| 探索性空间数据分析的相关信息解释 | 您所在的位置:网站首页 › python空间权重矩阵 › 探索性空间数据分析的相关信息解释 |
探索性空间数据分析的相关信息解释
|
1.引言
这篇帖子内容有关arcmap地图绘制和局部空间自相关等等,希望可以帮助到你,先发布,后续会完善
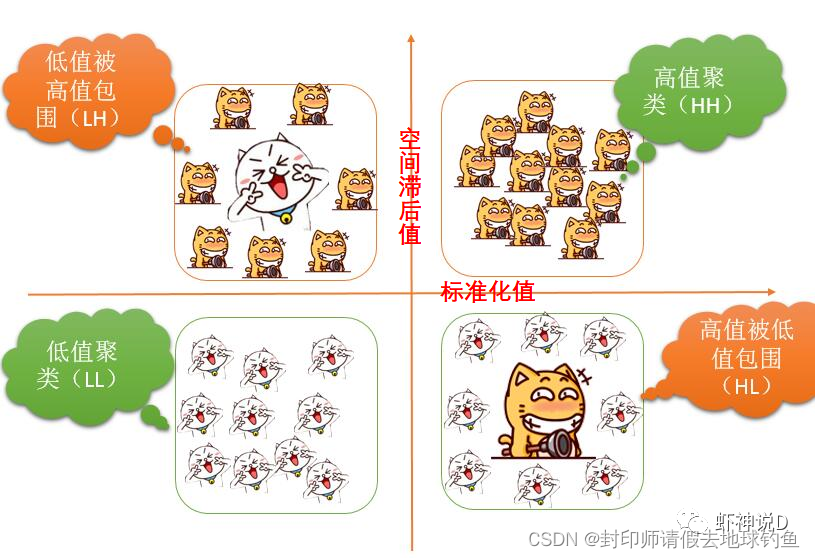
2.新版白话空间统计(46)局部莫兰指数计算原理与操作篇(GeoDa版)(转自虾神说D公众号,极力推荐大家关注他) 2.1前言 我们在新版白话空间统计第44节,展示过这样一张图:
用四个象限来表示LISA的结果划分,今天我们具体来讲讲如何计算LISA也就是详细讲讲如何计算这个坐标轴上的空间滞后值和标准化(观测)值。 (PS:LISA是Local Indicators of Spatial Association的简写,是anselin在1995年提出的一种方法论,里面用到的模型,就是local moran's i) 首先我们先来看这个笛卡尔坐标系的X轴和Y轴。X轴是标准化之后的观测值,标准化的方法有很多,而这里用的是z-score标准化(zero-mena normalization,此方法最为常用的标准化方法)。 用官方的说法:多指标评价体系中,由于各评价指标的性质不同,通常具有不同的量纲和数量级。当各指标间的水平相差很大时,如果直接用原始指标值进行分析,就会突出数值较高的指标在综合分析中的作用,相对削弱数值水平较低指标的作用。因此,为了保证结果的可靠性,需要对原始指标数据进行标准化处理。
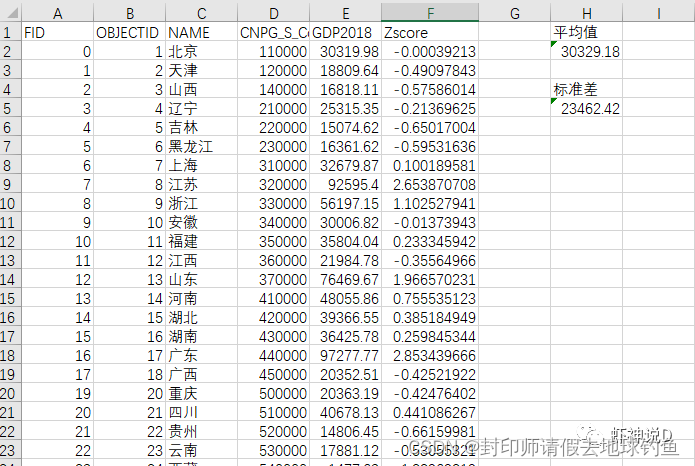
数据的标准化(normalization)是将数据按比例缩放,使之落入一个小的特定区间。在某些比较和评价的指标处理中经常会用到,去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权。 Z-Score标准化的方法非常简单,公式如下:Z-Score标准化 = (要标准化的值(观测值) - 平均值) / 标准差 z-score标准化方法适用于属性A的最大值和最小值未知的情况,或有超出取值范围的离群数据的情况。 而Y轴表示的是空间滞后值(何为空间滞后值,我们在下篇中会详细说明),即该要素的相邻要素的所有ZScore标准化观测值的空间加权平均。 为了验证我们的理解对不对,可以直接用Excel来计算,来与GeoDa计算的结果进行对比,对比如下: 用Excel,对我们要计算的字段,进行ZScore标准化,可以得到如下结果:
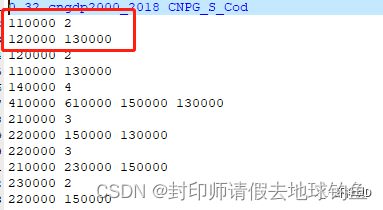
然后利用Queen's Case的空间关系矩阵,求空间滞后值(因为太多了,所以我示例性的求其中一个就行): 比如求北京的空间滞后值,空间权重矩阵如下:
