| FastAPI:快速开发一个文本转语音的接口 | 您所在的位置:网站首页 › python文字转语音wav › FastAPI:快速开发一个文本转语音的接口 |
FastAPI:快速开发一个文本转语音的接口
|
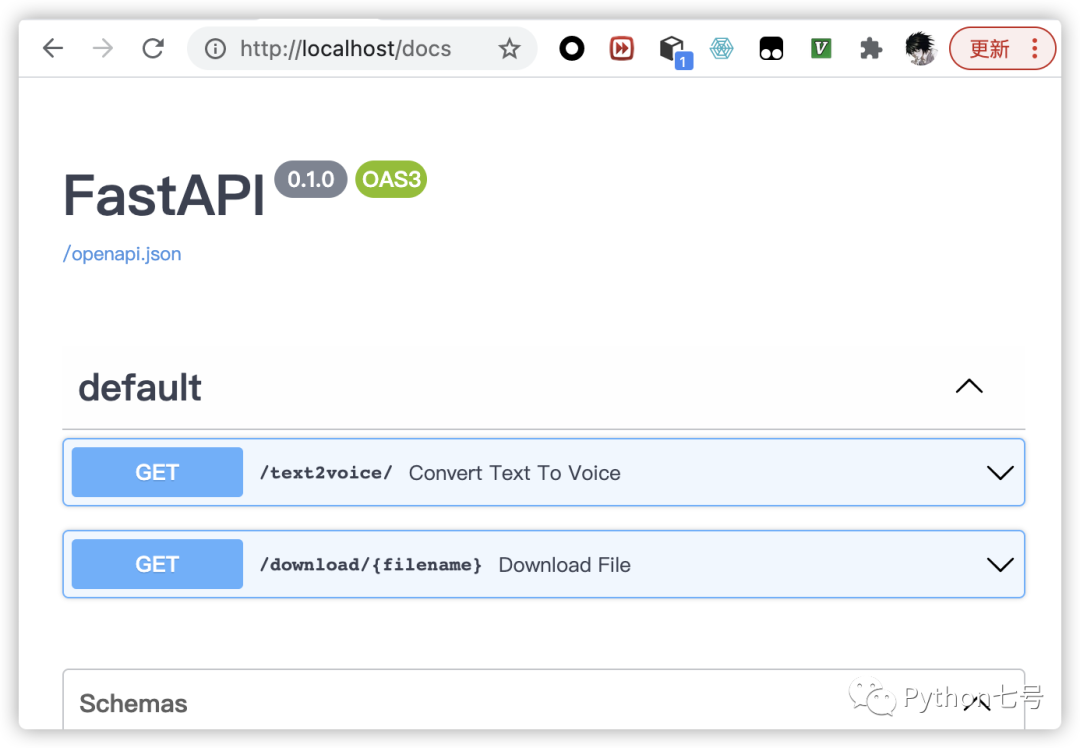
这段音频就是本文的接口生成的。 Python Web 开发方面有一个很重要的环节就是开发接口,开发接口性能最好的工具就是闪电侠 FastAPI[1],正如它的名字一样,是非常快的 API。当然,还有一些 REST API 框架,如 Django REST Framework,Flask-RESTful 等,如果以性能为首要考虑因素,那毫无疑问选择 FastAPI。 结合现在比较流行的文本转语音的应用场景,本文展示如何用 FastAPI 来快速开发一个文本转语音的接口,其中详细罗列了每一步骤,让你学会开发 Web 接口,学不会你找我「微信 somenzz」。 主要内容: 先写出主要的函数 将函数转化为 Web API 写个前端界面 发布成 Docker 镜像 1、先写出主要的函数首先分析下这个需求,文本转语音接口有两个功能点,一个是将文件转成语音,另一个是下载语音文件,将这两个功能先写两个简单函数,然后逐步细化。 def convert_text_to_voice(text: str) -> str: """ 将文件转成语音文件,返回语音文件的文件名 """ file_name = text_to_voice(text) # text_to_voice 负责将 text 转成语音文件,后面再实现 return file_name def download_file(filename: str): """ 返回一下 FileResponse 对象 """ return 文件对象上述代码中有个 text_to_voice 函数,其逻辑就是将文本转语音文件,返回其文件名,由于文件名并不是使用者关心的,因此可以用文本的 md5 编码做为文件名,实现不同的文本对应不同的文件,如果已经生成了对应的文件,无需重复生成,直接返回即可,其中文本转语音,我这里使用的是第三方库 `pyttsx3`[2],使用前 pip install pyttsx3 一下,需要注意的是 Linux 或 Mac 需要安装好 ffmpeg 模块。 