| Pandas中describe()函数的使用介绍 | 您所在的位置:网站首页 › python中round的含义 › Pandas中describe()函数的使用介绍 |
Pandas中describe()函数的使用介绍
|
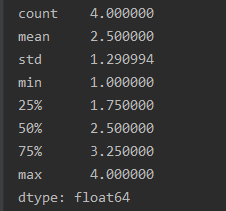
Pandas中describe()函数的使用介绍 一、describe()函数介绍 pandas 是基于numpy构建的含有更高级数据结构和工具的数据分析包,提供了高效地操作大型数据集所需的工具。pandas有两个核心数据结构 Series和DataFrame,分别对应了一维的序列和二维的表结构。而describe()函数就是返回这两个核心数据结构的统计变量。其目的在于观察这一系列数据的范围、大小、波动趋势等等,为后面的模型选择打下基础。(更多内容,可参阅程序员在旅途) pandas.DataFrame.describe 的官方文档。 DataFrame.describe(percentiles=None, include=None, exclude=None) # return: Series or DataFrame. Summary statistics of the Series or Dataframe provided.二、使用案例 2.1 统计一个 series 信息 列值为数字的: import pandas as pd s = pd.Series([1, 2, 3, 4]) print(s.describe())
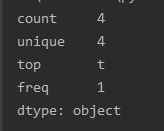
列值为非数字的: a = pd.Series(['a', 'd', 'r', 't']) print(a.describe())
注意上面两幅图,字母列和数值列的统计结果是不一样的。 2.2 统计一个dataframe的信息 import pandas as pd c = pd.DataFrame({'categorical': pd.Categorical(['d', 'e', 'f']), 'numeric': [1, 2, 3], 'object': ['a', 'b', 'c']}) print(c) desc = c.describe(include='all') # include='all',代表对所有列进行统计,如果不加这个参数,则只对数值列进行统计 print(desc)
缺失值由NaN补上,如果为NaN,说明此列的信息不可以用这个统计变量进行统计的。注意,数值列和字母列是不一样的。 统计值变量说明: count:数量统计,此列共有多少有效值 unipue:不同的值有多少个 std:标准差 min:最小值 25%:四分之一分位数 50%:二分之一分位数 75%:四分之三分位数 max:最大值 mean:均值 |

【本文地址】
公司简介
联系我们