北京有两个邻居,分别是河北和天津,计算北京的空间滞后值,算法如下:北京的空间滞后值 = 累加 (邻居的观测值的ZScroe标准化值 * 权重)/ 邻居的数量 其实也就是,也就是求了空间关系加权之后的平均值 我们的空间权重矩阵用的是queen's case,那么所有的邻居权重都是一样的,直接计算平均值就可以了: 北京的空间滞后值 = (-0.490978428[天津的zscore] * 1[天津对北京的空间关系加权] + 0.242135744[河北的zscroe] * 1[河北对北京的空间关系加权])/ 2 = -0.124421342 依此把所有的数据都算一遍,就可以得到所有要素的Zscroe和空间滞后值,然后,只要有两个值,就构成了X轴和Y轴,就可以绘制出散点图来了。 注意,大家在测试的时候,如果计算的结果和我不同,切记看这里:
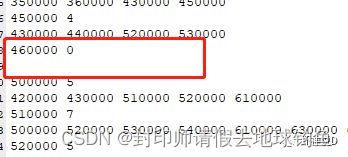
如果用默认的空间权重矩阵,海南没有邻居,是不会参与计算的,所以你在手动计算平均值和标准差的时候,需要把海南排除掉。(有同学问,如果我要加入海南呢?答案是需要自定义修改空间权重矩阵,参考以前的文章)新版白话空间统计(18)空间关系概念化之Geoda的面邻接构建及自定义
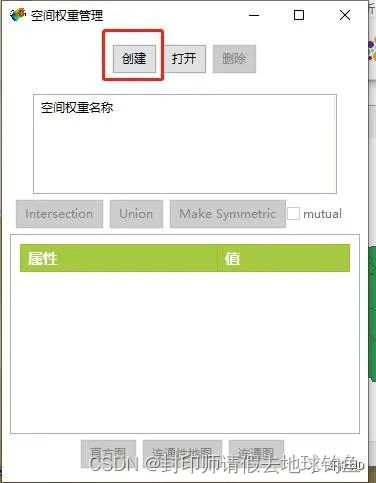
下面,我们用GeoDa来做局部莫兰指数,并且把值添加到属性里面,为什么要用GeoDa?因为ArcGIS不支持把计算保存计算出来的ZScore标准化值和空间滞后值,要看这两个值,只能用GeoDa(R语言和Python也行,以后有空说)。 2.2GeoDa进行局部莫兰指数分析,并且获得数值的完整操作流程:STEP1:打开GeoDa软件之后,在连接数据源界面点击选择文件后面的打开按钮,选择我们需要打开的数据,这里我们需要打开shape file,所以选择第一项即可。 STEP2: 找到我们需要打开的Shapefile STEP 3:在计算之前,需要先定义空间权重矩阵,所以在工具栏上选择空间权重管理:
STEP 4: 点击创建
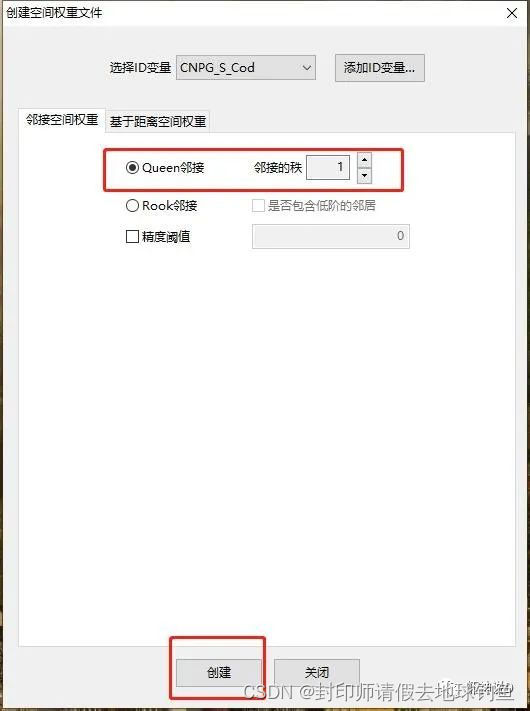
STEP5: 选择ID(必须是唯一值,而且是整数或者字符串),在GeoDa的新版本里面,支持用字符串类型定义,我们这里选择CNPG_S_Cod,这个字段是各省的行政区划编码。 STEP6: 选择Queen连接(共点共边即相邻),秩选1(默认)就行,因为我们不需要进行二阶邻域计算。
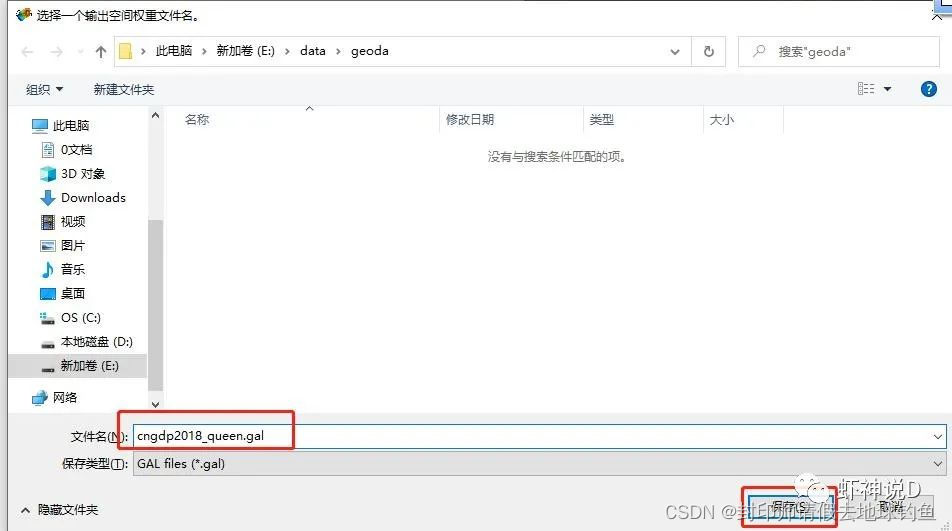
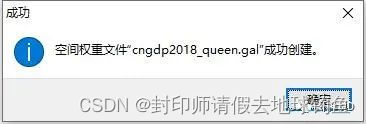
STEP7: 点击创建的时候,会让你保存空间权重矩阵文件。
