| RabbitMQ | 您所在的位置:网站首页 › rabbitmq一个队列最多能存多少消息 › RabbitMQ |
RabbitMQ
|
背景 在实际使用过程,会遇到这么些情况: 生产者发送的消息数量与消费者接收的消息数量不一致。例如生产者向rabbitmq投递了100条消息,消费者只从队列中接收到了80条消息,并且当前队列中已经没有任何消息。 要定位这个问题,通常是分段来定位,一方面统计生产者到底发送了多少消息,一方面统计有多少消息是正确路由到指定队列的,两者进行比较判断生产者发送是否有问题,如果数量一致,也就是生产者发送的消息都正确到队列后,基本可以断定是消费端的问题。比如消费者本身的逻辑处理不对,或者有其他消费者到该队列消费了一部分数据等。 那么这里有个问题:怎样正确统计到底有多少消息发送到了指定队列?尤其是生产、消费同时进行时,怎样进行正确统计?或者该问题变相的变成一条运维需求,即统计一个时间段内发布到指定队列的消息数。 可能的解决办法 1、抓包或者开启trace来追踪消息进出rabbitmq的情况 然而这种方式仅适用于开发调试阶段,当消息量达到一定程度时,trace会严重影响性能,而抓包也不一定能在正确时刻找到有问题的包。 2、针对有问题的队列,再建一个队列,并以同样的binding-key绑定到同样的exchange上。这样一来,生产者发送过来的消息,会同时进入到两个队列,其中一个队列中的消息被消费者消费掉,新建的队列因没有消费者可保留全部的消息,我们只需要看这个队列中的消息数就可以完成统计工作。 同样,这种办法也是存在一些问题的。首先,消息在队列中堆积,会占用rabbitmq的内存或磁盘空间,从而影响rabbitmq的整体性能。有人可能会问,那再开发个程序,消费这个队列中的消息但不做任何处理,仅仅是进行计数统计,是不是就解决问题了。然而并不是这样,因为一个消息同时路由进入到多个队列,对于生产者的性能也是有损耗的(尤其是一个消息路由到6个以上的队列)。 