| R语言实战之模型部署 | 您所在的位置:网站首页 › r语言保存模型 › R语言实战之模型部署 |
R语言实战之模型部署
|
R语言
R语言实战之模型部署
周震宇
关键词:模型部署; opencpu; fiery; plumber 审稿:郎大为 引言如果此时你对何谓模型部署仍然一无所知的话,不必有任何焦虑的心情,带你入门正是本文的目标所在。请相信我,这篇介绍将会是十分新手友好的,怀着好奇心和耐心读下去,你也会对模型部署建立起清晰的认识。 模型部署是商业统计建模中极其重要的一部分,然而却往往被人忽视。读完本文,你将了解模型部署的基本概念与用途,学会如何在R语言环境中使用网络服务来部署上线一个模型,更多地,你的方法武器库中将会增添几柄利器: opencpu、fiery 及 plumber。话不多说,让我们开始吧! 引入模型部署 什么是模型部署一句话概括,模型部署 是将一个调试好的模型应用置于生产或者类生产环境中,其意义在于处理预测新数据,为公司提供数据决策或者对接其他需求部门提供模型支持。我们先来看下面这幅数据科学项目开发流程图。
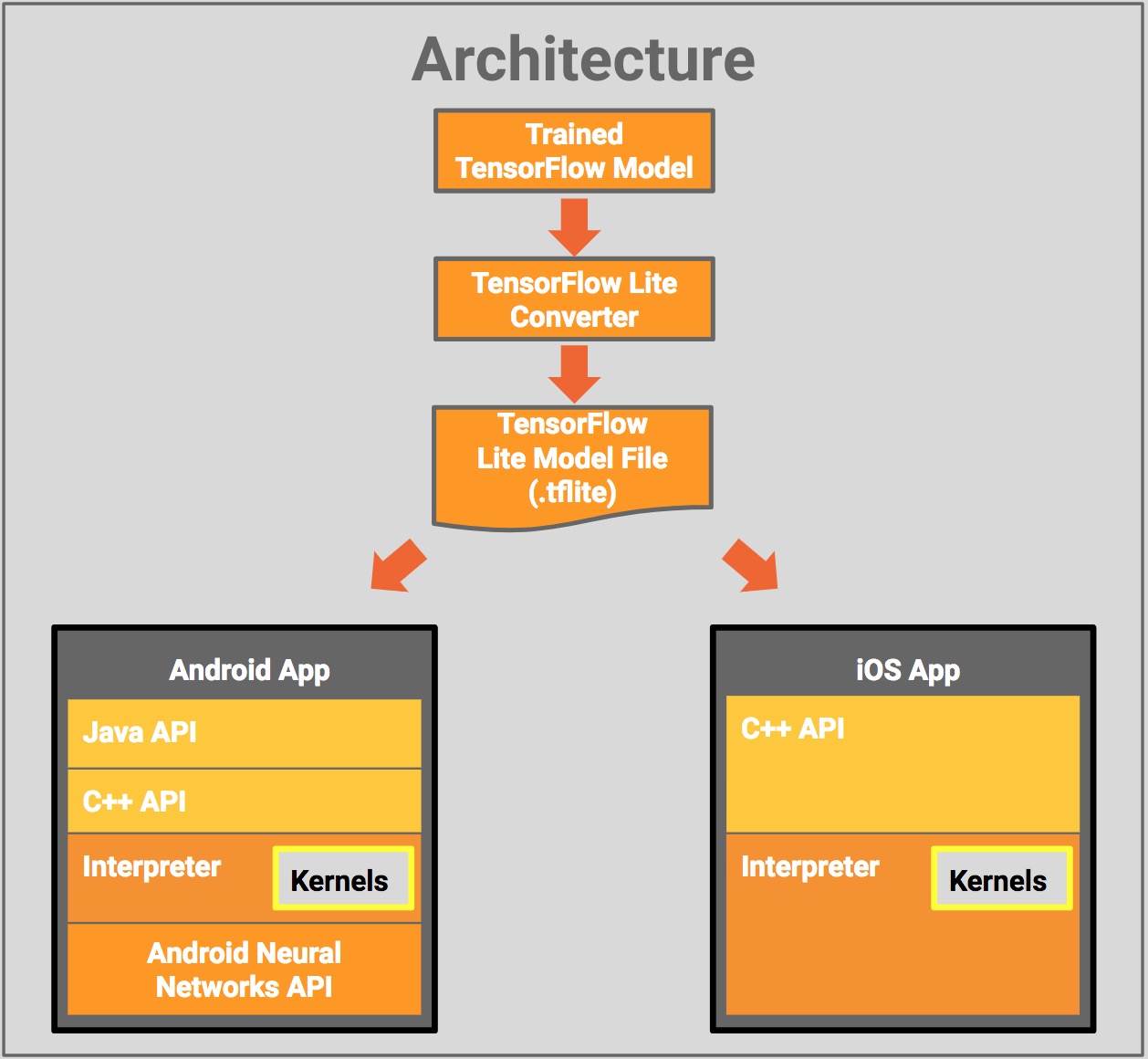
位于图片左边区域中的紫色圆圈中的文字,相信对大部分读者都不陌生。我们在学校中习得了很多关于数据科学模型、特征选择技巧及模型评价方法的知识,回想一下,在你过去大多数课程作业或是打比赛的经历中,完成了模型评价也就意味着项目宣告结束。然而在商业应用中,模型部署才标志着一个项目开发的阶段性结束。它的价值体现在两点: 赋予数据科学模型处理新数据的能力,可以是实时的流数据,或者是积累的批数据。 在实际应用场景中完成模型效果与性能的反馈,为模型调整提供依据,实现建模开发流程的闭环。 模型部署的手段首先我引述其中几种常用的模型部署的手段,接下来我们将会介绍借助R中的网络服务这种形式来搭建一个线上的模型。 各种工具/工件(artifact)有很多软件包均提供了将模型部署至小型终端设备上的功能。他们大都是将训练好的模型封装成一个对象并储存成自定义格式的文件,然后在相对应的平台或系统中加载调用这个对象,诸编程平台也大都有相应调用接口。 PMML (Predictive Model Markup Language) 是其中最常用的一种,它适合应用在实时、大规模数据量的场景。而在深度学习方面,TensorFlow 社区开发的 Tensorflow Lite 工具能翻译转换 tensorflow 预训练模型至 TensorFlow Lite 文件格式,然后用其他的接口来调用模型文件实现部署。除此之外还有一些其他的工具,可以参考R官网的 任务视图之模型部署部分,这里不再一一赘述。