text_to_voice 主要代码如下: # 文件名 text2voice.py import pyttsx3 from pathlib import Path import hashlib def text_to_voice(text: str, is_man: bool = False) -> str: assert text and text.replace(' ',''), "文本不能为空" filename = hashlib.md5(text.encode()).hexdigest() + ".mp3" filepath = Path('voices') / Path(filename) if filepath.exists(): return filename engine = pyttsx3.init() # object creation engine.save_to_file(text, filepath.as_posix()) engine.runAndWait() engine.stop() return filename if __name__ == '__main__': path = text_to_voice("Python七号,每天学习一个 Python 技巧") print(path)现在一个文本转语音的程序已经好了,万事具备,只欠 FastAPI 了。 2、将函数转化为 Web API如果你是第一次使用 FastAPI,请先阅读一下官方文档 https://fastapi.tiangolo.com/[3],至少把用户指引部分看一遍: 
然后,你就可以很轻松地将第 1 步中的函数转换成对应的 Web API: from text2voice import text_to_voice from fastapi import FastAPI from fastapi.staticfiles import StaticFiles from starlette.responses import FileResponse from pathlib import Path app = FastAPI() @app.get("/text2voice/") def convert_text_to_voice(text: str): filename = text_to_voice(text) return {"filename": filename} @app.get("/download/{filename}") def download_file(filename:str): file_path = Path('voices') / Path(filename) return FileResponse(file_path.as_posix(), filename=filename)以上文件保存为 api.py,命令行执行 uvicorn api:app --host 0.0.0.0 --port 8000 --reload 即可启动 8000 端口上的 http 服务。 