| 用Python批量替换多个Word文件中的文字 | 您所在的位置:网站首页 › python一键替换 › 用Python批量替换多个Word文件中的文字 |
用Python批量替换多个Word文件中的文字
|
实例14:用Python批量替换多个Word文件中的文字
PythonOffice 公众号“Python操作Office软件高效工作” 我们在实例7中批量生成了采购合同。但是假设现在我方的公司名由“ABC商贸有限公司”变成了“ABC贸易有限公司”,那我们就需要去每份合同中对应位置进行替换。当然也可以修改原始模板,然后重新生成合同。此处介绍一下如何使用Python批量替换多个Word文件中的文字,即将“商贸”替换为“贸易”。 我们先去到Word文件中,查找一下“商贸”这个词出现了多少次。下图可见,运气不错,只出现了两次,一次在正文的段落中,另一次在末尾的表格中,而且都是我们要替换的。 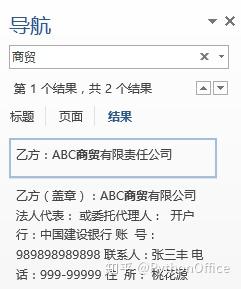 import docxdef info_update(doc,old_info, new_info):
'''此函数用于批量替换合同中需要替换的信息 doc:文件 old_info和new_info:原文字和需要替换的新文字 '''
#读取段落中的所有run,找到需替换的信息进行替换
for para in doc.paragraphs: #
for run in para.runs:
run.text = run.text.replace(old_info, new_info) #替换信息
#读取表格中的所有单元格,找到需替换的信息进行替换
for table in doc.tables:
for row in table.rows:
for cell in row.cells:
cell.text = cell.text.replace(old_info, new_info) #替换信息 import docxdef info_update(doc,old_info, new_info):
'''此函数用于批量替换合同中需要替换的信息 doc:文件 old_info和new_info:原文字和需要替换的新文字 '''
#读取段落中的所有run,找到需替换的信息进行替换
for para in doc.paragraphs: #
for run in para.runs:
run.text = run.text.replace(old_info, new_info) #替换信息
#读取表格中的所有单元格,找到需替换的信息进行替换
for table in doc.tables:
for row in table.rows:
for cell in row.cells:
cell.text = cell.text.replace(old_info, new_info) #替换信息我们上面直接借用实例7中定义好的用于替换文字的函数info_update。只需要向其中传入目标文件路径,待替换的词和新词即可。 然后导入os库,获取目标文件及其路径,如下。 import os #用于获取目标文件所在路径path="data/" # 文件夹路径files=[]for file in os.listdir(path): if file.endswith(".docx"): #排除文件夹内的其它干扰文件,只获取word文件 files.append(path+file) files>>['data/公司001合同.docx', 'data/公司002合同.docx', 'data/公司003合同.docx', 'data/公司004合同.docx', 'data/公司005合同.docx', 'data/公司006合同.docx', 'data/公司007合同.docx', 'data/公司008合同.docx', 'data/公司009合同.docx', 'data/公司010合同.docx']然后就可以开始进行批量替换操作了。可到文件夹“替换结果”中查看结果。 