, 2, 3, 4) // 迭代打印 scala> a.foreach((x:Int)=>println(x)) 1.2 使用类型推断简化函数定义上述案例函数定义有点啰嗦,我们有更简洁的写法。因为使用foreach去迭代列表,而列表中的每个元素类型是确定的 scala可以自动来推断出来集合中每个元素参数的类型创建函数时,可以省略其参数列表的类型示例 有一个列表,包含以下元素1,2,3,4,请使用foreach方法遍历打印每个元素使用类型推断简化函数定义参考代码 scala> val a = List(1,2,3,4) a: List[Int] = List(1, 2, 3, 4) // 省略参数类型 scala> a.foreach(x=>println(x)) 1.3 使用下划线来简化函数定义当函数参数,只在函数体中出现一次,而且函数体没有嵌套调用时,可以使用下划线来简化函数定义 示例 有一个列表,包含以下元素1,2,3,4,请使用foreach方法遍历打印每个元素使用下划线简化函数定义参考代码 scala> val a = List(1,2,3,4) a: List[Int] = List(1, 2, 3, 4) a.foreach(println(_)) 如果方法参数是函数,如果出现了下划线,scala编译器会自动将代码封装到一个函数中参数列表也是由scala编译器自动处理 2 映射 | map集合的映射操作是将来在编写Spark/Flink用得最多的操作,是我们必须要掌握的。因为进行数据计算的时候,就是一个将一种数据类型转换为另外一种数据类型的过程。 map方法接收一个函数,将这个函数应用到每一个元素,返回一个新的列表
方法签名 def map[B](f: (A) ⇒ B): TraversableOnce[B] f: (A)就是函数对象,函数对象就是一个函数中的参数方法解析 map方法API说明泛型[B]指定map方法最终返回的集合泛型参数f: (A) ⇒ B传入一个函数对象该函数接收一个类型A(要转换的列表元素),返回值为类型B返回值TraversableOnce[B]B类型的集合map方法解析
创建一个列表,包含元素1,2,3,4 对List中的每一个元素加1 参考代码 scala> a.map(x=>x+1) res4: List[Int] = List(2, 3, 4, 5) 2.3 案例二创建一个列表,包含元素1,2,3,4 使用下划线来定义函数,对List中的每一个元素加1 参考代码 scala> val a = List(1,2,3,4) a: List[Int] = List(1, 2, 3, 4) scala> a.map(_ + 1) 3 扁平化映射 | flatMap扁平化映射也是将来用得非常多的操作,也是必须要掌握的。 3.1 定义可以把flatMap,理解为先map,然后再flatten
方法签名 def flatMap[B](f: (A) ⇒ GenTraversableOnce[B]): TraversableOnce[B]方法解析 flatmap方法API说明泛型[B]最终要转换的集合元素类型参数f: (A) ⇒ GenTraversableOnce[B]传入一个函数对象函数的参数是集合的元素函数的返回值是一个集合返回值TraversableOnce[B]B类型的集合 3.2 案例案例说明 有一个包含了若干个文本行的列表:“hadoop hive spark flink flume”, “kudu hbase sqoop storm”获取到文本行中的每一个单词,并将每一个单词都放到列表中思路分析
步骤 使用map将文本行拆分成数组再对数组进行扁平化参考代码 // 定义文本行列表 scala> val a = List("hadoop hive spark flink flume", "kudu hbase sqoop storm") a: List[String] = List(hadoop hive spark flink flume, kudu hbase sqoop storm) // 使用map将文本行转换为单词数组 scala> a.map(x=>x.split(" ")) res5: List[Array[String]] = List(Array(hadoop, hive, spark, flink, flume), Array(kudu, hbase, sqoop, storm)) // 扁平化,将数组中的 scala> a.map(x=>x.split(" ")).flatten res6: List[String] = List(hadoop, hive, spark, flink, flume, kudu, hbase, sqoop, storm)使用flatMap简化操作 参考代码 scala> val a = List("hadoop hive spark flink flume", "kudu hbase sqoop storm") a: List[String] = List(hadoop hive spark flink flume, kudu hbase sqoop storm) scala> a.flatMap(_.split(" ")) res7: List[String] = List(hadoop, hive, spark, flink, flume, kudu, hbase, sqoop, storm) 4 过滤 | filter过滤符合一定条件的元素
方法签名 def filter(p: (A) ⇒ Boolean): TraversableOnce[A]方法解析 filter方法API说明参数p: (A) ⇒ Boolean传入一个函数对象接收一个集合类型的参数返回布尔类型,满足条件返回true, 不满足返回false返回值TraversableOnce[A]列表
