| 使用PyTorch构建神经网络(详细步骤讲解+注释版) 01 | 您所在的位置:网站首页 › pytorch网课推荐 › 使用PyTorch构建神经网络(详细步骤讲解+注释版) 01 |
使用PyTorch构建神经网络(详细步骤讲解+注释版) 01
|
文章目录
1 数据准备2 数据预览3 简单神经网络创建3.1 设计网络结构3.2 损失函数相关设置3.3 向网络传递信息3.4 定义训练函数train
4 函数汇总
1 数据准备
神经网络中,一个非常经典的案例就是手写数据的识别,本文我们以手写数据识别为例进行讲解。用到的数据是MNIST数据集。MNIST数据集是一个常用的用于计算机视觉的测试数据集,包含了70,000张手写数字的图片,用于训练和测试模型识别手写数字的能力。MNIST数据集中的图片大小都是28x28像素,图片中的数字是黑白的,每张图片都有对应的标签,表示图片中的数字是什么。MNIST数据集是计算机视觉领域的“Hello World”级别的数据集,被广泛用于计算机视觉模型的训练和测试。 可以在数据集的原始来源进行下载,但因为是外网链接,我稍后也会将整理成.csv的数据放到博客的资源中,供大家使用,如果找不到也可以直接文末留言,我私信发你。 2 数据预览我的数据集格式为:每行785个数值,第一个数值为图片的标签,也就是图片写的数字,后784个数值为图片的28*28像素值。如果大家使用不同的数据格式,根据实际情况修改代码即可。 row = 你要展示的数据行数 # data就是传入的mnist数据集 data = df.iloc[row] # 如果你的label不是一行第一个,此处要修改 label = data[0] # 把数据按28行28列重新排列 img = data[1:].values.reshape(28,28) plt.title("label = " + str(label)) plt.imshow(img, interpolation='none', cmap='Blues') plt.show()这样就可以对图片进行阅览了
在定义神经网络层时,我们使用PyTorch 中的 torch.nn 包,这个包提供了很多与实现神经网络中的具体功能相关的类,还有激活函数部分的线性激活函数、非线性激活函数相关的方法。在之后的代码中,我们会逐渐认识这个包的作用。 3.1 设计网络结构 from torch import nn class Classifier(nn.Module): def __init__(self): # 这里的代码是接着上面__init__函数写的,为了页面简洁,我把前面的内容省略了 self.model = nn.Sequential( nn.Linear(784, 200), nn.Sigmoid(), nn.Linear(200, 10), nn.Sigmoid()这里nn.linear()是用来设置网络中的全连接层的。以下补充函数相关内容,如不需要可以先略过。 