| 2023最新详细:使用selenium携带cookie登录QQ空间,爬取指定好友空间说说照片 | 您所在的位置:网站首页 › qq空间登录设置 › 2023最新详细:使用selenium携带cookie登录QQ空间,爬取指定好友空间说说照片 |
2023最新详细:使用selenium携带cookie登录QQ空间,爬取指定好友空间说说照片
|
写在前面:最近学了爬虫,正好爬取一下指定好友的所有空间说说照片,之前使用selenium账号密码登录,模拟登录次数过多,会加验证码,甚至导致QQ冻结,所以采用cookie登录 思路首先获取cookie,使用cookie登陆之后通过空间好友栏搜索指定好友,并进入好友空间,从而爬取说说照片,注意说说分纯文字,(文字+)图片,(文字+)链接,(文字+)视频,因为首次默认加载空间说说数量限制,通过模拟屏幕滑动加载所有说说,再通过xpath定位处理,解析出图片src,进而下载持久化存储。
安装Google插件EditThisCookie
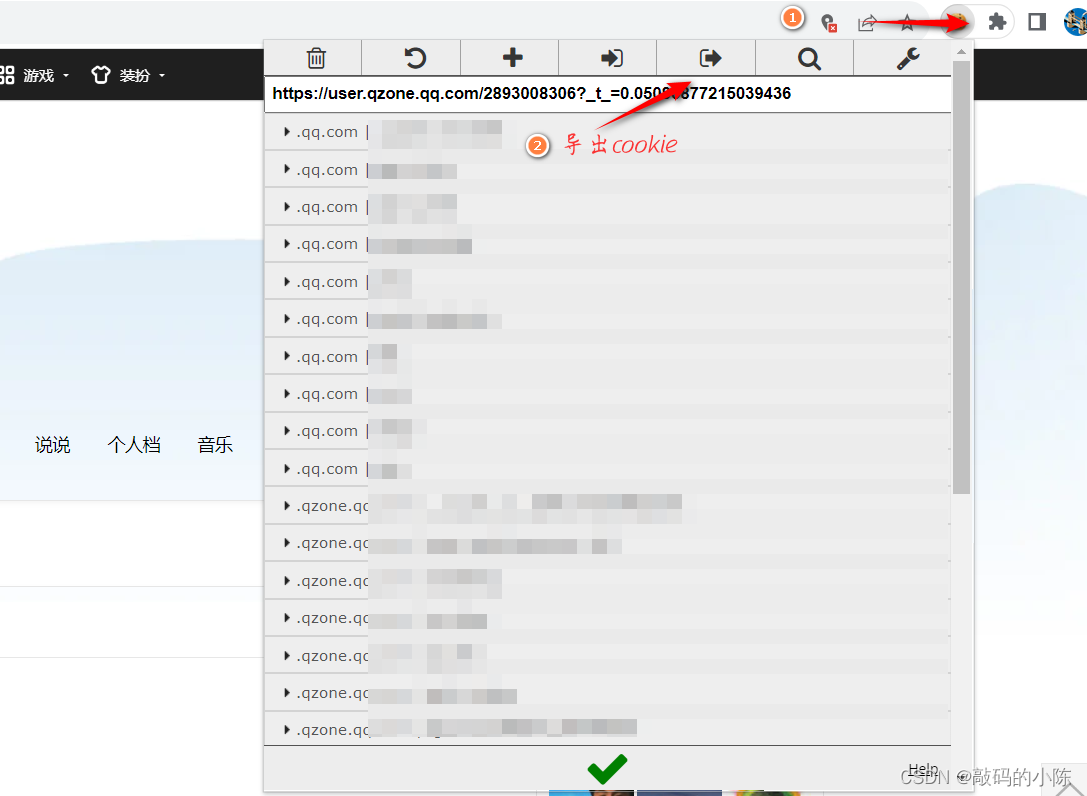
导出cookie
拿到cookie,节选如下,要修改一下cookie { "domain": ".qzone.qq.com", #均修改为 "domain": ".qq.com",不然出现域名不匹配问题 "hostOnly": false, "httpOnly": false, "name": "zzpaneluin", "path": "/", # "sameSite": "unspecified", 注释这行方式或者设置属性值为None "secure": false, "session": true, "storeId": "0", "value": "", "id": 19 }, 2.携带cookie登录 url = 'https://qzone.qq.com/' search_name = input('请输入好友姓名') # 粘贴通过EditThisCookie获取的页面cookie信息 cookies = [ ] chrome_options = Options() # 不显示页面 # chrome_options.add_argument('--headless') # chrome_options.add_argument('--disable-gpu') # 反自动检测 chrome_options.add_experimental_option('excludeSwitches', ['enable-automation']) # 创建一个Service对象,指定ChromeDriver的路径 service = Service('E:/appData/webCrawlerStu/C7.selenium/chromedriver.exe') # 通过Service对象来初始化Chrome WebDriver driver = webdriver.Chrome(service=service, options=chrome_options) driver.get(url) sleep(3) # 通过add_cookie方法添加cookie for cookie in cookies: driver.add_cookie(cookie) sleep(3) driver.refresh() # 刷新页面验证是否登录成功 进入好友空间 # 获取所有窗口句柄。句柄的顺序:先出现的先加入列表。最后出现的,最后加入列表。 wins = driver.window_handles # 切换到最新打开的窗口 driver.switch_to.window(wins[-1]) driver.maximize_window() # 进入好友空间 driver.implicitly_wait(5) # 隐示等待,为了等待充分加载好网址,全局的 driver.find_element('id', 'tab_menu_care').click() driver.find_element('id', 'aMyFriends').click() driver.find_element('id', 'friend_search_input').send_keys(search_name) driver.find_element('xpath', '//*[@id="friends-drop-down"]/div[2]/div/div/div[1]/div[1]/button').click() driver.find_element('xpath', '//*[@id="search_friend_result"]/li/a').click() wins = driver.window_handles driver.switch_to.window(wins[-1]) # 点击我知道了 