| 基于YOLOv5的手势识别系统(含手势识别数据集+训练代码) | 您所在的位置:网站首页 › rockingroll手势 › 基于YOLOv5的手势识别系统(含手势识别数据集+训练代码) |
基于YOLOv5的手势识别系统(含手势识别数据集+训练代码)
|
基于YOLOv5的手势识别系统(含手势识别数据集+训练代码)
目录 目录 基于YOLOv5的手势识别系统(含手势识别数据集+训练代码) 1. 前言 2. 手势识别的方法 (1)基于多目标检测的手势识别方法 (2)基于手部检测+手势分类识别方法 3. 手势识别数据集说明 (1)HaGRID手势识别数据集 (2)自定义数据集 4. 基于YOLOv5的手势识别训练 (1)YOLOv5安装 (2)准备Train和Test数据 (3)配置数据文件 (4)配置模型文件 (5)重新聚类Anchor(可选) (6)开始训练 (7)可视化训练过程 (8)常见的错误 5. Python版本手势识别测试效果 6. Android版本手势识别 7.项目源码下载 1. 前言手势作为一种肢体语言,在人类交流中的使用起着重要作用。一个简单的手势蕴涵着丰富的信息,正因为如此,人与人可以之间通过手势来传达大量的信息,实现高速的通信。将手势运用于计算机,能够很好地改善人机交互的效率。
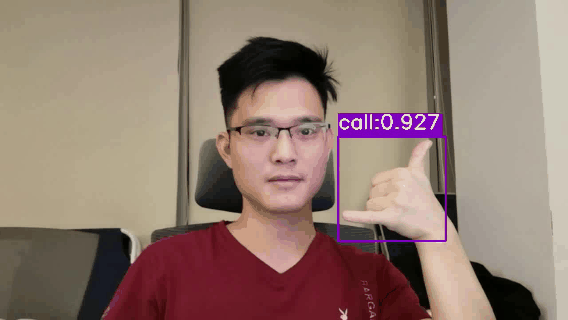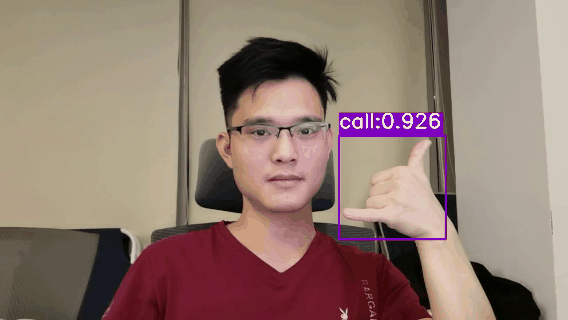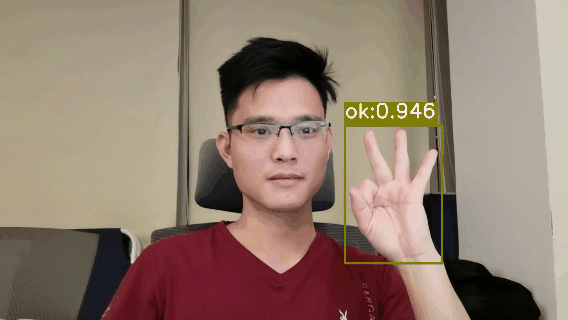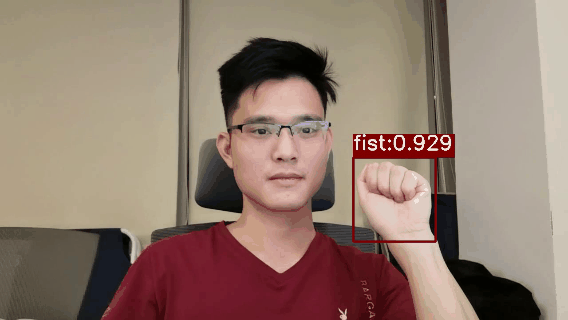
人类的手势主要分为: 1)交互性手势与操作性手势:前者手的运动表示特定的信息(如乐队指挥),靠视觉来感知,后者不表达任何信息(如弹琴)。 2)自主性手势和非自主性手势:后者与语音配合用来加强或补充某些信息(如演讲者用手势描述动作、空间结构等信息)。 3)离心手势和向心手势:前者直接针对说话人,有明确的交流意图,后者只是反映说话人的情绪和内心的愿望。 手势识别(HGR)作为人机交互的一部分,在汽车领域、家庭自动化系统、各种视频/流媒体平台等领域具有广泛的实际应用。本篇博客,将基于YOLOv5搭建一个手势识别目标检测系统,支持one,two,ok等18种常见的通用手势动作识别,目前基于多目标检测的手势识别方法YOLOv5s的平均精度平均值mAP_0.5=0.99569,mAP_0.5:0.95=0.87605,基本满足业务的性能需求。 另外,为了能部署在手机Android平台,本人对YOLOv5s进行了模型轻量化,开发了一个轻量级的版本,yolov5s05,在普通Android手机上可以达到实时的手势识别效果,CPU(4线程)约30ms左右,GPU约25ms左右 ,基本满足业务的性能需求。 先展示一下Python版本手势识别Demo视频效果:
【源码下载】 基于YOLOv5的手势识别系统(含手势识别数据集+训练代码) 【尊重原创,转载请注明出处】https://blog.csdn.net/guyuealian/article/details/126750433 还有更多Android版本的手势识别效果:Android手部检测和手势识别(含训练代码+Android源码+手势识别数据集)_PKing666666的博客-CSDN博客    2. 手势识别的方法
(1)基于多目标检测的手势识别方法
2. 手势识别的方法
(1)基于多目标检测的手势识别方法