另一种可行方法 在rabbitmq中,每个消息在队列中会有一个对应的序号,这个序号是每个队列独立维护的。该序号的意义主要是保证消息按照先进先出的方式有序被消费者消费。 其内部实现,每个队列的状态信息中,维护了一个字段:next_seq_id。该字段表示下一条进入队列的消息的序号。每当有消息发送到队列时,该值会加1,同时每个消息的序号也作为消息索引的一部分持久化到文件中了,这样rabbitmq重启后,队列中的消息依然是可以按照有序的方式被消费者消费。 我们可以定期获取该字段对应的值,前后两次的差值就是这个时间段内进入队列的消息总数。 获取方式 可以通过http接口来获取指定队列该字段的值。 如下图所示,两次查看spurs这个队列信息之间,一共发送了3条消息。 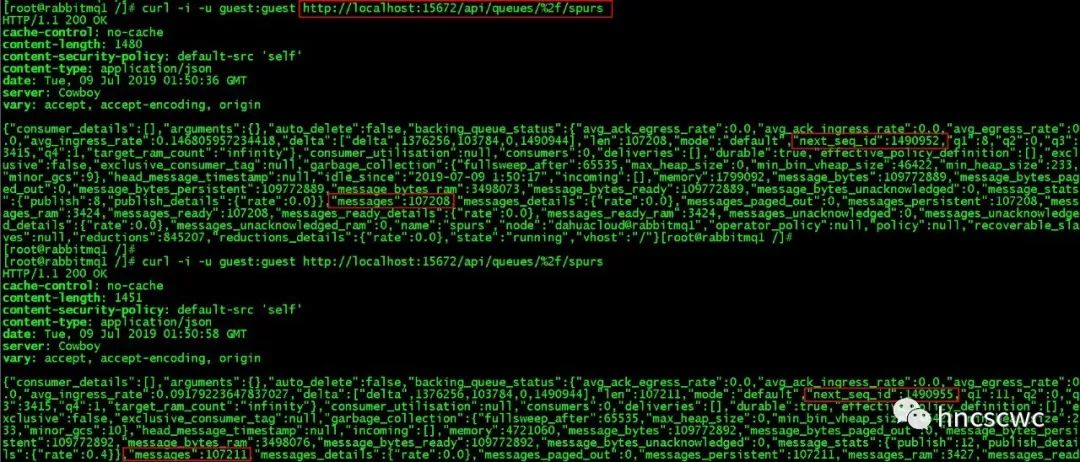 当然,我们也可以不指定队列,即查看全部队列的信息,并从中获取next_seq_id字段对应的值。 除此之外,rabbitmq的插件rabbitmq_management中提供了管理控制台的命令行工具rabbitmqadmin,该工具本质上也是通过http的方式调用对应接口获取相关信息,可以理解为是封装成了一个可执行程序(脚本)。 例如: 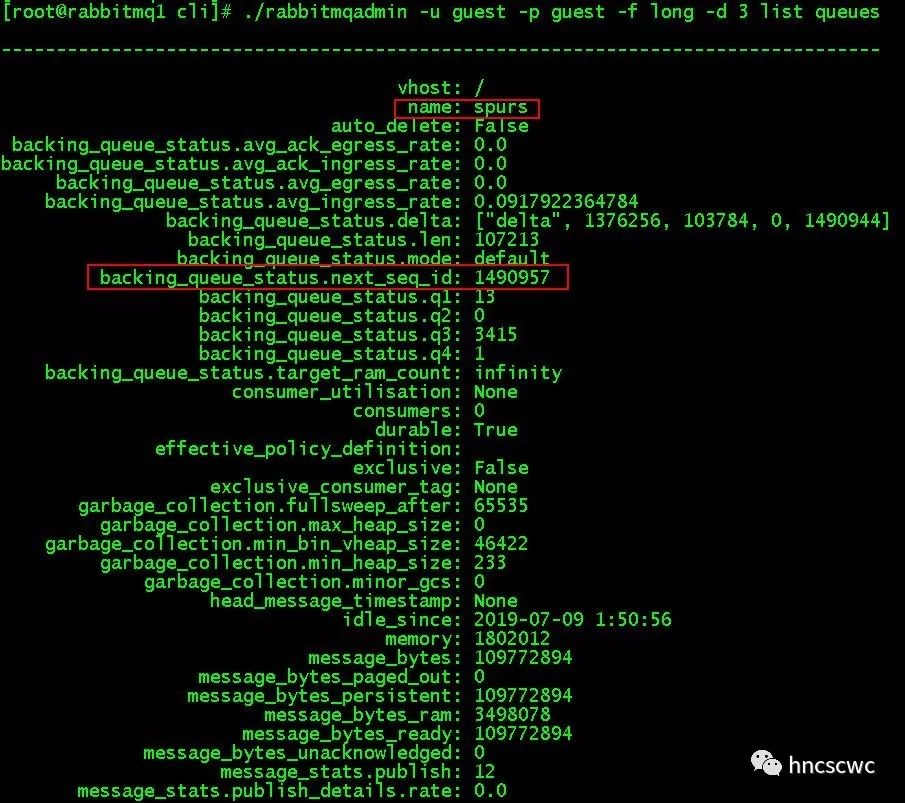 最后再补充说明一点: 前面说了,每个消息在队列中都有一个对应的序号,并且该序号随着消息一起持久化到文件中了,但字段next_seq_id本身并没有进行持久化,因此rabbitmq重启后,每个队列会重新计算该值。具体为:找下一个即将写的索引文件,乘以16384得到的值即为新的next_seq_id的值。(为什么是乘以16384,可以参考这篇文章) 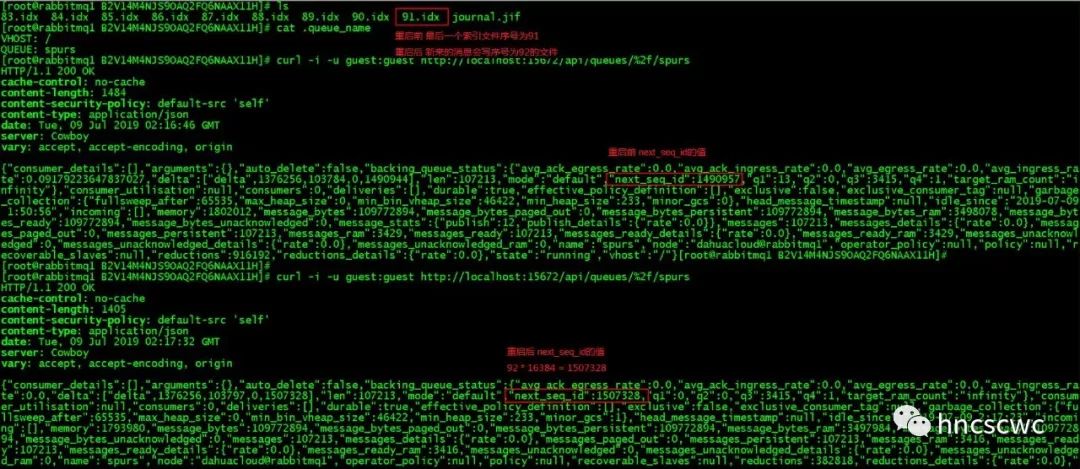 总结 统计一个时间段内进入队列的消息数,可以通过队列的内部状态字段next_seq_id来实现。 |
【本文地址】