| 【Python爬虫】使用etree进行XPath解析 | 您所在的位置:网站首页 › python的xpath › 【Python爬虫】使用etree进行XPath解析 |
【Python爬虫】使用etree进行XPath解析
|
【Python爬虫】使用etree进行XPath解析
文章目录
【Python爬虫】使用etree进行XPath解析一、相关知识etree的使用编码流程环境安装实例化etree对象
XPath语法
二、实例 - 爬取全国城市名称🔍网页分析背景介绍页面分析
💻代码
一、相关知识
etree的使用
编码流程
将HTML文本加载到etree对象中调用etree的xpath()函数完成标签定位对标签为所欲为(此时获得的标签其实是xpath()函数返回的对象)
环境安装
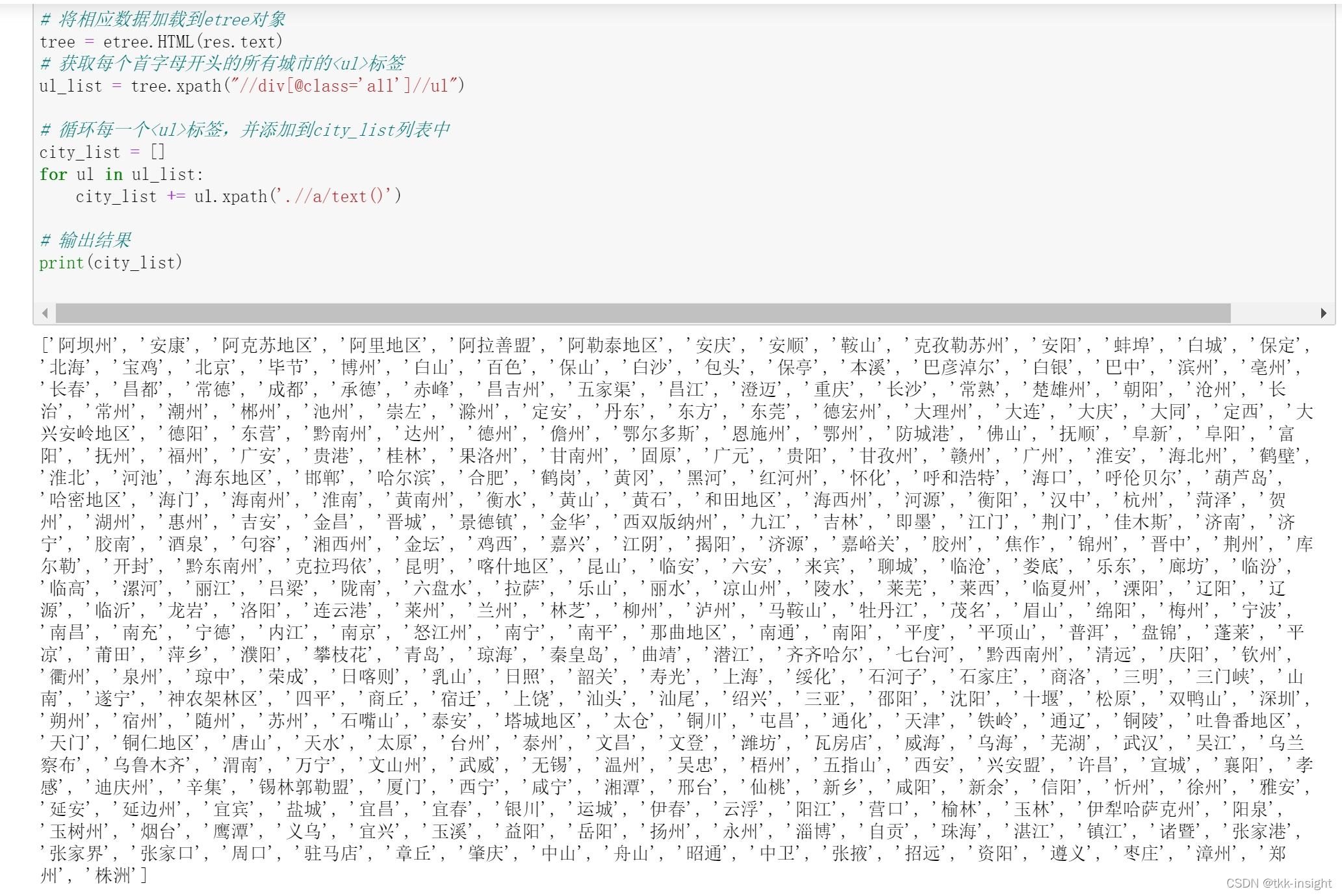