STEP8: 保存之后,会弹出一个警告(这是因为海南、台湾两地出现无相邻的要素),不用管,直接点击确定,然后会提示创建成功的对话框。
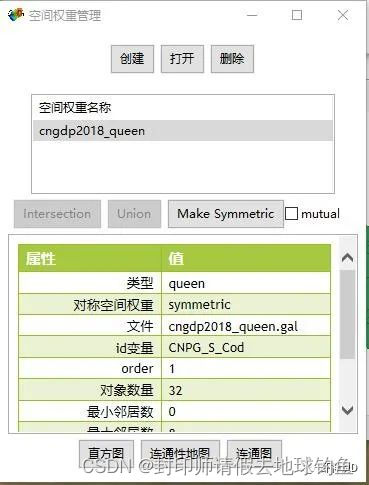
STEP9: 可以点击直方图或者连通图看目前的空间权重矩阵,也可以直接点击右上角的叉,关闭空间权重管理窗口。
STEP10: 接下去做局部莫兰指数,在下拉菜单找到空间分析——单变量局部Moran's I:
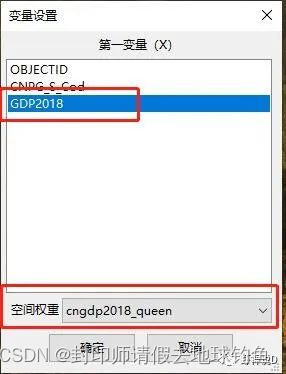
STEP11: 选择要进行莫兰指数分析的字段“GDP2018”,下面选择我们的空间权重,如果只有一个,就是默认的,如果定义了多个,可以切换选择。
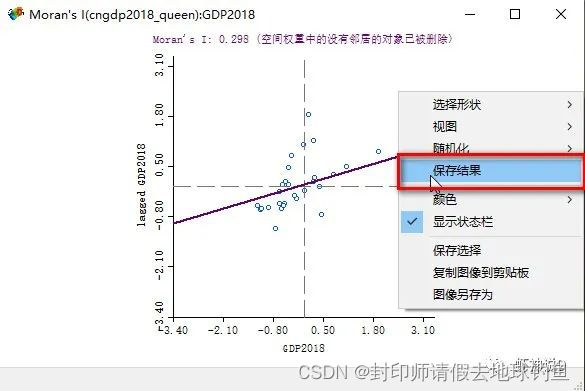
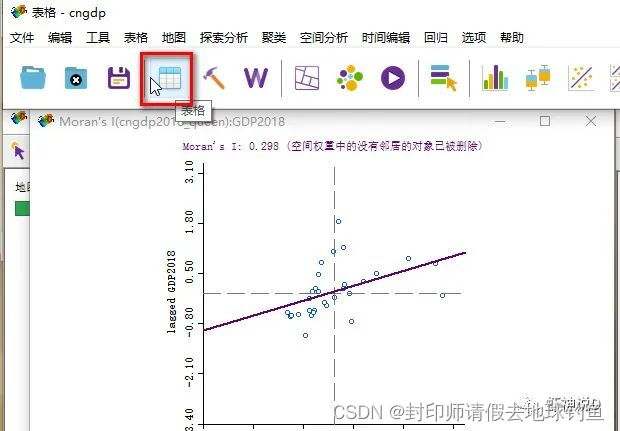
STEP12:点击确定的时候,会问你结果用什么方式显示,我们可以把下面两个都选上,即聚类地图和Moran散点图,选择之后点击确定。 STEP13: 此时可以看见莫兰散点图与LISA聚类地图了:
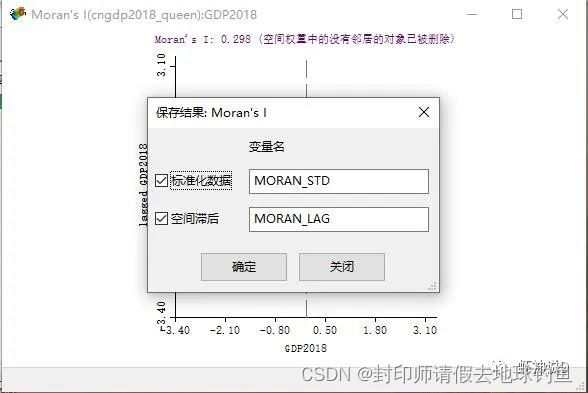
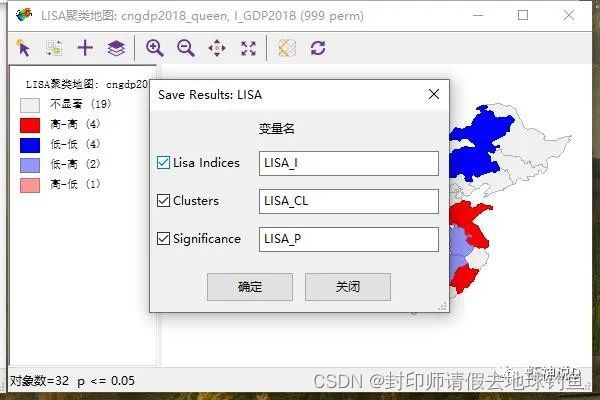
STEP14: 下面我们把值保存到数据里面去,首先在散点图上面,点击鼠标右键,弹出功能菜单,并且选择保存结果:
STEP15: 在保存结果窗体中,把标准化数据和空间滞后两个复选框都选上,点击确定。
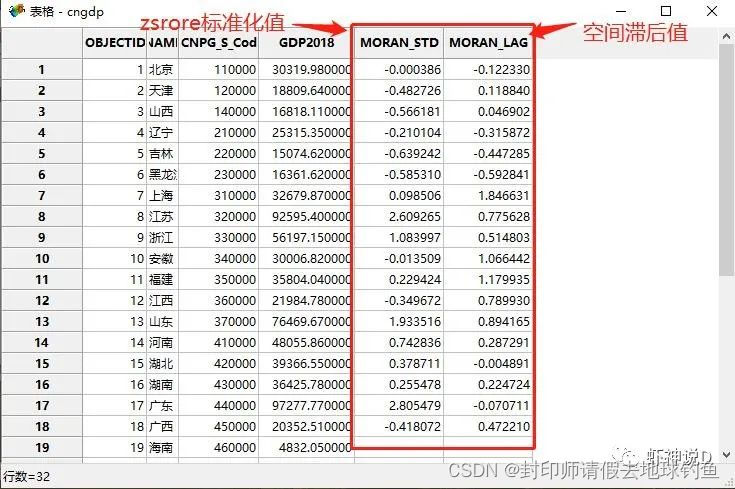
STEP16: 然后在工具栏上点击表格工具图标,打开数据属性表。
STEP17: 这时候,就可以看见计算出来的标准化数据和空间滞后值了。
STEP18:我们可以来对比一下,GeoDa计算出来的,和我们用Excel计算出来的结果,可以看见基本上是一致的(细节数值的不同,是因为计算的时候,Excel和GeoDa二者之间,保留的小数位不一致导致的)。
STEP19:同样,我们可以把局部莫兰指数也保存下来。
STEP20: 全部选择之后,点击确定
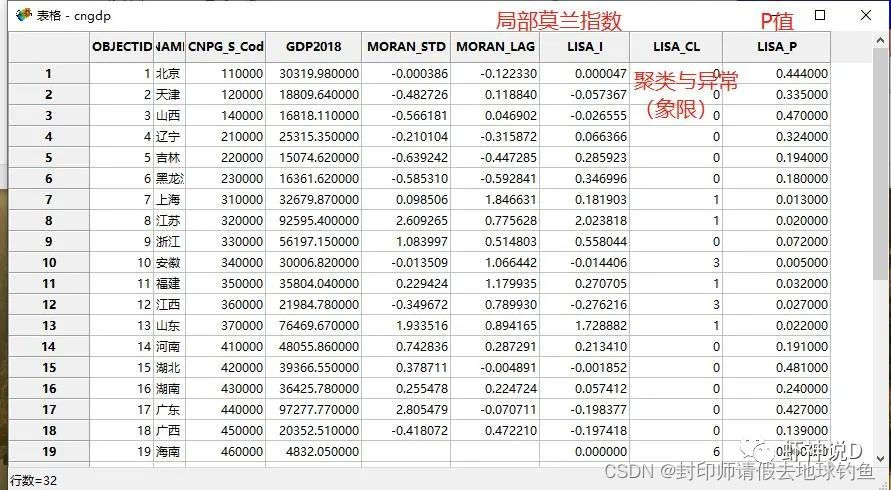
STEP21: 打开属性表,就可以看见多了三个字段,分别是具备莫兰指数、聚类与异常值标识以及P值。
注意,这里的聚类与异常值里面的数值,代表的是象限,另外因为计算机是从0开始计数的,所以结果就是0123——实际上应该是需要加1:分别表示第一二三四象限。
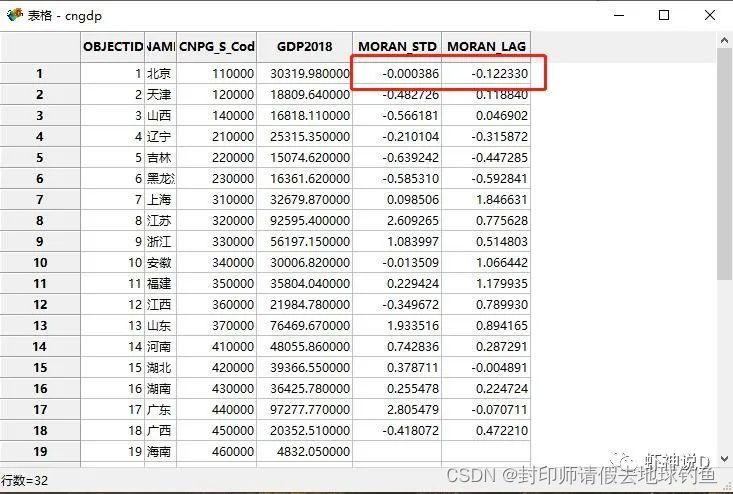
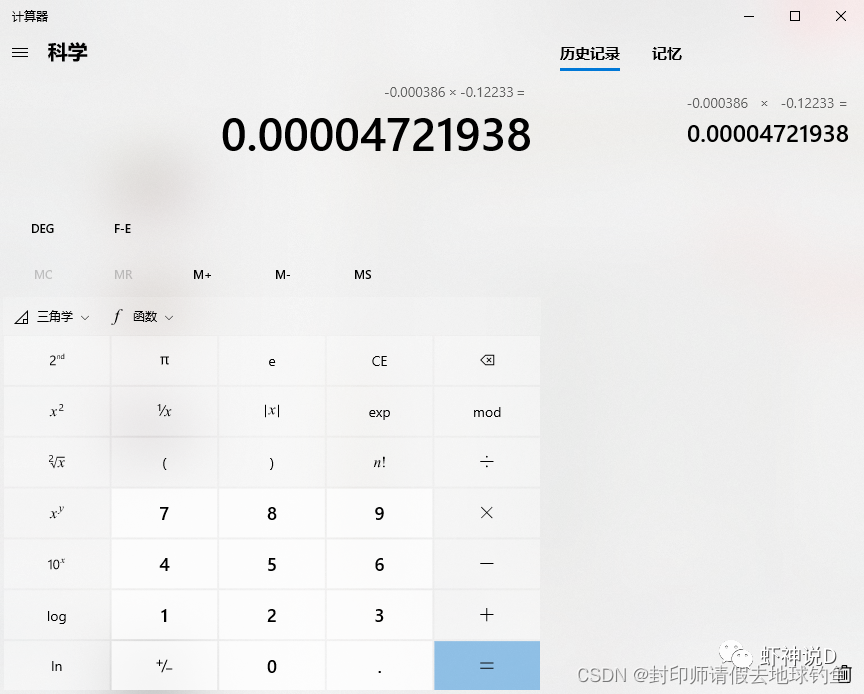