该函数的默认输入参数情况为: nn.Linear(in_features, # 输入的神经元个数 out_features, # 输出神经元个数 bias=True # 是否包含偏置 )而这个函数的功能其实就是对输入 X n × i X_{n×i} Xn×i执行了一个线性变换,即: Y n × o = W i × o X n × i + b o Y_{n×o}=W_{i×o}X_{n×i}+b_{o} Yn×o=Wi×oXn×i+bo 其中 Y Y Y是n组o维的数出,n是数据量,o是数据的特征数; W W W是数据权重; b b b是偏置,也就是bias=True相对应的地方。 3.2 损失函数相关设置损失函数用来告诉模型什么是好的模型,并帮助模型在优化器的帮助下不断更新网格权重,从而优化模型。此处损失函数我们使用最常见的MSE函数(Mean squared error,均方误差);优化器使用最常见的梯度下降,学习速录设为0.01。 import torch class Classifier(nn.Module): def __init__(self): # 创建损失函数 self.loss_function = nn.MSELoss() # 创建优化器 self.optimiser = torch.optim.SGD(self.parameters(), lr=0.01) 3.3 向网络传递信息我们需要建立一个forward方法,向网络传递信息。尽管在定义类时,可以直接将相关信息传入,但是单独定义一个传入方法的函数,会使代码的逻辑性变得更强。这个函数也非常的简单。 class Classifier(nn.Module): # 创建forward函数,用于将信息传递给网络 def forward(self, inputs): return self.model(inputs) 3.4 定义训练函数train训练函数应该可以根据模型的输出与期望输出,使用优化器来不断优化模型。而模型的输出需要使用输入来生成,因此,训练函数的输入数据应该包含模型输入值inputs与预期输出值targets两部分。这里使用到了们定义过的forward、loss_function、optimiser方法。PyTorch将这一过程变得非常简单。 class Classifier(nn.Module): # 创建网格训练函数 def train(self, inputs, targets): outputs = self.forward(inputs) loss = self.loss_function(outputs,targets) self.optimiser.zero_grad() loss.backward() self.optimiser.step()在更新网络链接的权重时,这里使用了self.optimiser.zero_grad()首先将梯度全部归零,因为loss.backward计算出的权重会累积;使用loss.backward()计算网络中的梯度(在Pytorch入门篇有讲);使用optimiser.step()来更新权重。 4 函数汇总截至目前,Classifier类的所有函数如下: import torch import torch.nn as nn class Classifier(nn.Module): # 初始化PyTorch父类 def __init__(self): super().