| 用Python读取PDF文档 | 您所在的位置:网站首页 › python打开文档 › 用Python读取PDF文档 |
用Python读取PDF文档
|
从慕课网《python遇见数据采集》课程中学到读取PDF文档的方法,特记录如下: 安装并引入pdfminer3k包: from pdfminer.pdfinterp import PDFPageInterpreter from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter from pdfminer.converter import TextConverter, PDFPageAggregator from pdfminer.layout import LAParams from pdfminer.pdfdevice import PDFDevice from pdfminer.pdfparser import PDFParser, PDFDocument大致思路: 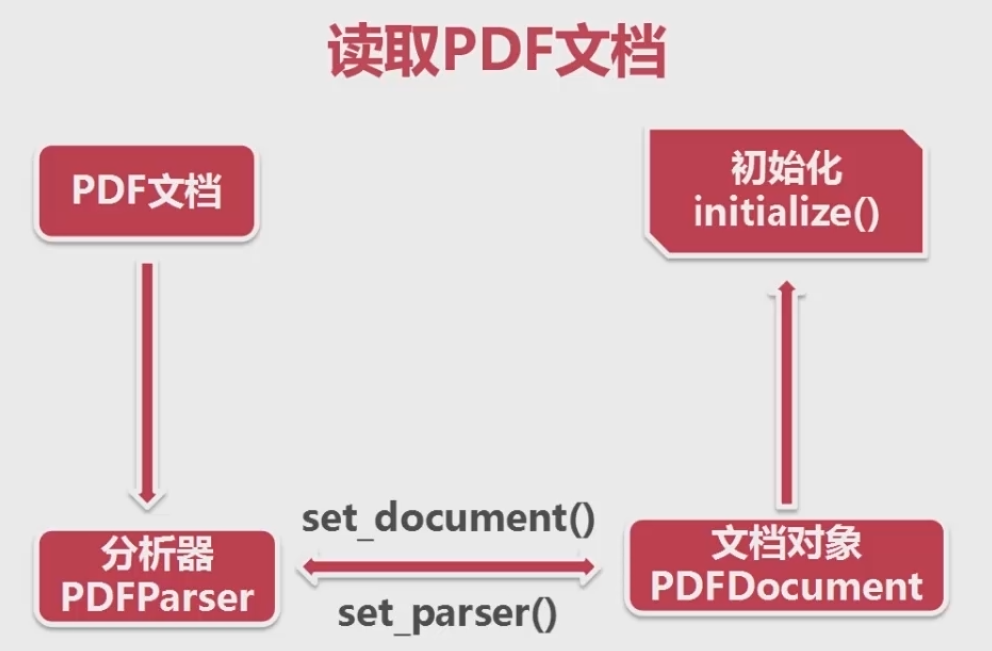 1、首先使用 open 方法或者 urlopen 打开本地文档(注意路径引入正确) #获取文档对象 fp=open("selenium_documentation_0.pdf","rb")2、接着创建 文档解析器 和 PDF文档对象 并将他们相互关联: #创建一个与文档关联的解释器 parser=PDFParser(fp) #PDf文档的对象 doc=PDFDocument() #链接解释器和文档对象 parser.set_document(doc) doc.set_parser(parser)3、对 PDF文档对象 进行初始化,如果文档本身进行了加密,则需要在加入 password 参数 #初始化文档 doc.initialize("") 4、创建 PDF资源管理器和参数分析器: #创建PDF资源管理器 resource=PDFResourceManager() #参数分析器 laparam=LAParams()5、再创建一个聚合器 ,并接收PDF资源管理器 、参数分析器 作为参数: #创建一个聚合器 device=PDFPageAggregator(resource,laparams=laparam)6、最后创建一个 页面解释器 ,将 PDF资源管理器 和 聚合器 作为参数: #创建PDF页面解释器 interpreter=PDFPageInterpreter(resource,device)这样 页面解释器就具有对PDF文档进行编码,解释成Python能够识别的格式 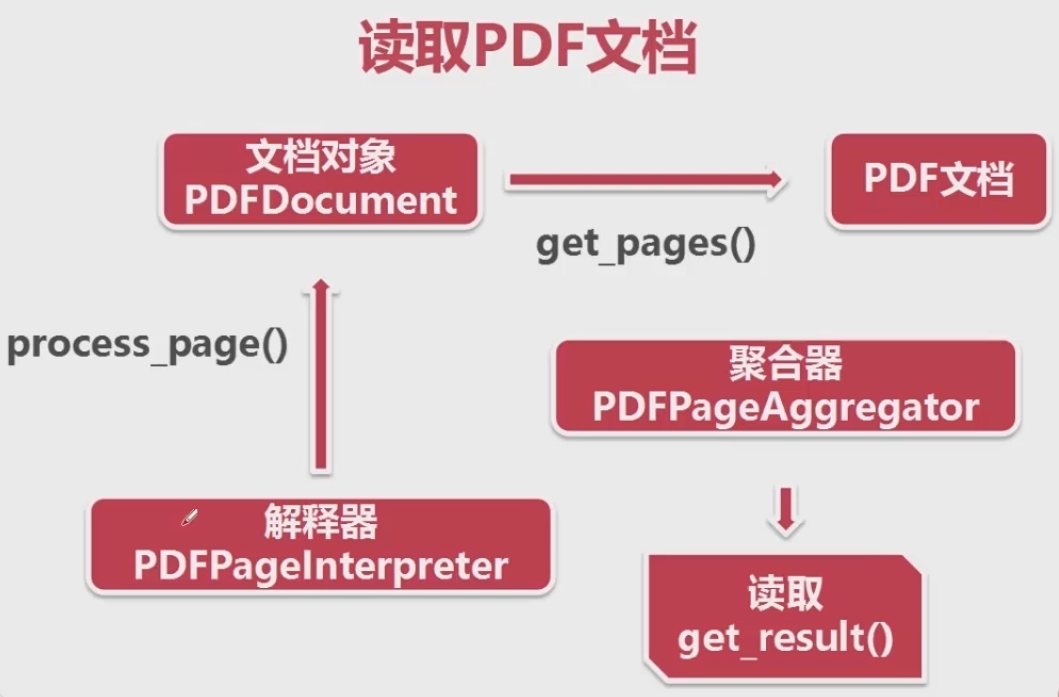 7、最后,使用 PDF文档对象 的 get_pages()方法 从PDF文档中读取出页面集合,接着使用 页面解释器 对页面集合逐一读取,再调用 聚合器 的 get_result()方法 将页面逐一放置到 layout 之中,最后商用 layout 的 get_text()方法 获取每一页的 text #使用文档对象得到页面的集合 for page in doc.get_pages(): #使用页面解释器来读取 interpreter.process_page(page) #使用聚合器来获得内容 layout=device.get_result() for out in layout: if hasattr(out, 'get_text'): # 需要注意的是在PDF文档中不只有 text 还可能有图片等等,为了确保不出错先判断对象是否具有 get_text()方法 完整的代码 print(out.get_text())运行结果显示如下: 
|
【本文地址】
公司简介
联系我们