driver.find_element('xpath', '//*[@id="friendship_promote_layer"]/table/tbody/tr[1]/td[2]/a').click() 滚动屏幕加载所有说说 def scroll_to_bottom(driver): # 设置初始滚动位置 scroll_position = 0 # 不断向下滑动直到见底 while True: # 向下滚动一屏的高度 driver.execute_script( f"window.scrollTo(0, {scroll_position + driver.execute_script('return window.innerHeight;')});") # 等待一段时间,让页面加载 sleep(1.5) # 可以根据实际情况调整等待时间 # 更新滚动位置 new_scroll_position = driver.execute_script("return window.pageYOffset;") if new_scroll_position == scroll_position: # 如果滚动位置没有发生变化,说明已经到达底部,退出循环 break # 更新滚动位置 scroll_position = new_scroll_position scroll_to_bottom(driver) print('屏幕滑动到底!') 说说数据解析获取图片src # 转化到iframe driver.switch_to.frame('QM_Feeds_Iframe') with open('./porfile.html', 'w', encoding='utf-8') as fp: fp.write(driver.page_source) sleep(5) # 获取说说图片链接 imgsDownloadList = [] tree = etree.HTML(driver.page_source) lis = tree.xpath('//ul[@id="host_home_feeds"]/li') for li in lis: # 去除多余空格 date = li.xpath('./div[1]/div[@class="user-info"]/div[@class="info-detail"]/span/text()')[0] post_date = re.sub(r"\s+", "", date).replace(':', '时') + '秒' a_list = li.xpath('./div[2]/div[1]/div[2]/div[1]/div[1]//a') # 防止纯文本 if not a_list: continue for ref, a in enumerate(a_list, start=1): # 因为说说视频和图片a标下img标 # 纯文字,(文字+) 视频 , (文字+) 图片 img_src_list = a.xpath('.//img/@src') if img_src_list: img_src = img_src_list[0] else: # 说说类型为分享链接 ,处理找不到元素的情况 continue img_name = f"{post_date}_{ref}.jpg" img_profile = { 'img_name': img_name, 'img_src': img_src } imgsDownloadList.append(img_profile) 持久化存储 # 持久化存储包含字典对象的列表 my_list = [{"name": "John", "age": 30}, {"name": "Alice", "age": 25}] with open("./data.json", "w") as fp: json.dump(imgsDownloadList, fp) # 持久化存储 # UA伪装 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36' } location = './QzoneOf' + search_name if not os.path.exists(location): os.mkdir(location) for image in imgsDownloadList: source = requests.get(url=image['img_src'], headers=headers).content filename = location + '/' + image['img_name'] with open(filename, 'wb') as fp: fp.write(source) sleep(2) driver.quit()ps:图片名称以时间+序列号命名,最后还可以使用线程池处理下载图片,如有问题希望指正... |
【本文地址】
公司简介
联系我们