最后,局部莫兰指数的值是怎么算出来的呢? 非常简单,直接用标准化值乘以空间滞后值即可,比如: 北京的局部莫兰指数= -0.000386 * -0.12233 =
2. 3.核密度估计曲线分析(1)“峰”越高,表示此处数据越“密集”。 (2)kernel曲线向右移动:XX水平不断提高。 (3)分布形态:右尾拉长,表示差异增加。 第三,右拖尾存在逐年拉长现象,分布延展性在一定程度存在拓宽趋势,意味着全国范围内全要素能源效率的空间差距在逐步扩大。 (4)多峰:多峰形态明显,说明多极分化现象。双峰向单峰过渡,说明两极分化现象在减弱。 (5)扁而宽的核密度曲线(峰值降低、宽度加大):各省份差异程度变大。 (6)若核密度曲线图中, 波形向左移动 (呈右偏态分布) 、波峰垂直高度上升、水平宽度减小、波峰数量减小, 则表明其核密度趋于向数值减小的方向移动, 即该地区农业碳排放地区差距呈缩小态势, 存在动态收敛性特征。 4.地理探测器全文详细来源:地理探测器(GeoDetector)原理及其实现 - 知乎 (zhihu.com) 4.1、地理探测器原理与功能 4.1.1 用途与目的地理学第二定律的核心思想是地理现象的空间(分层)异质性,其普遍存在于各种地理现象中。 空间分层异质性(spatial stratified heterogeneity),层内方差小于层间方差的地理现象。即同一地理现象在同一子区域内表现出相似性,但在不同子区域间的分布呈现差异性,例如土地类型、气候分区等。此处,层(strat)是统计学上的概念,对应地理学可理解为子区域。 地理探测器是探测空间分异性以及揭示其背后驱动力的空间分析方法,被广泛用于进行驱动力分析和因子分析。其核心思想是基于这样的假设:如果某个自变量对某个因变量有重要影响,那么自变量和因变量的空间分布应该具有相似性。地理分异可以利用地理探测器进行统计分析,其有两大优势:一是地理探测器既可以探测数值型数据,也可以探测定性数据;二是可以探测两因子交互作用于因变量。地理探测器通过分别计算和比较各单因子q值及两因子叠加后的q值,可以判断两因子是否存在交互作用,以及交互用用的强弱、方向、线性还是非线性等。两因子叠加既包括相乘关系,也包括其他关系,只要有关系,就能检验出来。 ref : 王劲峰,徐成东.地理探测器:原理与展望[J].地理学报,2017,72(01):116-134. 4.1.2 功能原理地理探测器用于分析空间分层异质性,主要包括4个探测器(因子探测器、交互作用探测器、风险区探测器、生态探测器),分析结果可分别回答以下问题: (1)是否存在空间异质性?什么因素造成了这种分层异质性? (2)变量Y是否存在显著的区际差别? (3)因素X之间的相对重要性如何? (4)因素X对于因素Y是独立起作用还是具有广义的交互作用? 分异及因子探测
