| 被称为计算机视觉新里程碑的SAM模型到底是什么? | 您所在的位置:网站首页 › sam是什么意思英语 › 被称为计算机视觉新里程碑的SAM模型到底是什么? |
被称为计算机视觉新里程碑的SAM模型到底是什么?
|
SAM是Meta 提出的分割一切模型(Segment Anything Model,SAM)突破了分割界限,极大地促进了计算机视觉基础模型的发展。 SAM是一个提示型模型,其在1100万张图像上训练了超过10亿个掩码,实现了强大的零样本泛化。许多研究人员认为「这是 CV 的 GPT-3 时刻,因为 SAM 已经学会了物体是什么的一般概念,甚至是未知的物体、不熟悉的场景(如水下、细胞显微镜)和模糊的情况」,并展示了作为 CV 基本模型的巨大潜力。 SAM模型概览 2023年4月6号,Meta AI公开了Segment Anything Model(SAM),使用了有史以来最大的分割数据集Segment Anything 1-Billion mask dataset(SA-1B),其内包含了1100万张图像,总计超过10亿张掩码图,模型在训练时被设计为交互性的可提示模型,因此可以通过零样本学习转移到新的图像分布和任务中。在其中他们提出一个用于图像分割的基础模型,名为SAM。该模型被发现在NLP和CV领域中表现出较强的性能,研究人员试图建立一个类似的模型来统一整个图像分割任务。 SAM 架构主要包含三个部分:图像编码器;提示编码器;以及掩码解码器。 Meta AI提出一个大规模多样化的图像分割数据集:SA-1B(包含1100万张图片以及10亿个Mask图) 在这项工作中,SAM的目标是建立一个图像分割的基础模型(Foundation Models)。其目标是在给定任何分割提示下返回一个有效的分割掩码,并在一个大规模且支持强大泛化能力的数据集上对其进行预训练,然后用提示工程解决一系列新的数据分布上的下游分割问题。 项目关键的三部分包括组件:任务、模型、数据。 任务:在NLP和CV中,基础模型是一个很有前途的发展,受到启发,研究者提出了提示分割任务,其目标是在给定任何分割提示下返回一个有效的分割掩码。 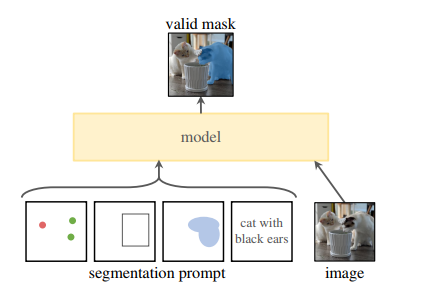  为此,研究者设计了Segment Anything Model(SAM),包含一个强大的图像编码器(计算图像嵌入),一个提示编码器(计算提示嵌入),一个轻量级掩码解码器(实时预测掩码)。在使用时,只需要对图像提取一次图像嵌入,可以在不同的提示下重复使用。给定一个图像嵌入,提示编码器和掩码解码器可以在浏览器中在~50毫秒内根据提示预测掩码。 |
【本文地址】
| 今日新闻 |
| 推荐新闻 |
| 专题文章 |