| Python3爬虫之模拟post登陆及get登陆 | 您所在的位置:网站首页 › python模拟登录网站提交数据错误 › Python3爬虫之模拟post登陆及get登陆 |
Python3爬虫之模拟post登陆及get登陆
|
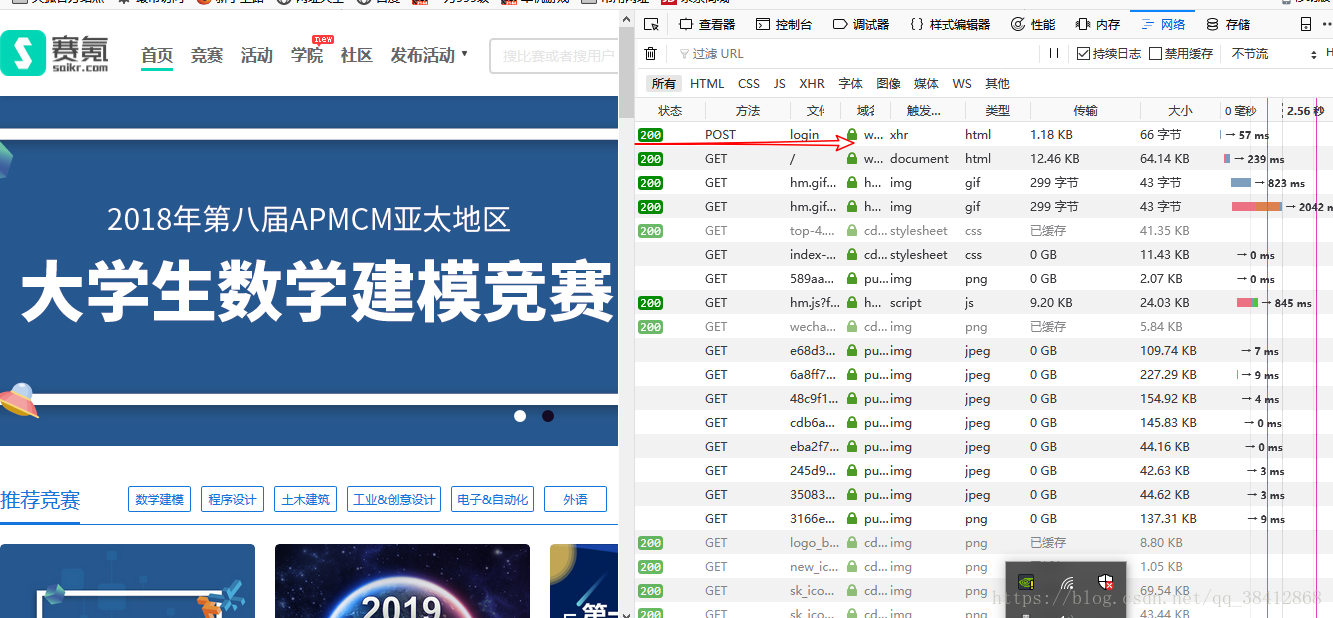
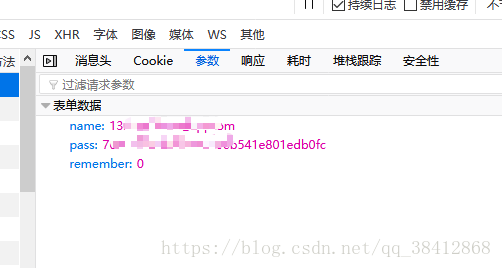
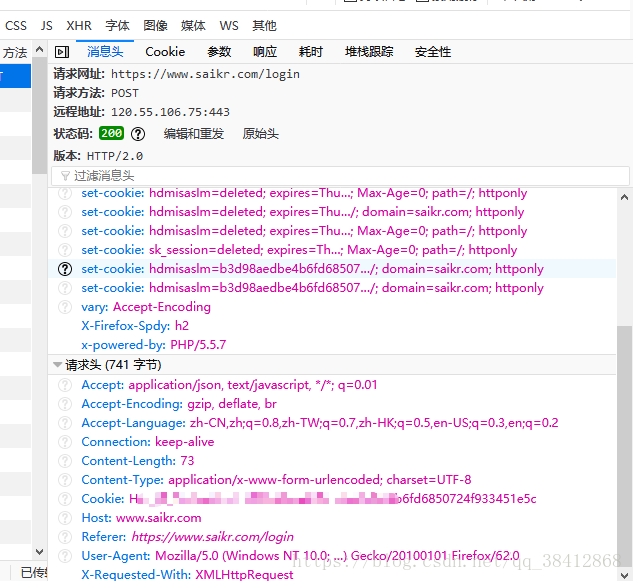
一、模拟登陆需要账号,密码的网址 一些不需要登陆的网址操作已经试过了,这次来用Python尝试需要登陆的网址,来利用cookie模拟登陆 由于我们教务系统有验证码偏困难一点,故挑了个软柿子捏,赛氪,https://www.saikr.com 我用的是火狐浏览器自带的F12开发者工具,打开网址输入账号,密码,登陆,如图 可以看到捕捉到很多post和get请求,第一个post请求就是我们提交账号和密码的, 点击post请求的参数选项可以看到我们提交的参数在bian表单数据里,name为账户名,pass为加密后的密码,remember为是否记住密码,0为不记住密码。 我们再来看看headers,即消息头 我们把这些请求头加到post请求的headers后对网页进行模拟登陆, Cookie为必填项,否则会报错: {"code":403,"message":"访问超时,请重试,多次出现此提示请联系QQ:1409765583","data":[]} 便可以创建一个带有cookie的opener,在第一次访问登录的URL时,将登录后的cookie保存下来,然后利用带有这个cookie的opener来访问该网址的其他版块,查看登录之后才能看到的信息。 比如我是登陆https://www.saikr.com/login后模拟登陆了“我的竞赛”版块https://www.saikr.com/u/5598522 代码如下: import urllib from urllib import request from http import cookiejar login_url = "https://www.saikr.com/login" postdata ={ "name": "your account","pass": "your password(加密后)" } header = { "Accept":"application/json, text/javascript, */*; q=0.01", "Accept-Language":"zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2", "Connection":"keep-alive", "Host":"www.saikr.com", "Referer":"https://www.saikr.com/login", "Cookie":"your cookie", "Content-Type": "application/x-www-form-urlencoded; charset=UTF-8", "TE":"Trailers","X-Requested-With":"XMLHttpRequest" } postdata = urllib.parse.urlencode(postdata).encode('utf8') #req = requests.post(url,postdata,header) #声明一个CookieJar对象实例来保存cookie cookie = cookiejar.CookieJar() #利用urllib.request库的HTTPCookieProcessor对象来创建cookie处理器,也就CookieHandler cookie_support = request.HTTPCookieProcessor(cookie) #通过CookieHandler创建opener opener = request.build_opener(cookie_support) #创建Request对象 my_url="https://www.saikr.com/u/5598522" req1 = request.Request(url=login_url, data=postdata, headers=header)#post请求 req2 = request.Request(url=my_url)#利用构造的opener不需要cookie即可登陆,get请求 response1 = opener.open(req1) response2 = opener.open(req2) print(response1.read().decode('utf8')) print(response2.read().decode('utf8'))到此就告一段落了: ps:有点小插曲,当在headers里加入 Accept-Encodinggzip, deflate, br 时,最后在 print(response1.read().decode('utf8'))时便会报错 UnicodeDecodeError: 'utf-8' codec can't decode byte 0x8b in position 1: invalid start byte 原因:在请求header中设置了'Accept-Encoding': 'gzip, deflate' 参考链接:https://www.cnblogs.com/chyu/p/4558782.html 解决方法:去掉Accept-Encoding后就正常了 二、模拟登陆网址常用方法总结 1.