现在浏览器访问 http://localhost:8000/docs,就可以对这两个接口进行测试了。 3、写个前端界面如果你不满足于接口开发,可以自己写个前端界面来玩一玩,前端,我推荐 Vue,其他的没时间就不用学了,这个够用了。使用 Vue 前先安装 Node.js, 这个就不说了。 使用 Vue 前请先在 Vue 的官方网站 https://cn.vuejs.org/index.html[4] 学习 Vue 的生命周期,语法,条件渲染,组件化等知识。 第一步:安装 Vue 脚手架。 npm install -g @vue/cli # OR yarn global add @vue/cli可以执行 vue --version 进行验证: (py38env) ➜ ~ vue --version @vue/cli 4.5.13第二步:创建一个项目。 执行: vue create front_end选择最新 Vue 3 
然后等待初始化完成。 第三步:安装依赖。 为了让组件更美观,我这里引入 element-ui, cd front_end vue add element-plus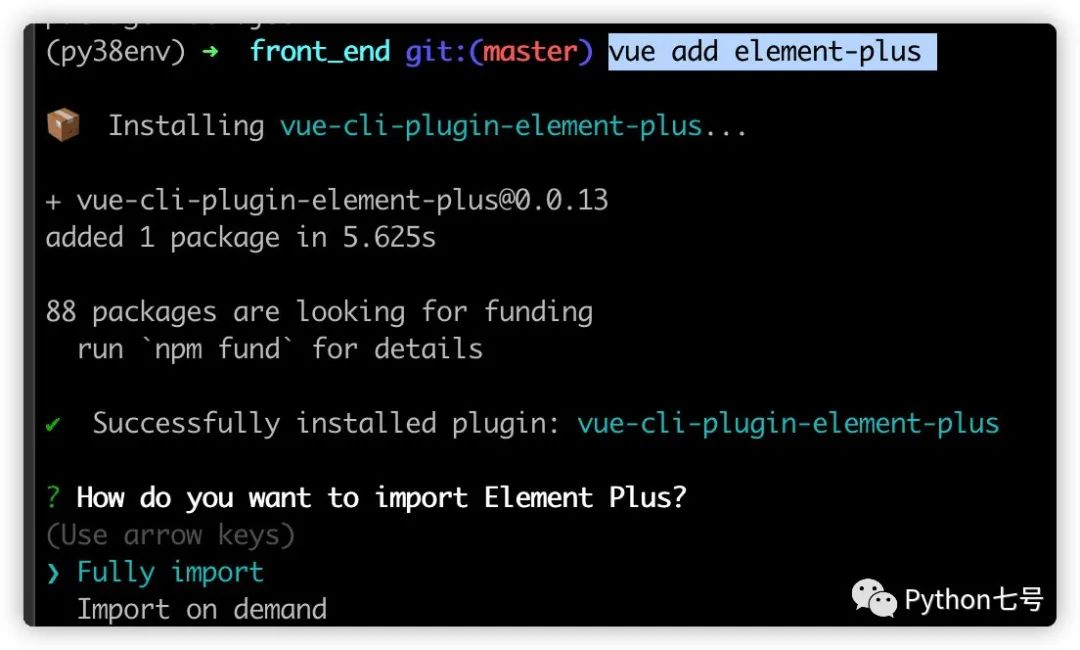
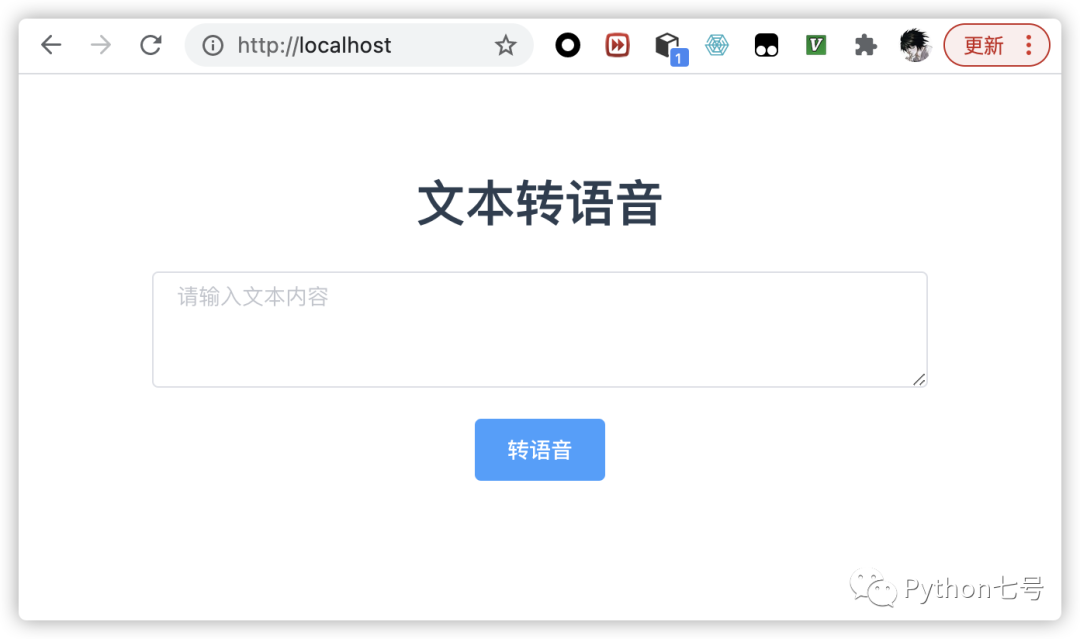
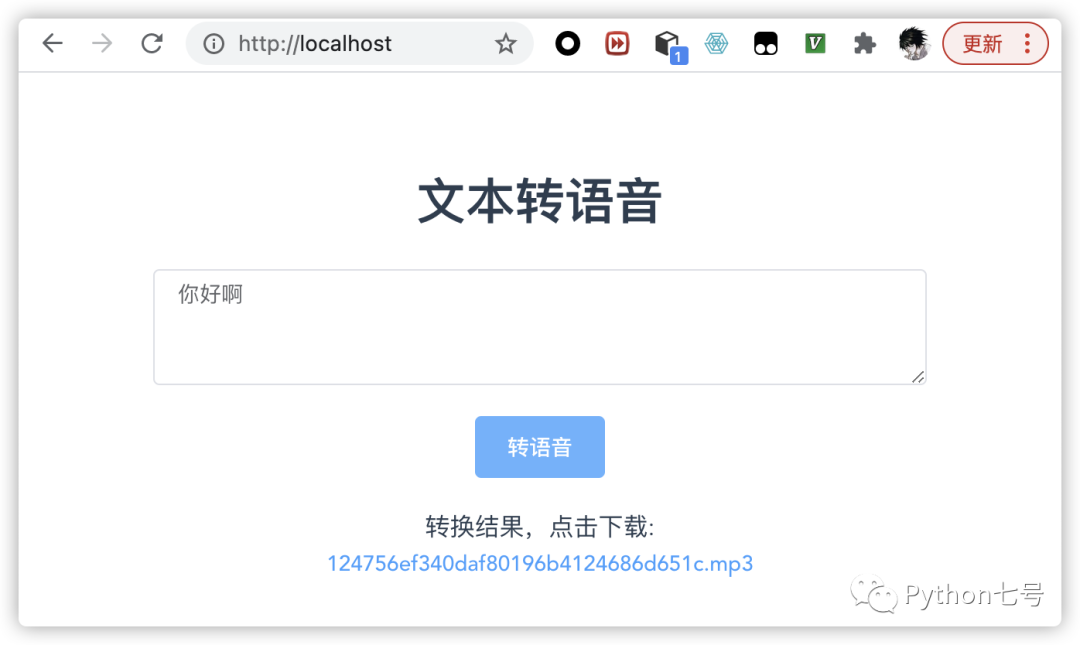
我不在乎那点 js 文件的体积,这里选择全部引入,后面的地区选择 cn 即可。 为了和后端交互,这时使用 axios: npm install axios第四步:编写前端 Vue 文件。 在 front_end/src/components 目录下新建一个 Text2Voice.vue 文件内容如下: 文本转语音 转语音 转换结果,点击下载: {{voice_name}} const api = "http://127.0.0.1:8000"; const axios = require('axios'); export default { name: 'Text2Voice', props: { msg: String }, data(){ return { textarea: '', voice_name: 'xxxx.mp3', download_url: '', convert: false } }, methods: { onConvert(){ if(this.textarea === ""){ this.