pip install lxml 实例化etree对象 # 首先导入模块 from lxml import etree 从本地加载HTMLfilePath = '你的HTML文件路径' tree = etree.parse(filePath) 从响应数据加载HTMLurl = '某个网址' respose = requests.get(url) tree = etree.HTML(respose.text) XPath语法XPath相关知识详见:https://www.runoob.com/xpath/xpath-syntax.html 注: /text()获取的是标签直系文本//text()获取的是标签下所有文本 二、实例 - 爬取全国城市名称 🔍网页分析 背景介绍要爬取的网站:https://www.aqistudy.cn/historydata/ 这是个提供城市pm2.5相关数据的网站,可以看到我们想要的城市名都在下面啦 网站结构还是非常清晰的,每个首字母对应的所有城市在一个标签中 于是我们可以这样写xpath://div[@class='all']//ul 当然定位方式有多种,大家可以ctrl+F输入xpath来测试语句是否正确,比如 代码非常简单,就不多解释啦 from lxml import etree import requests headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36 Edg/96.0.1054.62' } url = 'https://www.aqistudy.cn/historydata/' res = requests.get(url=url, headers=headers) # 将相应数据加载到etree对象 tree = etree.HTML(res.text) # 获取每个首字母开头的所有城市的标签 ul_list = tree.xpath("//div[@class='all']//ul") # 