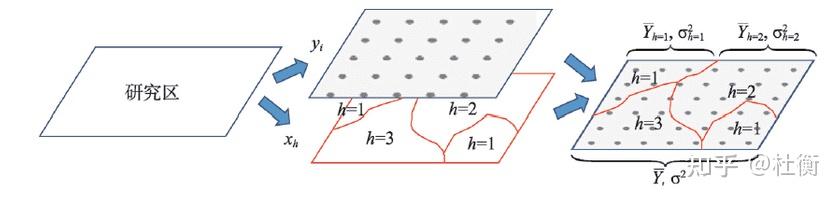
因子探测旨在探测Y的空间分异性以及探测某因子X多大程度上解释了属性Y的空间分异,用q值度量(Wang et al.,2010b),表达式为:
式中:h = 1, …, L为变量Y或因子X的分层,即分类或分区;Nh和N分别为层h和全区的单元数;σ2h和 σ2分别是层h和全区的Y值的方差。SSW和SST分别为层内方差之和(Within Sum of Squares)和全区总方差(Total Sum of Squares)。 q的值域为[0, 1],值越大说明Y的空间分异性越明显;如果分层是由自变量X生成的,则q值越大表示自变量X对属性Y的解释力越强,反之则越弱。极端情况下,q值为1表明因子X完全控制了Y的空间分布,q值为0则表明因子X与Y没有任何关系,q值表示X解释了100xq%的Y。 q值的一个简单变换满足非中心F分布:
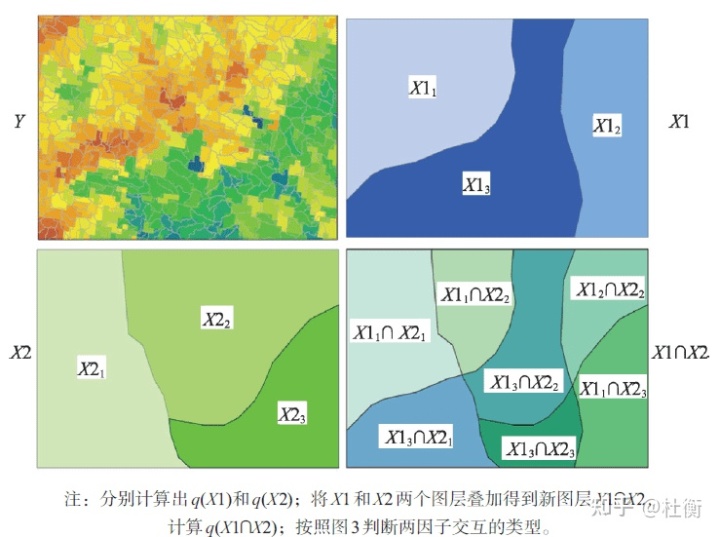
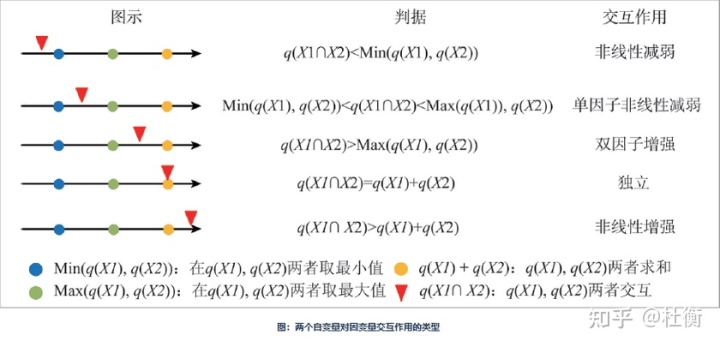
式中:λ为非中心参数;Yh为层h的均值。 交互作用探测用于识别不同风险因子Xs之间的交互作用,即评估因子X1和X2共同作用时是否会增加或减弱对因变量Y的解释力,或这些因子对Y的影响是相互独立的。评估的方法是首先分别计算两种因子X1和X2对Y的q值:q(X1)和q(X2),并且计算它们交互(叠加变量X1和X2两个图层相切所形成的新的多边形分布)时的q值: q(X1∩X2),比较 q(X1)、 q(X2)与 q(X1∩X2)的大小。两个因子之间的关系可分为以下几类:
用于判断两个子区域间的属性均值是否有显著的差别,用t统计量来检验:
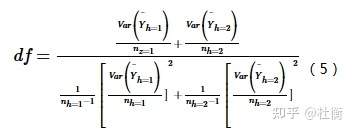
式中: Yh表示子区域h内的属性均值,如发病率或流行率;nh为子区域h内样本数量,Var表示方差。统计量t近似地服从Student’s t分布,其中自由度的计算方法为:
零假设H0: Yh=1=Yh=2,如果在置信水平α下拒绝H0,则认为两个子区域间的属性均值存在着明显的差异。 生态探测用于比较两因子X1和X2对属性Y的空间分布的影响是否有显著的差异,以F统计量来衡量。
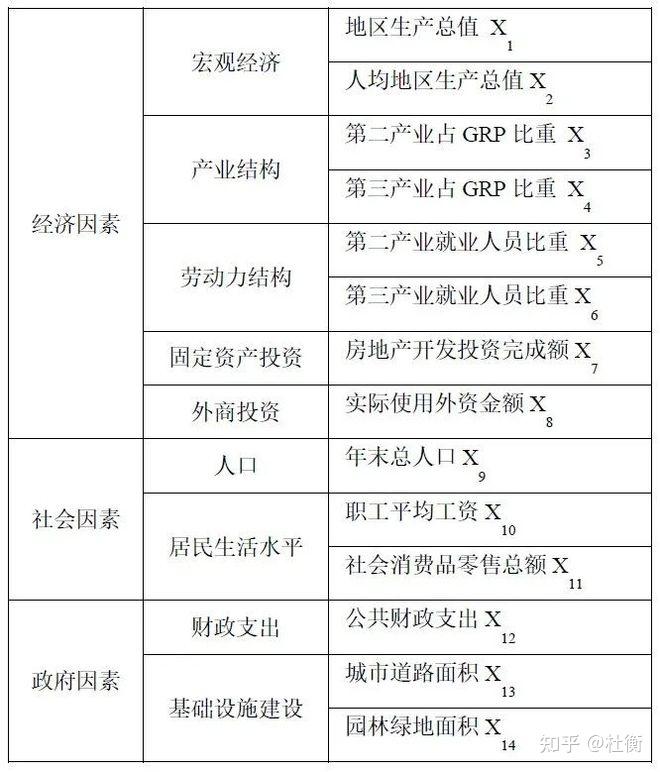
式中:NX1及NX2分别表示两个因子X1和X2的样本量;SSWX1和SSWX2分别表示由X1和X2形成的分层的层内方差之和;L1和L2分别表示变量X1和X2分层数目。其中零假设H0:SSWX1=SSWX2。如果在α的显著性水平上拒绝H0,这表明两因子X1和X2对属性Y的空间分布的影响存在着显著的差异。 4.1.3 功能入口工具箱 >> 空间统计分析 >> 分析模式 >> 地理探测器。 