通过urllib库的request库的函数进行请求 from urllib import request #get请求 ------------------------------------------------------ #不加headers response=request.urlopen(url) page_source = response.read().decode('utf-8') #加headers,由于urllib.request.urlopen() 函数不接受headers参数,所以需要构建一个urllib.request.Request对象来实现请求头的设置 req= request.Request(url=url,headers=headers) response=request.urlopen(req) page_source = response.read().decode('utf-8') #post请求 ------------------------------------------------------- postdata = urllib.parse.urlencode(data).encode('utf-8')#必须进行重编码 req= request.Request(url=url,data=postdata,headers=headers) response=request.urlopen(req) page_source = response.read().decode('utf-8') #使用cookie访问其他版块 #声明一个CookieJar对象实例来保存cookie cookie = cookiejar.CookieJar() #利用urllib.request库的HTTPCookieProcessor对象来创建cookie处理器,也就CookieHandler cookie_support = request.HTTPCookieProcessor(cookie) #通过CookieHandler创建opener opener = request.build_opener(cookie_support) # 将Opener安装位全局,覆盖urlopen函数,也可以临时使用opener.open()函数 #urllib.request.install_opener(opener) #创建Request对象 my_url="https://www.saikr.com/u/5598522" req2 = request.Request(url=my_url) response1 = opener.open(req1) response2 = opener.open(req2) #或者直接response2=opener.open(my_url) print(response1.read().decode('utf8')) print(response2.read().decode('utf8'))
2.通过requests库的get和post函数 import requests import urllib import json #get请求 ----------------------------------------------------------- #method1 url="https://www.saikr.com/" params={ 'key1': 'value1','key2': 'value2' } real_url = base_url + urllib.parse.urlencode(params) #real_url="https://www.saikr.com/key1=value1&key2=value2" response=requests.get(real_url) #method2 response=requests.get(url,params) print(response.text)# print(response.content)# #post请求 login_url = "https://www.saikr.com/login" postdata ={ "name": "[email protected]","pass": "my password", } header = { "Accept":"application/json, text/javascript, */*; q=0.01", "Accept-Language":"zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2", "Connection":"keep-alive", "Host":"www.saikr.com", "Referer":"https://www.saikr.com/login", "Cookie":"mycookie", "Content-Type": "application/x-www-form-urlencoded; charset=UTF-8", "TE":"Trailers","X-Requested-With":"XMLHttpRequest" } #requests中的post中传入的data可以不进行重编码 #login_postdata = urllib.parse.urlencode(postdata).encode('utf8') response=requests.post(url=login_url,data=postdata,headers=header)# #以下三种都可以解析结果 json1 = response1.json()# json2= json.loads(response1.text)# json_str = response2.content.decode('utf-8')# #利用session维持会话访问其他版块 -------------------------------------------------------------------- login_url = "https://www.saikr.com/login" postdata ={ "name": "[email protected]","pass": "my password", } header = { "Accept":"application/json, text/javascript, */*; q=0.01", "Connection":"keep-alive", "Referer":"https://www.saikr.com/login", "Cookie":"mycookie", } session = requests.session() response = session.post(url=url, data=data, headers=headers) my_url="https://www.saikr.com/u/5598522" response1 = session.get(url=my_url, headers=headers) print(response1.json())
|
【本文地址】