$message({ message: '文本不能为空', type: 'warning' }); return; } axios.get(`${api}/text2voice/?text=${this.textarea}`) .then( res => { console.log(res); this.voice_name = res.data.filename; this.download_url = `${api}/download/${res.data.filename}`; console.log(this.download_url) this.convert = true; }) } } }然后在 App.vue 中将所有的 HelloWorld 替换为 Text2Voice,然后执行 npm run serve,在浏览器中打开 http://localhost:8080/ 可以看这样的界面: 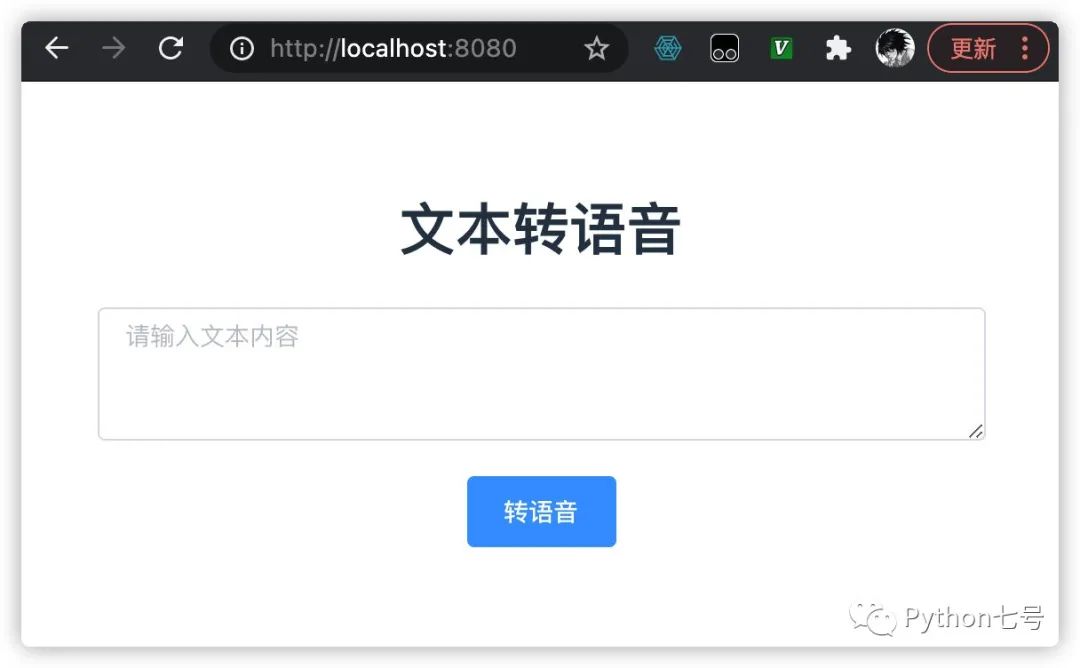
打开浏览器的调试工具 console,然后输入文本测试,发现接口报错: 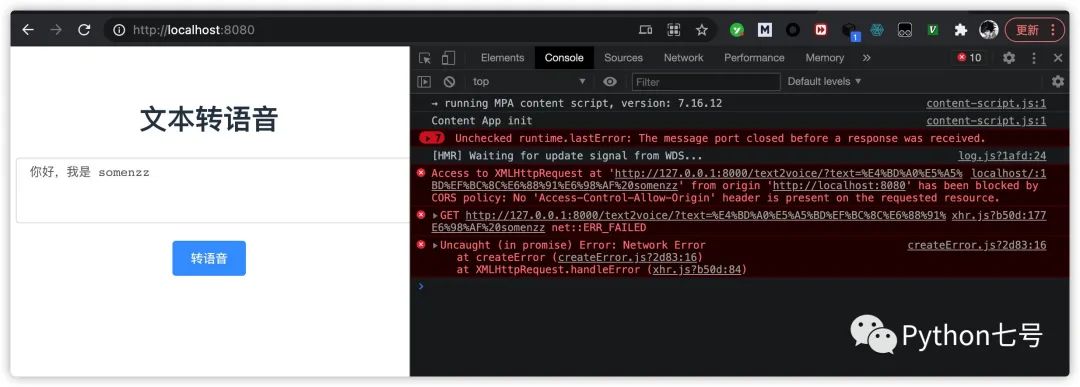
你遇到了一个所有前后端分离开发都会遇到的问题,就是跨域问题,因为 localhost:8080 和 localhost:8000 是两个不同的域,解决方案有两种,一种是让 Vue 走代理,另一种是让后端开启跨域白名单,这里我用第二种,也就是在文件 api.py 加下白名单,最终的代码如下: from text2voice import text_to_voice from fastapi import FastAPI from fastapi.staticfiles import StaticFiles from starlette.responses import FileResponse from pathlib import Path from fastapi.middleware.cors import CORSMiddleware app = FastAPI() origins = [ "http://localhost:8080", ] app.add_middleware( CORSMiddleware, allow_origins=origins, allow_credentials=True, allow_methods=["*"], allow_headers=["*"], ) @app.get("/text2voice/") def convert_text_to_voice(text: str): filename = text_to_voice(text) return {"filename": filename} @app.get("/download/{filename}") def