4.1.4 主要参数 源数据 :设置待分析的数据集,支持点、线、面及属性表四类数据集。因变量字段(Y):是被测定或被记录的变量,会随另一个(或另几个)变量的变动而发生变动,为数值量,如各村庄神经管畸形出生缺陷(NTDs)发生率。自变量字段(X):是引起因变量发生变化的因素或条件,是对因变量的解释变量,支持设置多个解释变量,如土壤类型、高程、水文流域等。注意这里的自变量应为类型量,如果为数值量,则需对其进行分组或分层,使组内方差最小,组间方差最大。分组可以基于专家知识,也可以使用k-means,或者排序后等分。应保证各组或层分类变量中至少有因变量的两个样本单元,从而可以计算该层的均值或方差。结果数据 :指定的保存分析结果的数据源。四种探测器分析结果将分别生成新的属性表数据集存放至该数据源中。 4.1.5 结果说明所有探测器结果将生成新的属性表数据集存储至数据源中,同时在右侧地理探测器面板中输出分析结果,下面将对各探测器结果进行分析: 因子探测器 :探测变量Y的空间分层异质性,以及探测某因子X多大程度上解释了变量Y的空间分异,用q值度量。如果分层是由自变量X生成的,则q值越大表示X和Y的空间分布越一致,自变量X对属性Y的解释力越强,反之则越弱。FactorDetector_result 属性表数据集为因子探测结果。交互探测器 :用于识别不同解释变量之间的交互作用,评估两因子共同作用时是否会增加或减弱对因变量的解释力,或这些因子对其影响是否相互独立的。InteractionDetector_result 属性表数据集为交互探测结果,解释变量对因变量交互作用的类型包括: Weaken,nonlinear:非线性减弱;Weaken,uni-:单因子非线性减弱;Enhance, bi-:双因子增强;Independent:独立;Enhance,nonlinear:非线性增强。风险探测器 :用于判断不同区域的属性均值是否具有显著性。RiskDetector_result 属性表数据集为风险区探测结果。生态探测器 :用于比较不同影响因子对属性值的空间分布的影响是否有显著的差异。EcologicalDetector_result 属性表数据集为生态探测结果。 4.1.6 适用条件 擅长自变量X为类型量 (如土地利用图),因变量Y为数值量(碳排放)的分析;当因变量Y和自变量X均为数值量,对X离散化转换为类型量后,运用地理探测器建立的 Y 和X 之间的关系将比经典回归更加可靠,尤其当样本量<30 时。对变量无线性假设,属于方差分析 (ANOVA)范畴,物理含义明确的,其大小反映了X (分层或分类) 对Y解释的百分比100×q%。地理探测器探测两变量真正的交互作用,而不限于计量经济学预先指定的乘性交互。地理探测器原理保证了其对多自变量共线性免疫。在分层中,要求每层至少有2个样本单元。样本越多,估计方差越小。 