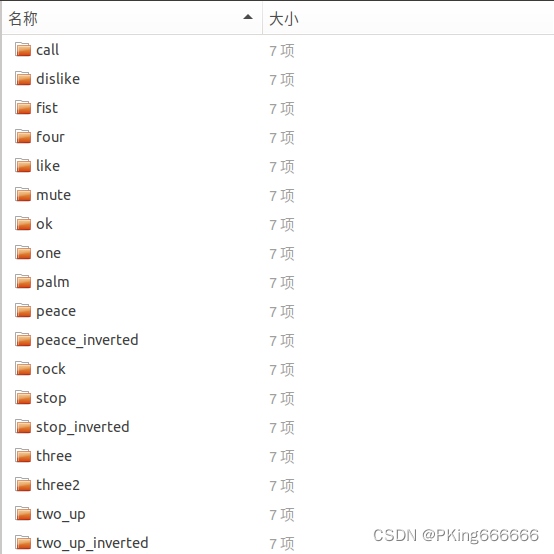
基于多目标检测的手势识别方法,一步到位,把手势类别直接当成多个目标检测的类别进行训练。 该方案采用one-stage的方法,直接端到端训练,任务简单,速度较快;新增类别或者数据,需要人工拉框标注手势,成本较大需要均衡采集的不同手势类别的样本数部署简单 (2)基于手部检测+手势分类识别方法该方法,先训练一个通用的手部检测模型(不区分手势,只检测手部框),然后裁剪手部区域,再训练一个手势分类器,完成对不同手势的分类识别。 该方案采用two-stage方法,可针对性分别提高检测模型和分类模型的性能手部检测模型不区分手势,只检测手部框,检测精度较高,手势分类模型可以做到很轻量手势分类数据比较容易采集(你可以采集一个动手一个视频,这样经过手部检测裁剪下来的图片都是同一个类别的动作,减少人工拉框标注手势的成本)由于采用two-stage方法进行检测-识别,因此速度相对较慢考虑到HaGRID手势识别数据集,所有图片已经标注了手势类别和检测框,因此采用“基于多目标检测的手势识别方法”更为简单。本篇博客就是基于多目标检测的手势识别方法,多目标检测的的方法较多,比如Faster-RCNN,YOLO系列,SSD等均可以采用,本博客将采用YOLOv5进行多目标检测的手势识别训练。 如果你的数据集仅有部分检测框,但手势分类图片的数据集比较容易采集,建议使用“基于手部检测+手势分类识别方法”,毕竟这方案标注成本比较低。若你需要这个方案,可以微信公众号联系我。 3. 手势识别数据集说明 (1)HaGRID手势识别数据集原始的HaGRID数据集非常大,图片都是高分辨率(1920 × 1080)200W像素,完整下载HaGRID数据集,至少需要716GB的硬盘空间。另外,由于是外网链接,下载可能经常掉线。 考虑到这些问题,本人对HaGRID数据集进行精简和缩小分辨率,目前整个数据集已经压缩到18GB左右,可以满足手势识别分类和检测的任务需求,为了有别于原始数据集,该数据集称为Light-HaGRID数据集,即一个比较轻量的手势识别数据集。 提供手势动作识别数据集,共18个手势类别,每个类别约含有7000张图片,总共123731张图片(12W+)提供所有图片的json标注格式文件,即原始HaGRID数据集的标注格式提供所有图片的XML标注格式文件,即转换为VOC数据集的格式提供所有手势区域的图片,每个标注框的手部区域都裁剪下来,并保存在Classification文件夹下可用于手势目标检测模型训练可用于手势分类识别模型训练关于《HaGRID手势识别数据集使用说明和下载》,请参考鄙人另一篇博客, HaGRID手势识别数据集使用说明和下载_AI吃大瓜的博客-CSDN博客
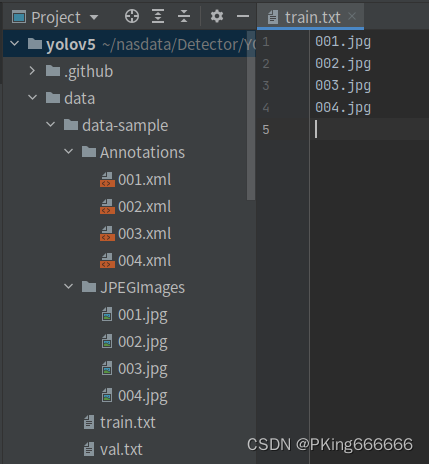
如果需要增/删类别数据进行训练,或者需要自定数据集进行训练,可参考如下步骤: 采集手势图片,建议不少于200张图片使用Labelme等标注工具,对手势拉框标注:labelme工具:GitHub - wkentaro/labelme: Image Polygonal Annotation with Python (polygon, rectangle, circle, line, point and image-level flag annotation).将标注格式转换为VOC数据格式,参考工具:labelme/labelme2voc.py at main · wkentaro/labelme · GitHub生成训练集train.txt和验证集val.txt文件列表修改engine/configs/voc_local.yaml的train和val的数据路径重新开始训练
