| 如何通过一致性聚类实现对表达谱数据的亚型分类 | 您所在的位置:网站首页 › r语言聚类分析结果解释 › 如何通过一致性聚类实现对表达谱数据的亚型分类 |
如何通过一致性聚类实现对表达谱数据的亚型分类
|
1 准备表达谱数据集
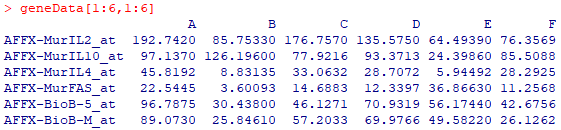
首先准备一个基因表达矩阵,将它读入到R中。可以是转录组(如RNA-seq,芯片数据等),也可以是定量蛋白组,或者蛋白磷酸化、糖基化等修饰。具体以哪种类型的数据为主,根据实际关注的问题来。如果您更期望使用转录组进行分型,就使用RNA表达谱;如果您更期望使用蛋白组进行分型,就使用蛋白定量谱;如果您更关注蛋白修饰的分型,就使用表观修饰的组学。 本次我们以Biobase包的芯片数据集为例,展示如何对基因表达谱执行一致性聚类分析。首先来看一下示例数据,该数据集一共包含26个样本,500个基因的表达谱。 !!!********************************************************** #以Biobase包的表达谱芯片数据集为例 library(Biobase) data(geneData) geneData[1:6,1:6] !!!**********************************************************
能够执行一致性聚类的R包很多,但基本原理都是差不多的。这里我们以ConsensusClusterPlus包的方法为例作为展示。 !!!********************************************************** #通过Bioconductor安装ConsensusClusterPlus包 #BiocManager::install("ConsensusClusterPlus") #加载ConsensusClusterPlus包 library(ConsensusClusterPlus) #对基因表达数据执行中位数中心化,以用于后续聚类 dc |
【本文地址】
公司简介
联系我们