4.1.7 应用领域包括:土地利用、公共健康、区域经济、区域规划、旅游、考古、地质、气象、植物、生态、环境、污染、遥感和计算机网络等,地理探测器作为驱动力和因子分析的有力工具已经在以上案例中得到充分验证。 4.1.8 数据要求与预处理输入数据包括因变量Y和自变量数据X。自变量应为类型量;如果自变量为数值量,则需要进行离散化处理。离散可以基于专家知识,也可以直接等分或使用分类算法如K-means等。若数据为GIS数据,需要先将其转化为下图所示的Excel数据。小编以现有数据2017年城市蔓延度为因变量,选取自变量指标如下表,并将这14个指标进行自然断点法划分为5类。
可参照方法提出者网站上的解释和分析:欢迎访问地理探测器网站 (geodetector.cn) 4.2.1 实现方法一:Geodetector 软件下载:http://www.geodetector.cn/ 该软件是基于Excel表格运行的,Geodetector软件就相当于是Excel表格文件中的一个宏。 需要注意,在进行地理探测器操作时,我们的自变量(上图中最后两列)必须是类别数据(比如土壤类型数据、土地利用类型数据),不能是连续数据(比如人口数据、GDP数据);如果大家的自变量中有连续数据的话,一定要先转换成类别数据,再进行地理探测器分析。转换的方式有很多,比如假设你的连续数据是栅格格式的,那就可以用ArcGIS中的重分类工具,对原有的连续数据栅格进行转换。
from: R语言实现地理探测器的流程及代码 谷粒故里:R语言实现地理探测器的流程及代码3 赞同 · 0 评论文章正在上传…重新上传取消 R语言geodetector包涵盖五个函数:factor_detector,interaction_detector,risk_detector,ecological_detector和geodetector。前四个功能实现因子检测器,交互检测器,风险检测器和生态检测器的计算,可以使用表数据计算,例如csv格式。最后一个函数geodetector是一个辅助函数,可用于实现shapefile格式映射数据的计算。 数据要求:需要保证输入的自变量数据已经全部为类别数据。 关于geodetector包官网有详细的介绍和教程,地址如下:https://cran.r-project.org/web/packages/geodetector/vignettes/geodetector.html#factor-detector 实现过程如下: # (1)数据预处理X 处理为离散型数据(对于栅格数据,可用栅格重分类;对于矢量数据(渔网),在mapGIS中建立gdb文件,将数据导入文件地理数据库,属性-符号化-将字段分级,或矢量数据分级显示之后,convert symbology to representation) Y 