__init__() # 定义网格结构 self.model = nn.Sequential( nn.Linear(784, 200), nn.Sigmoid(), nn.Linear(200, 10), nn.Sigmoid() ) # 创建损失函数 self.loss_function = nn.MSELoss() # 创建优化器 self.optimiser = torch.optim.SGD(self.parameters(), lr=0.01) # 创建forward函数,用于将信息传递给网络 def forward(self, inputs): return self.model(inputs) # 创建网格训练函数 def train(self, inputs, targets): outputs = self.forward(inputs) loss = self.loss_function(outputs,targets) # 权重更新 self.optimiser.zero_grad() loss.backward() self.optimiser.step()目前实现的功能为: |


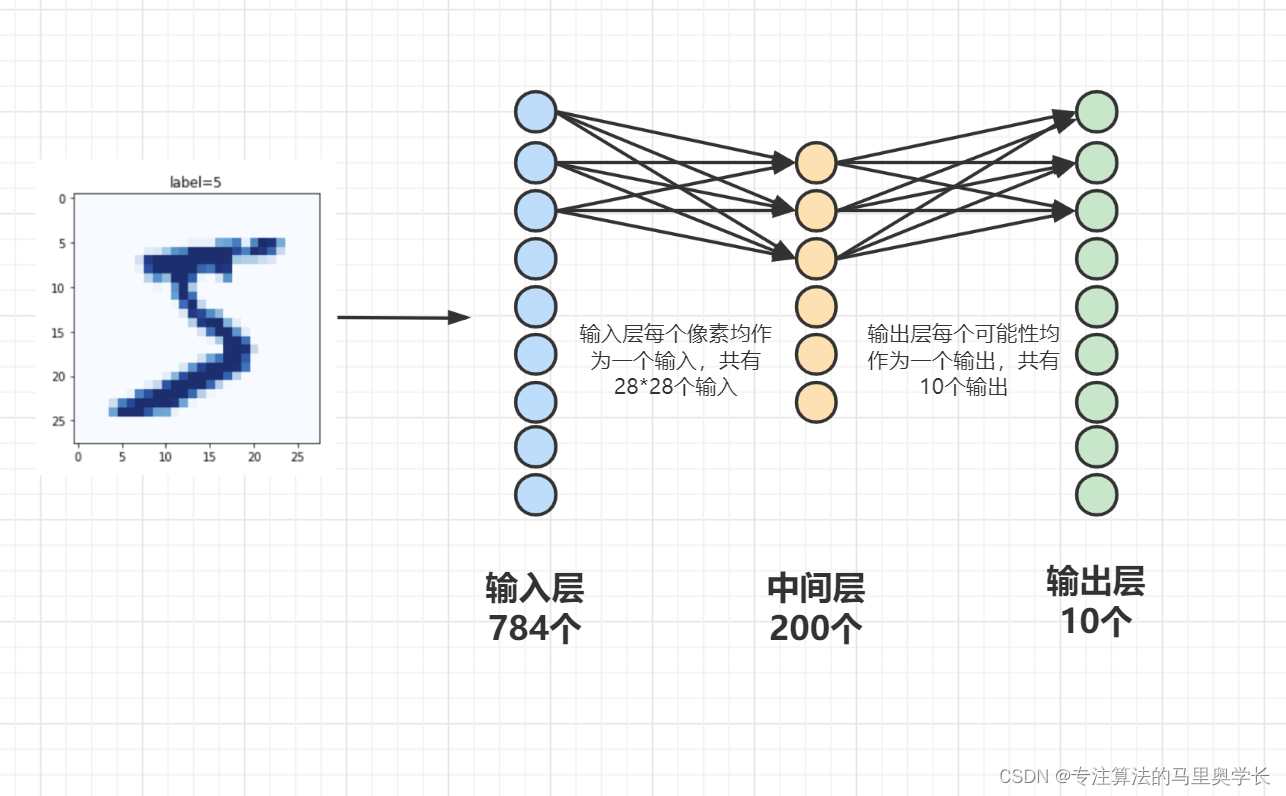 这里默认大家都有神经网络的基础知识,如希望补充相关知识,非常推荐大家阅读《Deep Learning》(也叫花书)、《Python神经网络编程》与《PyTorch生成对抗网络编程》,这三本书也是博主深度学习的入门书之一 我们使用单层(指只有一个中间层)神经网络。输入输出根据数据特性确定,中间层使用本数据较为常用的200个节点,激活函数使用Sigmoid。 首先我们定义一个分类器类 首先我们做一些基础的配置。包括设置__init__和定义神经网络层。其中__init__是初始化函数,在创建对象的时,就"自动调用"。每创建一次新的对象,就会重新自动调用一次;此处如有困难,建议补充面向对象编程的相关知识。
这里默认大家都有神经网络的基础知识,如希望补充相关知识,非常推荐大家阅读《Deep Learning》(也叫花书)、《Python神经网络编程》与《PyTorch生成对抗网络编程》,这三本书也是博主深度学习的入门书之一 我们使用单层(指只有一个中间层)神经网络。输入输出根据数据特性确定,中间层使用本数据较为常用的200个节点,激活函数使用Sigmoid。 首先我们定义一个分类器类 首先我们做一些基础的配置。包括设置__init__和定义神经网络层。其中__init__是初始化函数,在创建对象的时,就"自动调用"。每创建一次新的对象,就会重新自动调用一次;此处如有困难,建议补充面向对象编程的相关知识。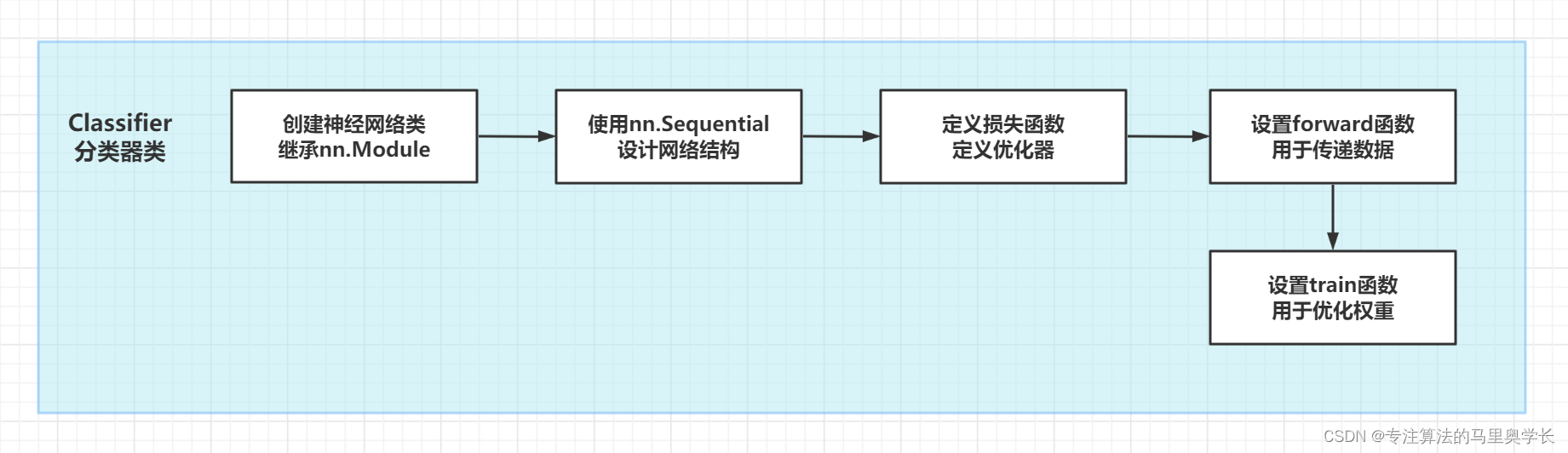 下一篇将会讲解手写数据的处理与模型训练全过程 使用PyTorch构建神经网络(详细步骤讲解+注释版) 02-数据读取与训练
下一篇将会讲解手写数据的处理与模型训练全过程 使用PyTorch构建神经网络(详细步骤讲解+注释版) 02-数据读取与训练【本文地址】