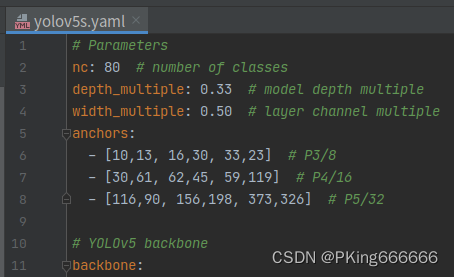
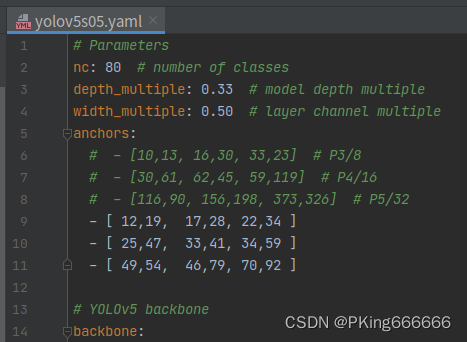
训练Pipeline采用YOLOv5: https://github.com/ultralytics/yolov5 , 原始代码训练需要转换为YOLO的格式,不支持VOC的数据格式。为了适配VOC数据,本人新增了LoadVOCImagesAndLabels用于解析VOC数据集进行训练。另外,为了方便测试,还增加demo.py文件,可支持对图片和视频的测试。 Python依赖环境: matplotlib>=3.2.2 numpy>=1.18.5 opencv-python>=4.1.2 Pillow PyYAML>=5.3.1 scipy>=1.4.1 torch>=1.7.0 torchvision>=0.8.1 tqdm>=4.41.0 tensorboard>=2.4.1 seaborn>=0.11.0 pandas thop # FLOPs computation pybaseutils项目安装教程请参考(初学者入门,麻烦先看完下面教程,配置好开发环境): 项目开发使用教程和常见问题和解决方法视频教程:1 手把手教你安装CUDA和cuDNN(1)视频教程:2 手把手教你安装CUDA和cuDNN(2)视频教程:3 如何用Anaconda创建pycharm环境视频教程:4 如何在pycharm中使用Anaconda创建的python环境 (2)准备Train和Test数据下载HaGRID手势识别数据集,这个数据至少需要716GB的硬盘空间,超大哦;如果你想偷点懒,那就直接采用Light-HaGRID数据集下载,才18GB,数据格式都已经处理好,可以直接拿来使用。关于《HaGRID手势识别数据集使用说明和下载》,请参考鄙人另一篇博客: HaGRID手势识别数据集使用说明和下载_PKing666666的博客-CSDN博客 (3)配置数据文件 修改训练和测试数据的路径:engine/configs/voc_local.yaml (一共有18个手势文件夹,全部加上)注意数据路径分隔符使用【/】,不是【\】项目不要出现含有中文字符的目录文件或路径,否则会出现很多异常! # 数据路径 path: "" # 不需要修改,dataset root dir # 注意数据路径分隔符使用【/】,不是【\】 # 项目不要出现含有中文字符的目录文件或路径,否则会出现很多异常! train: - "D:/dataset/csdn/gesture/Light-HaGRID/trainval/call/train.txt" - "D:/dataset/csdn/gesture/Light-HaGRID/trainval/dislike/train.txt" - "D:/dataset/csdn/gesture/Light-HaGRID/trainval/fist/train.txt" - "D:/dataset/csdn/gesture/Light-HaGRID/trainval/four/train.txt" - "D:/dataset/csdn/gesture/Light-HaGRID/trainval/like/train.txt" - "D:/dataset/csdn/gesture/Light-HaGRID/trainval/mute/train.txt" - "D:/dataset/csdn/gesture/Light-HaGRID/trainval/ok/train.txt" - "D:/dataset/csdn/gesture/Light-HaGRID/trainval/one/train.txt" - "D:/dataset/csdn/gesture/Light-HaGRID/trainval/palm/train.txt" - "D:/dataset/csdn/gesture/Light-HaGRID/trainval/peace/train.txt" - "D:/dataset/csdn/gesture/Light-HaGRID/trainval/peace_inverted/train.txt" - "D:/dataset/csdn/gesture/Light-HaGRID/trainval/rock/train.txt" - "D:/dataset/csdn/gesture/Light-HaGRID/trainval/stop/train.txt" - "D:/dataset/csdn/gesture/Light-HaGRID/trainval/stop_inverted/train.txt" - "D:/dataset/csdn/gesture/Light-HaGRID/trainval/three/train.txt" - "D:/dataset/csdn/gesture/Light-HaGRID/trainval/three2/train.txt" - "D:/dataset/csdn/gesture/Light-HaGRID/trainval/two_up/train.txt" - "D:/dataset/csdn/gesture/Light-HaGRID/trainval/two_up_inverted/train.txt" val: - "D:/dataset/csdn/gesture/Light-HaGRID/trainval/call/val.txt" - "D:/dataset/csdn/gesture/Light-HaGRID/trainval/dislike/val.txt" - "D:/dataset/csdn/gesture/Light-HaGRID/trainval/fist/val.txt" - "D:/dataset/csdn/gesture/Light-HaGRID/trainval/four/val.txt" - "D:/dataset/csdn/gesture/Light-HaGRID/trainval/like/val.txt" - "D:/dataset/csdn/gesture/Light-HaGRID/trainval/mute/val.txt" - "D:/dataset/csdn/gesture/Light-HaGRID/trainval/ok/val.txt" - "D:/dataset/csdn/gesture/Light-HaGRID/trainval/one/val.txt" - "D:/dataset/csdn/gesture/Light-HaGRID/trainval/palm/val.txt" - "D:/dataset/csdn/gesture/Light-HaGRID/trainval/peace/val.txt" - "D:/dataset/csdn/gesture/Light-HaGRID/