download_file(filename:str): file_path = Path('voices') / Path(filename) return FileResponse(file_path.as_posix(), filename=filename) app.mount("/", StaticFiles(directory="front_end/dist",html = True), name="static")至此,你会现在接口可以正常使用了。 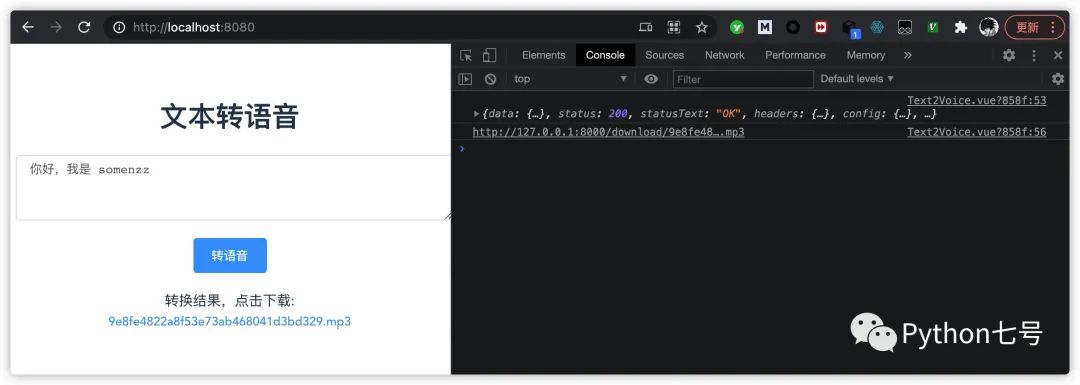
第五步:编译。最后,执行 npm run build 编译,会生成 index.html,js,css 等静态资源,然后将 fastapi 的静态资源指向这个目录,对应的代码就是: app.mount("/", StaticFiles(directory="front_end/dist",html = True), name="static")打开 http://localhost:8000 就可以访问前端界面,此时不存在跨域问题,关闭跨域白名单也不影响使用。正式部署时可以将接口改成这样: axios.get(`/text2voice/?text=${this.textarea}`) .then( res => { console.log(res); this.voice_name = res.data.filename; this.download_url = `${api}/download/${res.data.filename}`; console.log(this.download_url) this.convert = true; }) 4、发布成 Docker 镜像你写好的东东别人怎么用呢?目前最流行的方式就是发布成 Docker 镜像,使用者无需一步一步处理环境配置,一条 docker run 命令就可以使用你的程序了,非常高效。 在 api.py 文件同级别的目录中新建文件 Dockerfile,内容如下: FROM tiangolo/uvicorn-gunicorn-fastapi:python3.7 RUN apt update && apt -y install espeak ffmpeg libespeak1 COPY ./ /app当然了,为了不让 Docker 镜像过大,我们需要忽略一些不必要的文件,借助 .dockerignore 文件完成,内容如下: front_end/node_modules front_end/public front_end/src front_end/package.json front_end/package-lock.json front_end/babel.config.js voices __pycache__ front_end/.DS_Store /front_end/.git/在 Dockerfile 的同一级目录执行 docker build -t text2voice . 