循环每一个标签,并添加到city_list列表中 city_list = [] for ul in ul_list: city_list += ul.xpath('.//a/text()') # 输出结果 print(city_list)》输出 》 |

 所以目标就很明确了,定位到每个城市对应的标签,获取标签文本即可
所以目标就很明确了,定位到每个城市对应的标签,获取标签文本即可 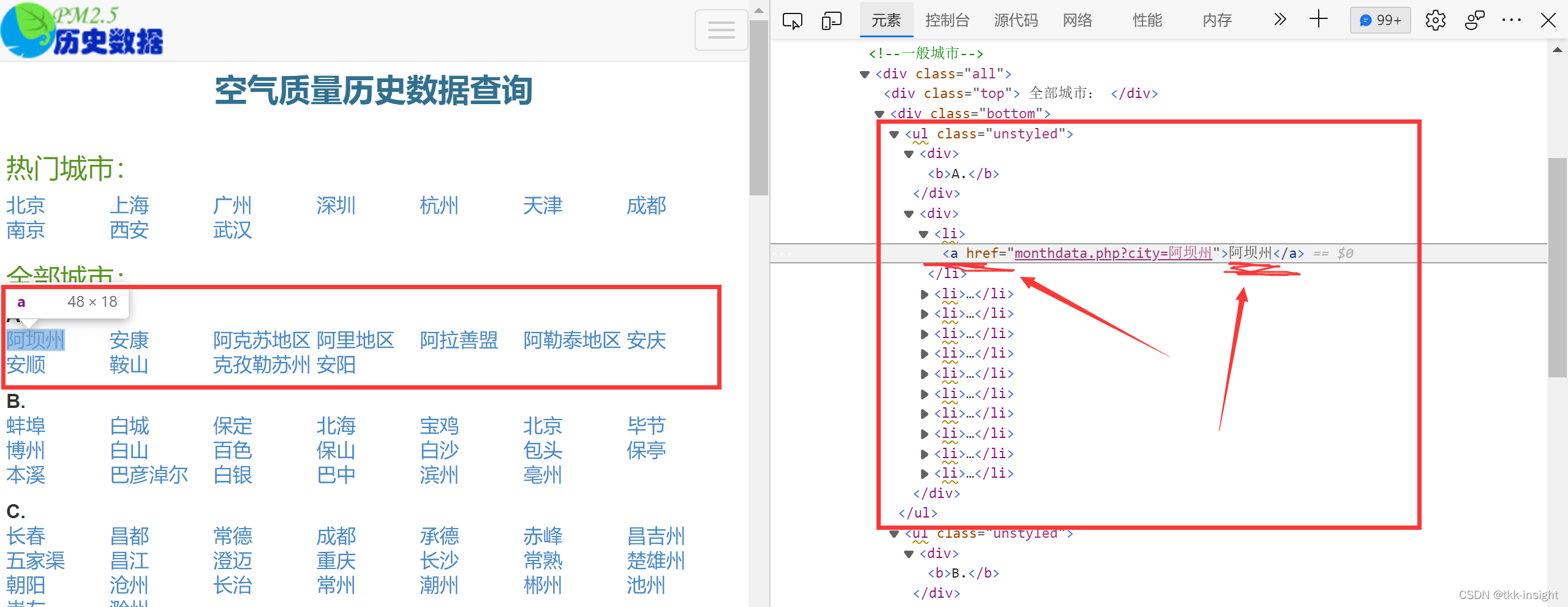 先定位标签,发现热门城市和全部城市下面的的class属性是相同的,顺着父节点往上找,,,思路如下
先定位标签,发现热门城市和全部城市下面的的class属性是相同的,顺着父节点往上找,,,思路如下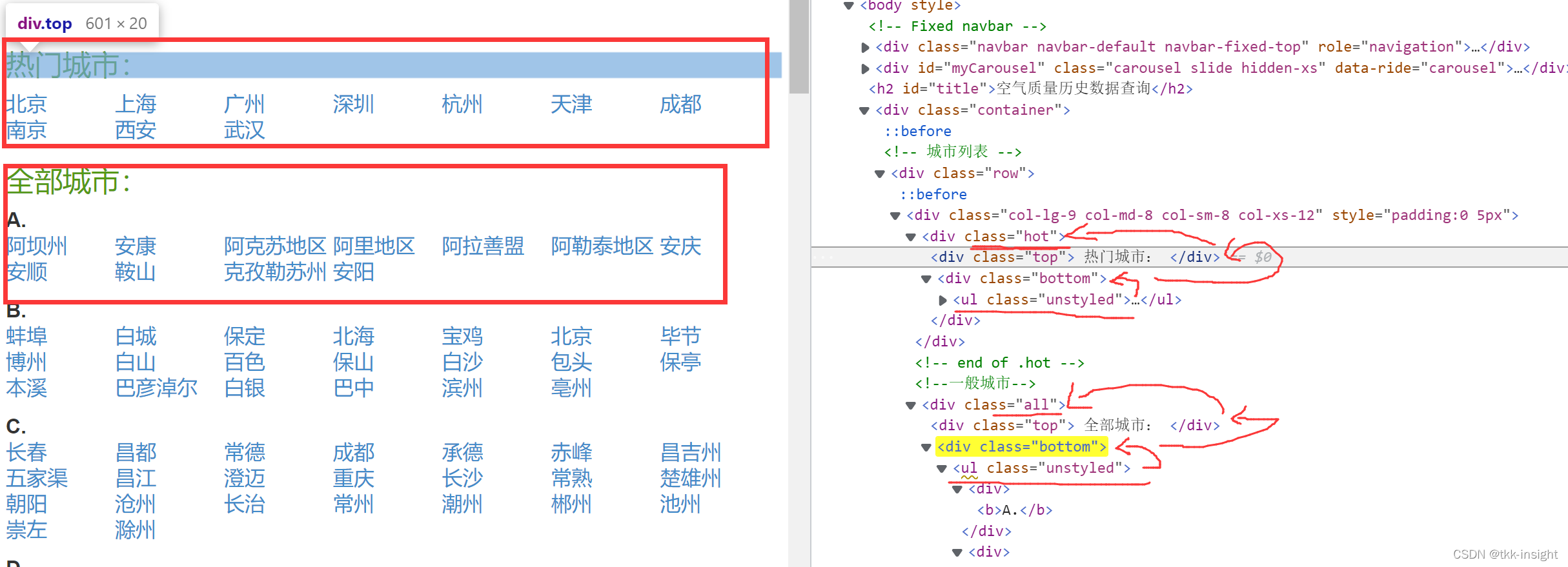
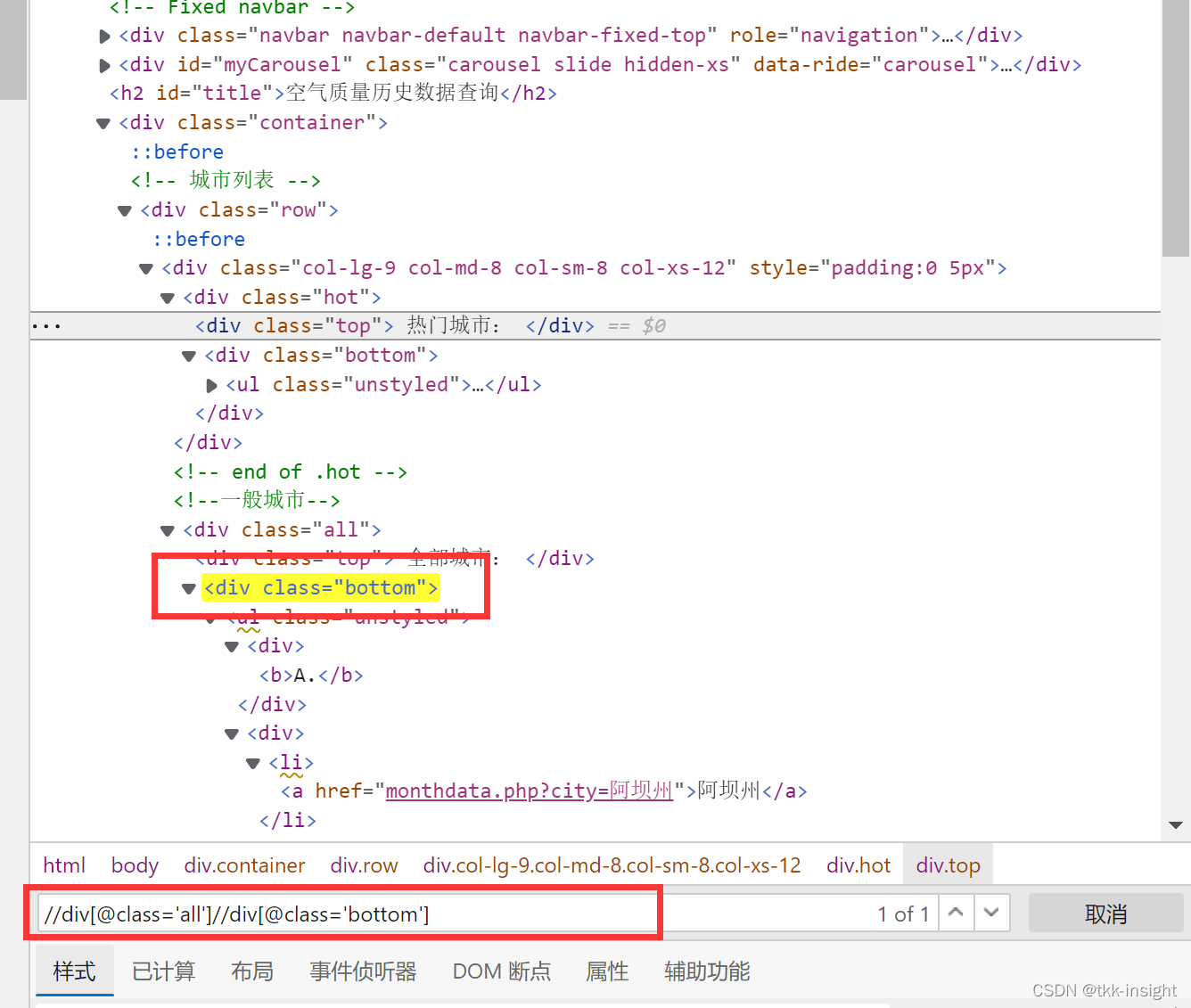
【本文地址】
公司简介
联系我们