trainval/peace_inverted/val.txt" - "D:/dataset/csdn/gesture/Light-HaGRID/trainval/rock/val.txt" - "D:/dataset/csdn/gesture/Light-HaGRID/trainval/stop/val.txt" - "D:/dataset/csdn/gesture/Light-HaGRID/trainval/stop_inverted/val.txt" - "D:/dataset/csdn/gesture/Light-HaGRID/trainval/three/val.txt" - "D:/dataset/csdn/gesture/Light-HaGRID/trainval/three2/val.txt" - "D:/dataset/csdn/gesture/Light-HaGRID/trainval/two_up/val.txt" - "D:/dataset/csdn/gesture/Light-HaGRID/trainval/two_up_inverted/val.txt" test: # test images (optional) data_type: voc # Classes nc: 19 # number of classes names: { 'one': 0, 'two_up': 1, 'two_up_inverted': 2, 'three': 3, 'three2': 4, 'four': 5, 'fist': 6, 'palm': 7, 'ok': 8, 'peace': 9, 'peace_inverted': 10, 'like': 11, 'dislike': 12, 'stop': 13, 'stop_inverted': 14, 'call': 15, 'mute': 16, 'rock': 17, 'no_gesture': 18 }HaGRID手势识别数据集一共有18个手势,额外还有一个无手势的类别,即no_gesture;如果你想自定义手势类型,比如你希望只训练one,tow,three,four和no_gesture类别,请修改,请修改: names: { 'one': 0, 'two_up': 1, 'three': 2, 'four': 3, 'no_gesture': 4 } nc: 5 (4)配置模型文件官方YOLOv5给出了YOLOv5l,YOLOv5m,YOLOv5s等模型,这里仅仅考虑YOLOv5s模型。考虑到手机端CPU/GPU性能比较弱鸡,直接部署yolov5s运行速度十分慢。所以本人在yolov5s基础上进行模型轻量化处理,即将yolov5s的模型的channels通道数全部都减少一半,并且模型输入由原来的640×640降低到320×320,该轻量化的模型我称之为yolov5s05。从性能来看,yolov5s05比yolov5s快5多倍,而mAP下降了5%(0.87605→0.82706),对于手机端,这精度还是可以接受。 官方YOLOv5: https://github.com/ultralytics/yolov5 下面是yolov5s05和yolov5s的参数量和计算量对比: 模型input-sizeparams(M)GFLOPs手势识别mAP(0.5:0.95)yolov5s640×6407.216.50.87605yolov5s05320×3201.71.10.82706 (5)重新聚类Anchor(可选)官方yolov5s的Anchor是基于COCO数据集进行聚类获得(详见models/yolov5s.yaml文件) 对于yolov5s05的Anchor,重新聚类的结果: 而不同的数据集最优Anchor自然需要重新聚类,做适当的调整 。