打包镜像文件。 执行 docker images | grep text2voice 查看一下已经打包好的镜像: 然后启动容器,测试一下: docker run -d -p 80:80 -e MODULE_NAME="api" -e PORT=80 text2voice注意:这里的 -e MODULE_NAME="api" -e PORT=80 意思是设置环境变量,表示我们的 FastAPI 的主程序是 api.py,运行在端口 80 上, -p 80:80 表示将容器的 80 端口暴露给宿主机(本机)的 80 端口,现在打开浏览器,输入 http://localhost 看一下效果:
OK,接下来就是发布了。先在 https://hub.docker.com/ 上注册一个账号,并创建一个仓库,比如叫 text2voice。 注意,我们创建的仓库是 text2voice,假如你的账号 id 叫 somenzz,因此先执行docker tag text2voice somenzz/text2voice 给已打包好的镜像再打个标签,然后执行 docker push somenzz/text2voice 就可以上传本地镜像到 https://hub.docker.com。 接下来,别人就可以执行一条命令使用你的程序了,前提是已经安装好 Docker: docker run -d -p 80:80 -e MODULE_NAME="api" -e PORT=80 somenzz/text2voicedocker 会自动下载镜像,并启动一个容器,别人在浏览器打开 http://localhost 即可访问接口服务。接口文档:http://localhost/docs。 最后的话麻雀最小,五脏俱全。以上涉及的接口开发,前端开发,发布 Docker 等环节,虽然简单,却也展示了 Web 开发的一套流程,如果对你的 Web 开发有所帮助,请在看、点赞支持。 都看到这里了,你确定不关注一下吗? 回复「文本转语音」获取全部源代码。 留言讨论 推荐阅读: FastAPI框架诞生的缘由(上) FastAPI框架诞生的缘由(下) 手摸手,带你入门docker 参考资料[1] FastAPI: https://fastapi.tiangolo.com/ [2]pyttsx3: https://github.com/nateshmbhat/pyttsx3 |
【本文地址】