注: 图片来源自 tensorflow 官网 云/服务器这种方式通过在服务器上开启一个服务的方式来部署模型,也是本文着力介绍的。主流的编程语言都有处理网络服务的功能,在 Python 中可以用 httpserver、flask、django 等搭建网络框架来部署;而 R语言做网络服务的包也不止一个,诸如 plumber、fiery、opencpu等。条条大路通罗马,本文不会对编程语言的选择提供任何建议。 既然是本文重点介绍的方式,不妨多啰嗦两句。 用网络服务做模型部署,将划分出线上与线下两个环境。线下环境是单机环境,用以做一些探索性或者验证性的分析,包含了分析建模的每一个步骤:特征工程、模型选择、模型评价、参数调节等 而线上环境则是生产环境,是把线下调整好参数的模型传至线上对新搜集的数据进行实时反馈。其背后的原理是借助 get&post 方法把特征字段传递给 web 服务器,服务器将会用封装好的模型预测并返回参数数值。对 get&post 不熟悉的可以参考 这个教程。 离线部署这种方式相对来说就比较稀松平常了。问离线部署共分几步?答:共分三步。写好模型脚本 xx.R 或 xx.py;把累积的新数据下载下来;执行 Rscript xx.R 或者 python xx.py。完事儿~ 闲话流数据前文说到模型部署的一大价值便在于它赋予了数据科学模型处理新数据的能力,而很多新数据通常是实时采集的流式数据。而在我看来,对于流式数据的陌生也是大部分同学在校期间对模型部署接触不多的一大原因,或者与数据采集环节的遥远导致我们把大部分的精力都投入在如何用模型把面前样本数据中的模式挖掘出来。在这种场景下,数据是固定的,被存放在.csv或者各式各样的文件中。 让我们的思路再向前推移一步,用以存放数据的各种数据库或者数据文件是像蓄水池一样逐渐蓄满了被传递进来的数据,而这些数据均是经过一定的技术手段实时采集而来。那么,对于新的观测,一个部署在生产环境中的模型便可以实时地处理预测这些数据:比如互联网金融公司便可根据一个新申请的用户提供的个人信息来预测这名用户的信用评分,垃圾过滤系统也可以获取实时的邮件内容来判断这是否是垃圾邮件。 实战环节得益于 RStudio 开发的工具包 httpuv,在 R 语言中处理 http 以及 Websocket 请求变成了现实,基于此工具包二次开发的框架 opencpu, fiery 和 plumber 提供了在线模型部署的解决方案,下面我们一一介绍: 场景实例:我们演示的场景为垃圾邮件拦截,数据来源自 ElemStatLearn 包 spam 数据集。把问题拆解为以下四个步骤来模拟实际生产环境。 根据线下数据训练模型 从线上 MySQL 数据库中获取新数据 将数据传递至部署在web服务器上的模型并返回预测值 使用预测值来决策首先我们进行一些准备工作: 安装所需要的程序包 Pkgs |

【本文地址】