当然你要是觉得麻烦就跳过,不需要重新聚类Anchor,这个影响不是很大。如果你需要重新聚类,请参考engine/kmeans_anchor/demo.py文件 (6)开始训练整套训练代码非常简单操作,用户只需要将相同类别的数据放在同一个目录下,并填写好对应的数据路径,即可开始训练了。 修改训练超参文件: data/hyps/hyp.scratch-v1.yaml (可以修改训练学习率,数据增强等方式,使用默认即可)Linux系统终端运行,训练yolov5s或轻量化版本yolov5s05 (选择其中一个训练即可): #!/usr/bin/env bash #--------------训练yolov5s-------------- # 输出项目名称路径 project="runs/yolov5s" # 训练和测试数据的路径 data="engine/configs/voc_local.yaml" # YOLOv5模型配置文件 cfg="yolov5s.yaml" # 训练超参数文件 hyp="data/hyps/hyp.scratch-v1.yaml" # 预训练文件 weights="engine/pretrained/yolov5s.pt" python train.py --data $data --cfg $cfg --hyp $hyp --weights $weights --batch-size 16 --imgsz 640 --workers 4 --project $project #--------------训练轻量化版本yolov5s05-------------- # 输出项目名称路径 project="runs/yolov5s05" # 训练和测试数据的路径 data="engine/configs/voc_local.yaml" # YOLOv5模型配置文件 cfg="yolov5s05.yaml" # 训练超参数文件 hyp="data/hyps/hyp.scratch-v1.yaml" # 预训练文件 weights="engine/pretrained/yolov5s.pt" python train.py --data $data --cfg $cfg --hyp $hyp --weights $weights --batch-size 16 --imgsz 320 --workers 4 --project $project Windows系统终端运行,训练yolov5s或轻量化版本yolov5s05 (选择其中一个训练即可): #!/usr/bin/env bash #--------------训练yolov5s-------------- python train.py --data engine/configs/voc_local.yaml --cfg yolov5s.yaml --hyp data/hyps/hyp.scratch-v1.yaml --weights engine/pretrained/yolov5s.pt --batch-size 16 --imgsz 640 --workers 4 --project runs/yolov5s #--------------训练轻量化版本yolov5s05-------------- python