有一个数字列表,元素为:1,2,3,4,5,6,7,8,9 请过滤出所有的偶数 参考代码 scala> List(1,2,3,4,5,6,7,8,9).filter(_ % 2 == 0) res8: List[Int] = List(2, 4, 6, 8) 5 排序在scala集合中,可以使用以下几种方式来进行排序 sorted默认排序sortBy指定字段排序sortWith自定义排序 5.1 默认排序 | sorted示例 定义一个列表,包含以下元素: 3, 1, 2, 9, 7对列表进行升序排序参考代码 scala> List(3,1,2,9,7).sorted res16: List[Int] = List(1, 2, 3, 7, 9) 5.2 指定字段排序 | sortBy根据传入的函数转换后,再进行排序 **方法签名** def sortBy[B](f: (A) ⇒ B): List[A]方法解析 sortBy方法API说明泛型[B]按照什么类型来进行排序参数f: (A) ⇒ B传入函数对象接收一个集合类型的元素参数返回B类型的元素进行排序返回值List[A]返回排序后的列表示例 有一个列表,分别包含几下文本行:“01 hadoop”, “02 flume”, “03 hive”, “04 spark”请按照单词字母进行排序参考代码 scala> val a = List("01 hadoop", "02 flume", "03 hive", "04 spark") a: List[String] = List(01 hadoop, 02 flume, 03 hive, 04 spark) // 获取单词字段 scala> a.sortBy(_.split(" ")(1)) res8: List[String] = List(02 flume, 01 hadoop, 03 hive, 04 spark) 5.3 自定义排序 | sortWith自定义排序,根据一个函数来进行自定义排序 方法签名 def sortWith(lt: (A, A) ⇒ Boolean): List[A]方法解析 sortWith方法API说明参数lt: (A, A) ⇒ Boolean传入一个比较大小的函数对象接收两个集合类型的元素参数返回两个元素大小,小于返回true,大于返回false返回值List[A]返回排序后的列表示例 有一个列表,包含以下元素:2,3,1,6,4,5使用sortWith对列表进行降序排序参考代码 scala> val a = List(2,3,1,6,4,5) a: List[Int] = List(2, 3, 1, 6, 4, 5) scala> a.sortWith((x,y) => if(x res15.reverse res18: List[Int] = List(6, 5, 4, 3, 2, 1)使用下划线简写上述案例 参考代码 scala> val a = List(2,3,1,6,4,5) a: List[Int] = List(2, 3, 1, 6, 4, 5) // 函数参数只在函数中出现一次,可以使用下划线代替 scala> a.sortWith(_ 2), (“女” -> 1))参考代码 scala> val a = List("张三"->"男", "李四"->"女", "王五"->"男") a: List[(String, String)] = List((张三,男), (李四,女), (王五,男)) // 按照性别分组 scala> a.groupBy(_._2) res0: scala.collection.immutable.Map[String,List[(String, String)]] = Map(男 -> List((张三,男), (王五,男)), 女 -> List((李四,女))) // 将分组后的映射转换为性别/人数元组列表 scala> res0.map(x => x._1 -> x._2.size) res3: scala.collection.immutable.Map[String,Int] = Map(男 -> 2, 女 -> 1) 7 聚合操作聚合操作,可以将一个列表中的数据合并为一个。这种操作经常用来统计分析中 7.1 聚合 | reducereduce表示将列表,传入一个函数进行聚合计算 7.1.1 定义方法签名 def reduce[A1 >: A](op: (A1, A1) ⇒ A1): A1方法解析 reduce方法API说明泛型[A1 >: A](下界)A1必须是集合元素类型的子类参数op: (A1, A1) ⇒ A1传入函数对象,用来不断进行聚合操作第一个A1类型参数为:当前聚合后的变量第二个A1类型参数为:当前要进行聚合的元素返回值A1列表最终聚合为一个元素reduce执行流程分析
[NOTE] reduce和reduceLeft效果一致,表示从左到右计算 reduceRight表示从右到左计算 7.1.2 案例 定义一个列表,包含以下元素:1,2,3,4,5,6,7,8,9,10使用reduce计算所有元素的和参考代码 scala> val a = List(1,2,3,4,5,6,7,8,9,10) a: List[Int] = List(1, 2, 3, 4, 5, 6, 7, 8, 9, 10) scala> a.reduce((x,y) => x + y) res5: Int = 55 // 第一个下划线表示第一个参数,就是历史的聚合数据结果 // 第二个下划线表示第二个参数,就是当前要聚合的数据元素 scala> a.reduce(_ + _) res53: Int = 55 // 与reduce一样,从左往右计算 scala> a.reduceLeft(_ + _) res0: Int = 55 // 从右往左聚合计算 scala> a.reduceRight(_ + _) res1: Int = 55 7.2 折叠 | foldfold与reduce很像,但是多了一个指定初始值参数 7.2.1 定义方法签名 def fold[A1 >: A](z: A1)(op: (A1, A1) ⇒ A1): A1方法解析 reduce方法API说明泛型[A1 >: A](下界)A1必须是集合元素类型的子类参数1z: A1初始值参数2op: (A1, A1) ⇒ A1传入函数对象,用来不断进行折叠操作第一个A1类型参数为:当前折叠后的变量第二个A1类型参数为:当前要进行折叠的元素返回值A1列表最终折叠为一个元素[!NOTE] fold和foldLet效果一致,表示从左往右计算 foldRight表示从右往左计算 7.2.2 案例 定义一个列表,包含以下元素:1,2,3,4,5,6,7,8,9,10使用fold方法计算所有元素的和参考代码 scala> val a = List(1,2,3,4,5,6,7,8,9,10) a: List[Int] = List(1, 2, 3, 4, 5, 6, 7, 8, 9, 10) scala> a.fold(0)(_ + _) res4: Int = 155 |
 以上符号切勿混淆.
以上符号切勿混淆.








【本文地址】