处理为点数据(渔网) # (2) 加载geodetector包及数据导入(操作时将”文件夹名称“替换成需处理的文件即可)> install.packages("geodetector") *加载包* > library(geodetector) *引用包* > install.packages("readr") > library(readr) > read_csv(“文件夹名称.csv”) *读自己命名的数据 (注意,数据要放在当前工作的文件夹中)* > 文件夹名称=read_csv("文件夹名称.csv") *数据赋值* > 文件夹名称 *指定文件* ## 2.2.1 因子探测器> factor_detector("Y", "X", as.data.frame(文件夹名称)) *其中as函数为转换为数据框* ## 2.2.2 交互探测器> interaction_detector (17,c(2,3,4,5,6,7,8,9,10,11),as.data.frame(database)) *其中当”X"为多个因子的时候,可以用c(2,3,4,5,6,7,8,9,10,11) 表示,数字代表列号。* ## 2.2.3 风险探测> risk_detector(17,c(2,3,4,5,6,7,8,9,10,11),as.data.frame(database)) ## 2.2.4 生态探测> ecological_detector(17,c(2,3,4,5,6,7,8,9,10,11),as.data.frame(database)) # (3) 导出结果> result write.csv(result,'./factor_detector_CMI.csv') *将结果写入csv文件* geodetector包应用示例代码: geo_data = read_xlss("his1_1.xlsx") #11代表第11列的因变量;c(6,7,8,9,10)代表五个因变量; result_1 library(readr)Examples ## NDVI: ndvi_40 # set optional parameters of optimal discretization # optional methods: equal, natural, quantile, geometric, sd and manual discmethod |







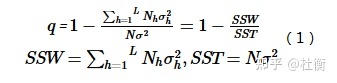
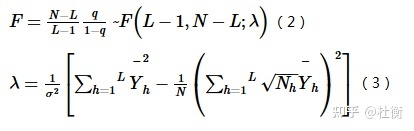
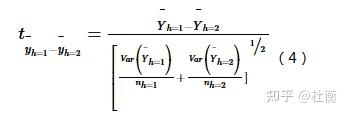
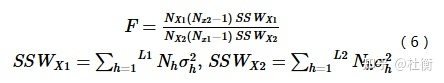
【本文地址】