train.py --data engine/configs/voc_local.yaml --cfg yolov5s05.yaml --hyp data/hyps/hyp.scratch-v1.yaml --weights engine/pretrained/yolov5s.pt --batch-size 16 --imgsz 320 --workers 4 --project runs/yolov5s05 开始训练:
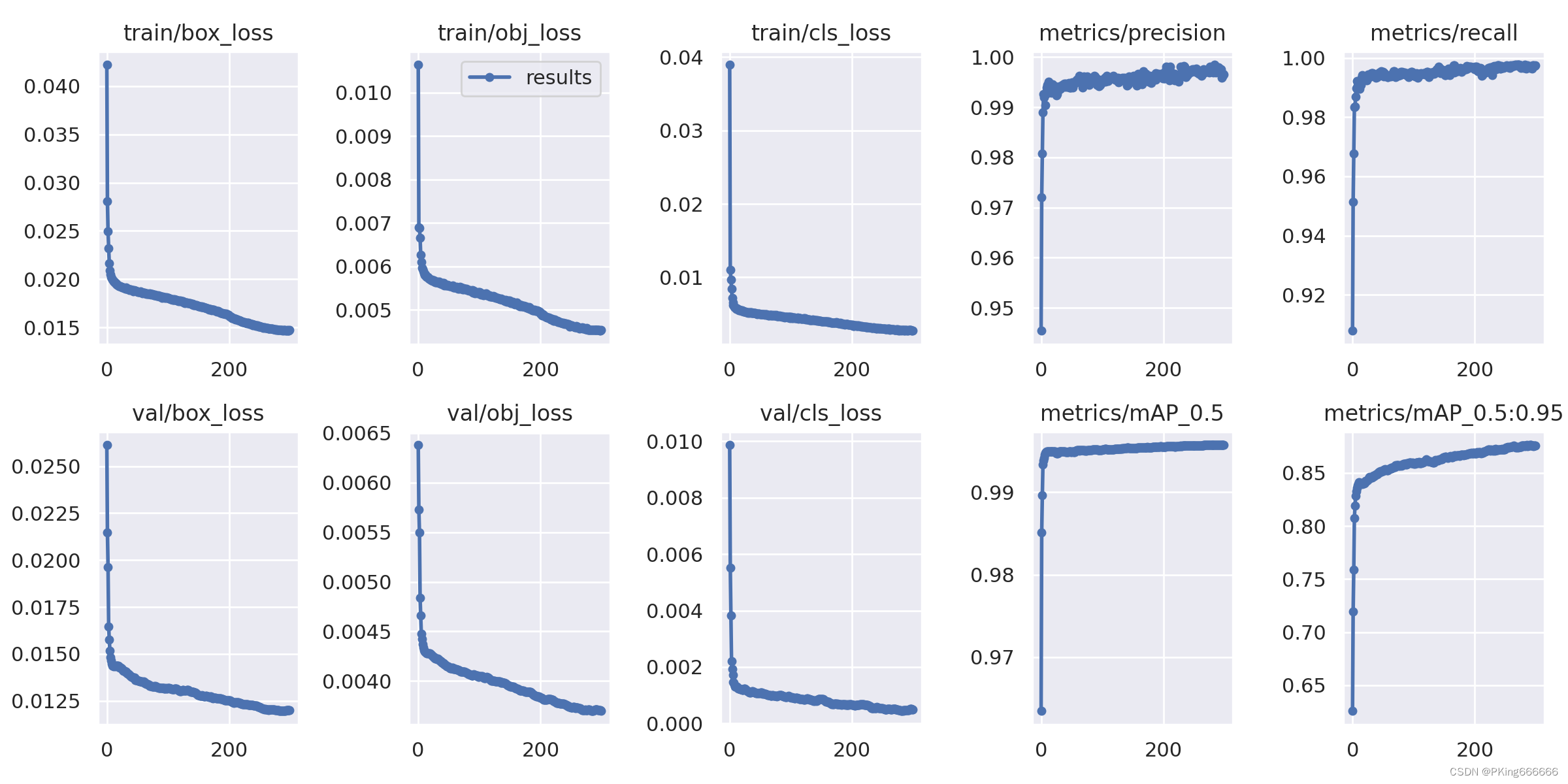
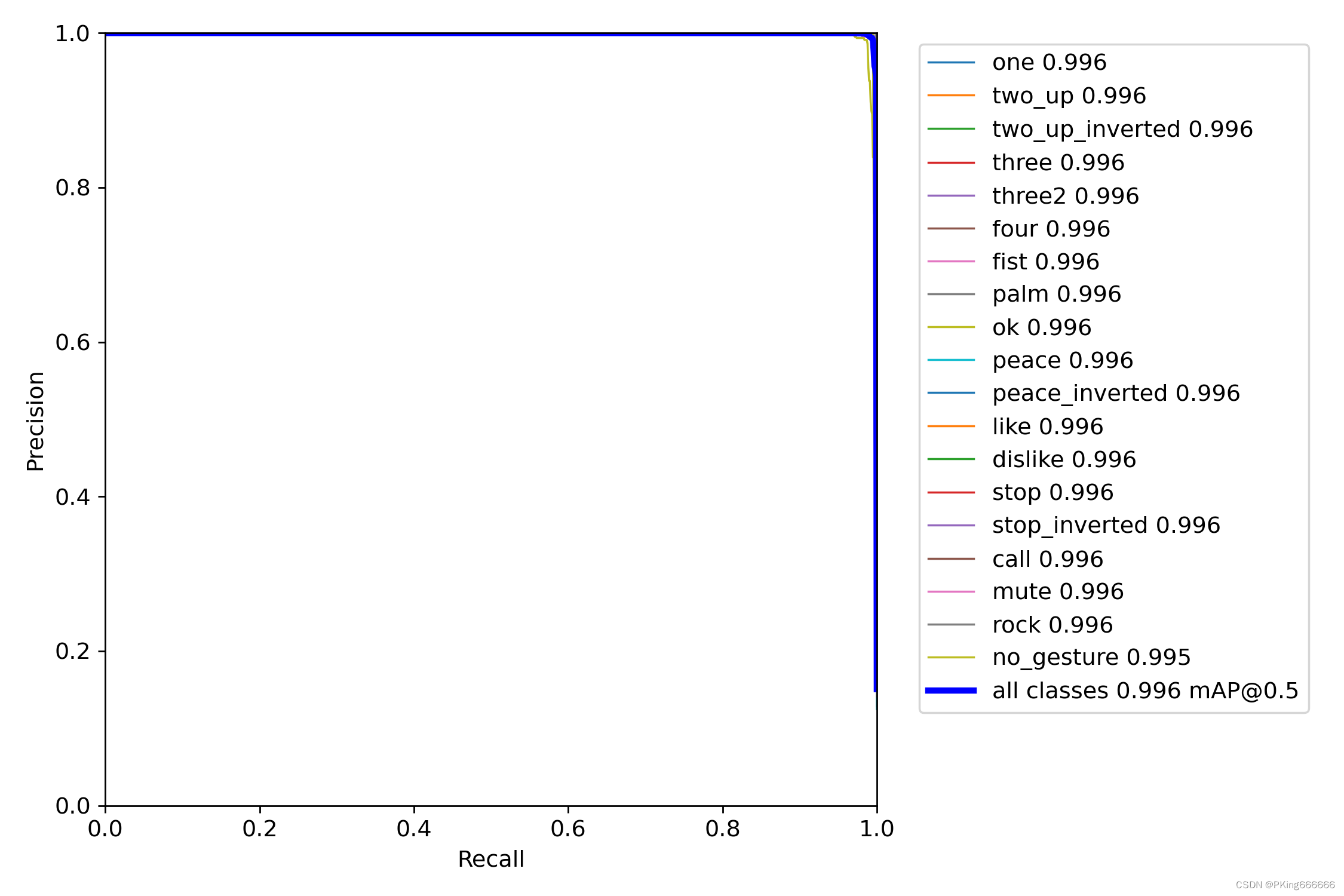
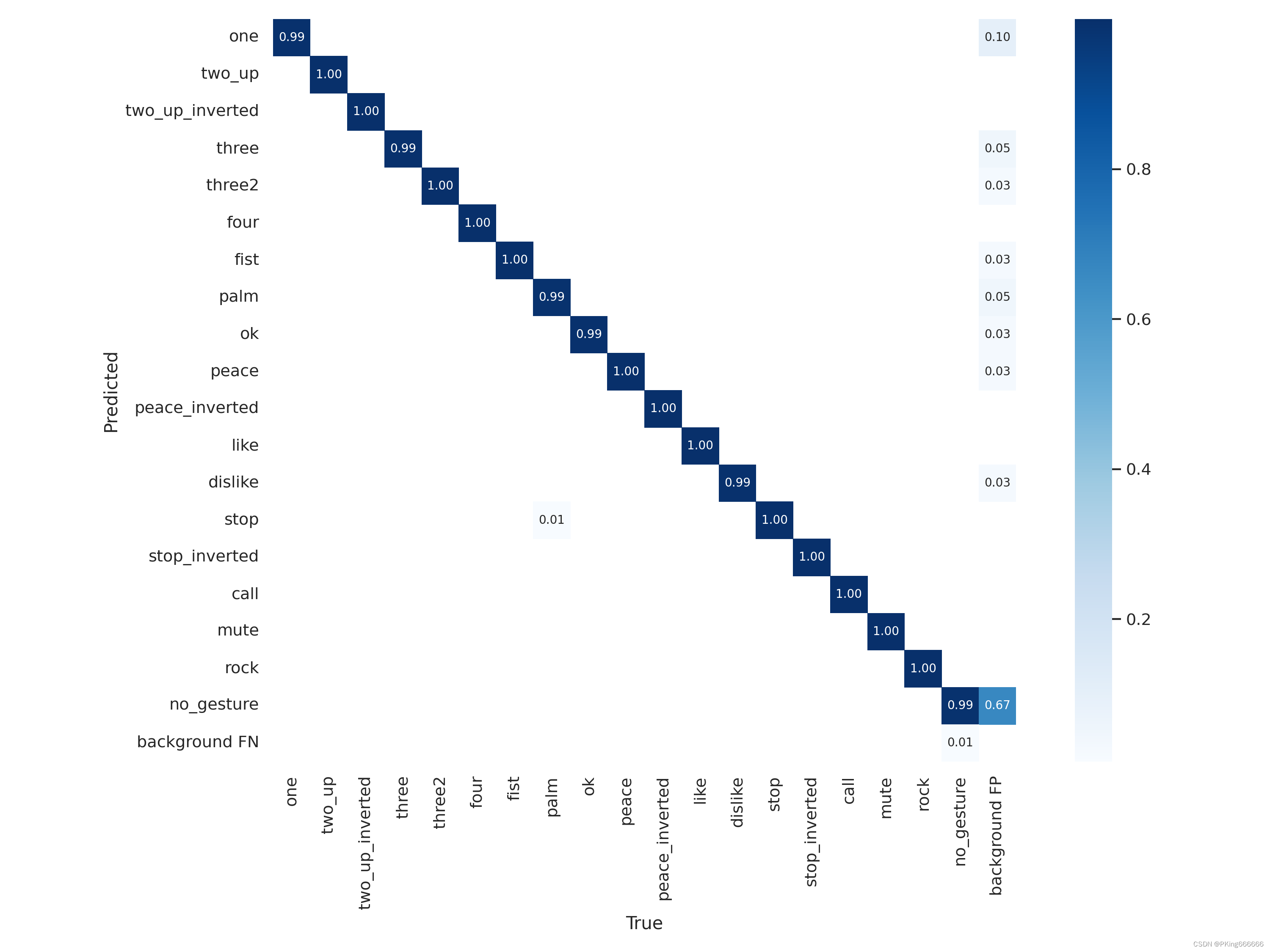
训练完成,可以得到yolov5s手势识别mAP指标大约mAP_0.5=0.99569,mAP_0.5:0.95=0.87605 ;而yolov5s05手势识别mAP指标大约mAP_0.5=0.99421,mAP_0.5:0.95=0.82706 (7)可视化训练过程 训练过程可视化工具是使用Tensorboard,使用方法,在终端输入: # 基本方法 tensorboard --logdir=path/to/log/ # 例如 tensorboard --logdir ./runs/yolov5s_640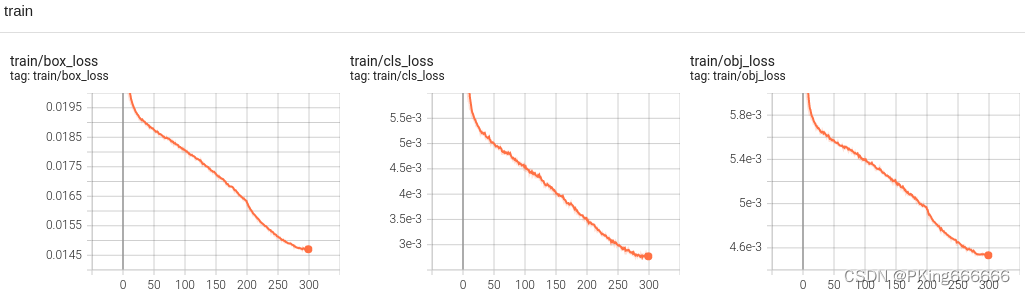 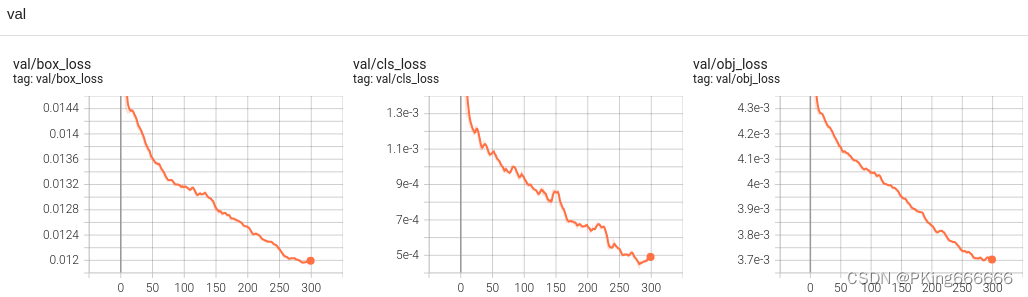 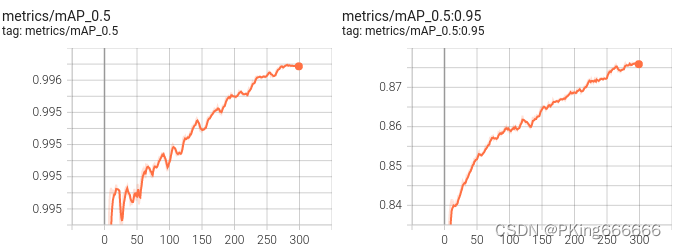 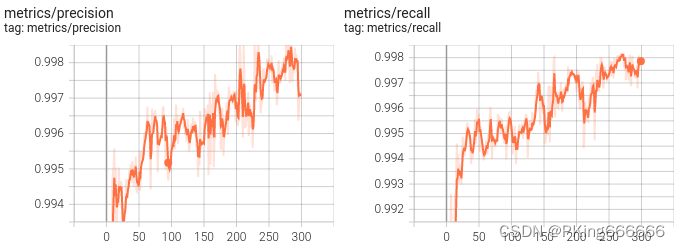
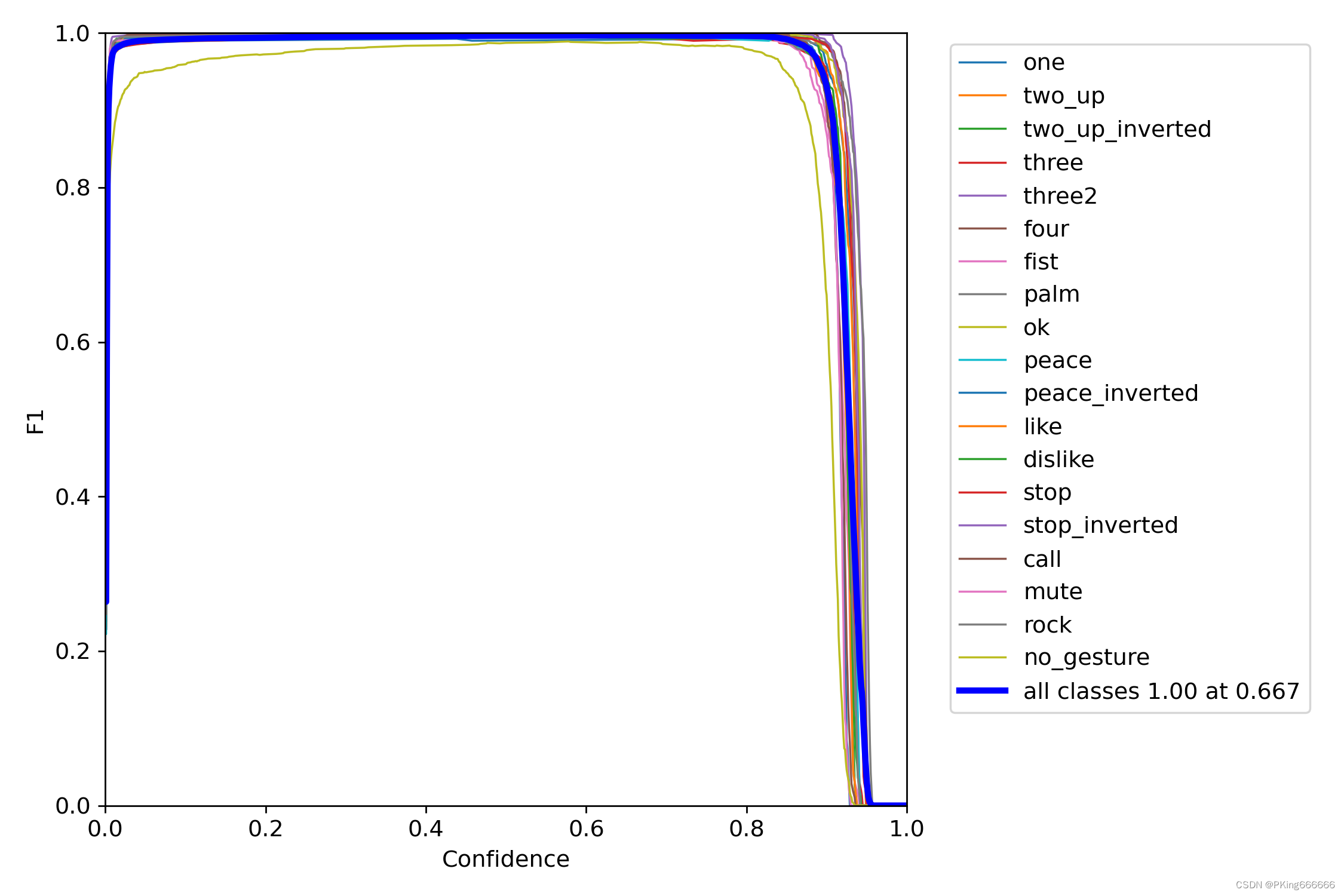
当然,在输出目录,也保存很多性能指标的图片 这是训练epoch的可视化图,可以看到mAP随着Epoch训练,逐渐提高
demo.py文件用于推理和测试模型的效果,填写好配置文件,模型文件以及测试图片即可运行测试了 测试图片 # 测试视频文件(Linux系统) image_dir='data/HaGRID-test' # 测试图片的目录 weights="runs/yolov5s_640/weights/best.pt" # 模型文件 out_dir="runs/HaGRID-result" # 保存检测结果 python demo.py --image_dir $image_dir --weights $weights --out_dir $out_dirWindows系统,请将$image_dir, $weights ,$out_dir等变量代替为对应的变量值即可,如 # 测试图片(Windows系统) python demo.py --image_dir data/HaGRID-test --weights runs/yolov5s_640/weights/best.pt --out_dir runs/HaGRID-result 测试视频文件 # 测试视频文件(Linux系统) video_file="path/to/video.mp4" # 测试视频文件,如*.mp4,*.avi等 weights="runs/yolov5s_640/weights/best.pt" # 模型文件 out_dir="runs/HaGRID-result" # 保存检测结果 python demo.py --video_file $video_file --weights $weights --out_dir $out_dir # 测试视频文件(Windows系统) python demo.py --video_file path/to/video.mp4 --weights runs/yolov5s_640/weights/best.pt --out_dir runs/HaGRID-result 测试摄像头 # 测试摄像头(Linux系统) video_file=0 # 测试摄像头ID weights="runs/yolov5s_640/weights/best.pt" # 模型文件 out_dir="runs/HaGRID-result" # 保存检测结果 python demo.py --video_file $video_file --weights $weights --out_dir $out_dir # 测试摄像头(Windows系统) python demo.py --video_file 0 --weights runs/yolov5s_640/weights/best.pt --out_dir runs/HaGRID-result测试Demo效果图:
如果想进一步提高模型的性能,可以尝试: 增加样本数据: 原始数据集,基本上都是欧美白色人的图片数据,缺乏亚洲人脸数据集,建议根据自己的业务场景,采集相关数据,提高模型泛化能力使用参数量更大的模型: 本教程使用的YOLOv5s,其参数量才7.2M,而YOLOv5x的参数量有86.7M,理论上其精度更高,但推理速度也较慢。尝试不同数据增强的组合进行训练 6. Android版本手势识别已经完成Android版本的手势识别开发,APP在普通Android手机上可以达到实时的手势识别效果,CPU(4线程)约30ms左右,GPU约25ms左右 ,基本满足业务的性能需求。 Android实现手部检测和手势识别(可实时运行,含Android源码) Android Demo效果:
【Android APP体验】Android实时手势动作识别APPDemo-Android文档类资源-CSDN下载 7.项目源码下载整套项目源码内容包含Light-HaGRID数据集 + YOLOv5训练代码和测试代码:基于YOLOv5的手势识别系统(含手势识别数据集+训练代码) (1)Light-HaGRID数据集 提供手势动作识别数据集,共18个手势类别,每个类别约含有7000张图片,总共123731张图片(12W+)提供所有图片的json标注格式文件,即原始HaGRID数据集的标注格式提供所有图片的XML标注格式文件,即转换为VOC数据集的格式提供所有手势区域的图片,每个标注框的手部区域都裁剪下来,并保存在Classification文件夹下可用于手势目标检测模型训练可用于手势分类识别模型训练(2)YOLOv5训练代码和测试代码(Pytorch) 整套YOLOv5项目工程,含训练代码train.py和测试代码demo.py支持高精度版本yolov5s训练和测试支持轻量化版本yolov5s05_320训练和测试根据本篇博文说明,简单配置即可开始训练:train.py源码包含了训练好的yolov5s和yolov5s05_320模型,配置好环境,可直接运行demo.py测试代码demo.py支持图片,视频和摄像头测试如果你需要Android版本的手势识别,请参考文章:Android实现手部检测和手势识别(可实时运行,含Android源码) |


【本文地址】