| 异常检测算法:LOF算法(Local Outlier Factor)的python代码实现 | 您所在的位置:网站首页 › python代码检查方法 › 异常检测算法:LOF算法(Local Outlier Factor)的python代码实现 |
异常检测算法:LOF算法(Local Outlier Factor)的python代码实现
|
文章目录
LOF算法算法介绍代码实现可视化
LOF算法
算法介绍
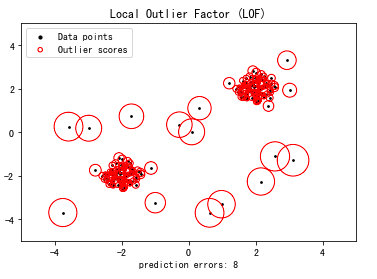
Local Outlier Factor(LOF)是基于密度的经典算法,也十分适用于anomaly detection的工作。 基于密度的离群点检测方法的关键步骤在于给每个数据点都分配一个离散度,其主要思想是:针对给定的数据集,对其中的任意一个数据点,如果在其局部邻域内的点都很密集,那么认为此数据点为正常数据点,而离群点则是距离正常数据点最近邻的点都比较远的数据点。通常有阈值进行界定距离的远近。 LOF 主要通过计算一个数值 score 来反映一个样本的异常程度。这个数值的大致意思是:一个样本点周围的样本点所处位置的平均密度比上该样本点所在位置的密度。如果这个比值越接近1,说明 p 的其邻域点密度差不多, p 可能和邻域同属一簇;如果这个比值越小于1,说明 p 的密度高于其邻域点目睹,p 为密度点;如果这个比值越大于1,说明 p 的密度小于其邻域点密度, p 越可能是异常点。 代码实现使用sklearn中的相关包来实现LOF算法,举一个很简单的小demo: import numpy as np from sklearn.neighbors import LocalOutlierFactor as LOF X = [[-1.1], [0.2], [10.1], [0.3]] clf = LOF(n_neighbors=2) predict = clf.fit_predict(X) """ 运行结果是: [ 1 1 -1 1] """ print(predict) # negative_outlier_factor_是相反的LOF,数值越大越正常;数值越小越不正常,可能是离群点 scores = clf.negative_outlier_factor_ """ 运行结果是: [-0.98214286 -1.03703704 -7.16600529 -0.98214286] """ print(scores)其他的内置函数以及介绍在:scikit-learn-lof 可视化sklearn上的可视化案例,链接为:scikit-learn import numpy as np import matplotlib.pyplot as plt from sklearn.neighbors import LocalOutlierFactor np.random.seed(42) # Generate train data X_inliers = 0.3 * np.random.randn(100, 2) X_inliers = np.r_[X_inliers + 2, X_inliers - 2] # Generate some outliers X_outliers = np.random.uniform(low=-4, high=4, size=(20, 2)) X = np.r_[X_inliers, X_outliers] n_outliers = len(X_outliers) ground_truth = np.ones(len(X), dtype=int) ground_truth[-n_outliers:] = -1 # fit the model for outlier detection (default) clf = LocalOutlierFactor(n_neighbors=20, contamination=0.1) # use fit_predict to compute the predicted labels of the training samples # (when LOF is used for outlier detection, the estimator has no predict, # decision_function and score_samples methods). y_pred = clf.fit_predict(X) n_errors = (y_pred != ground_truth).sum() X_scores = clf.negative_outlier_factor_ plt.title("Local Outlier Factor (LOF)") plt.scatter(X[:, 0], X[:, 1], color='k', s=3., label='Data points') # plot circles with radius proportional to the outlier scores radius = (X_scores.max() - X_scores) / (X_scores.max() - X_scores.min()) plt.scatter(X[:, 0], X[:, 1], s=1000 * radius, edgecolors='r', facecolors='none', label='Outlier scores') plt.axis('tight') plt.xlim((-5, 5)) plt.ylim((-5, 5)) plt.xlabel("prediction errors: %d" % (n_errors)) legend = plt.legend(loc='upper left') legend.legendHandles[0]._sizes = [10] legend.legendHandles[1]._sizes = [20] plt.show()最终的结果是:
上图中,每个圈代表各自的LOF得分。LOF越大,这个点越可能是异常点,在这个图上的直观显示就是圆越大。 |
【本文地址】
公司简介
联系我们