for file in files: doc = docx.Document(file) info_update(doc,"商贸", "贸易") doc.save("data/替换结果/{}".format(file.split("/")[-1])) print("{}替换完成".format(file))>>data/公司001合同.docx替换完成data/公司002合同.docx替换完成data/公司003合同.docx替换完成data/公司004合同.docx替换完成data/公司005合同.docx替换完成data/公司006合同.docx替换完成data/公司007合同.docx替换完成data/公司008合同.docx替换完成data/公司009合同.docx替换完成data/公司010合同.docx替换完成但如果另外的地方也出现了一次或多次“商贸”这个词,且是不能替换的呢?也有办法,我们可以指定替换的段落范围。比如我们故意在“特殊_含干扰词.docx”中间插入4个词“商贸”。这样,我们就有6个“商贸”在文档里了。 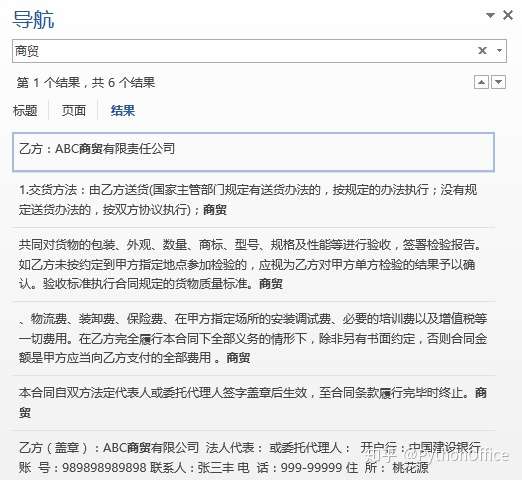 假设我们要替换第一、第三、第六个“商贸”为“贸易”,那我们要先确定出它们在那个段落,即对应paragraph的索引。由于第六个“商贸”在表格中,不在段落中,所以我们只需要找出第一、第三个所在的段落即可。 #获取词"商贸"所在段落import docx #导入docx库doc = docx.Document("data/含干扰词/特殊_含干扰词.docx") #打开word文件text=[]for para in doc.paragraphs: #读取word中的每个段落 text.append(para.text)print(len(text))target_index=[]for i in text: if "商贸" in i: target_index.append(text.index(i))target_index>>77[15, 26, 32, 38, 66]以上,我们还是使用docx模块来读取目标word文件。我们需要知道包含“商贸”一词所在段落,就需要知道其索引。但是我在docx模块中未找到索引相关的函数,因此这里使用了一个变通的方法。即新建一个空列表text,然后将word文档中的所有段落对应的文本提取并存入这个列表。列表是可以使用索引函数的,而列表里面元素的索引正好对应段落的索引。所以只要找到“商贸”一词在列表text中的索引,也就找到了其在段落paragraph中的索引。通过len(text)可知共有77个段落。 然后再新建一个空列表target_index,用于存储包含“商贸”一词的字符串在列表text中的索引。使用for循环遍历列表text中的所有元素,通过if语句判断其中是否包含“商贸”字符,如果包含,则将这个元素对应的索引text.index(i)存入列表target_index。通过结果,可见找到5处含有“商贸”字符串,索引分别为15, 26, 32, 38, 66。 为了验证是否准确,我们可以打印看一下相应索引对应的段落是否真的包含“商贸”一词。如下打印结果显示,结果很理想。 for j in target_index: print(doc.paragraphs[j].text)>>乙方:ABC商贸有限责任公司1.交货方法:由乙方送货(国家主管部门规定有送货办法的,按规定的办法执行;没有规定送货办法的,按双方协议执行);商贸1.所有货物由乙方送到交货地点且甲方确认收货后5天内,由甲乙双方共同对货物的包装、外观、数量、商标、型号、规格及性能等进行验收,签署检验报告。如乙方未按约定到甲方指定地点参加检验的,应视为乙方对甲方单方检验的结果予以确认。验收标准执行合同规定的货物质量标准。商贸总价指甲方的交货价格,该价格应包含货物价格、通关费、包装费、物流费、装卸费、保险费、在甲方指定场所的安装调试费、必要的培训费以及增值税等一切费用。在乙方完全履行本合同下全部义务的情形下,除非另有书面约定,否则合同金额是甲方应当向乙方支付的全部费用 。商贸本合同自双方法定代表人或委托代理人签字盖章后生效,至合同条款履行完毕时终止。商贸因为我们只替换第一、第三、第六个“商贸”为“贸易”,而第六个在表格中。所以需要改一下原来的替换函数info_update,命名为新的函数info_update_new,我们在函数内指定只替换段落15和32中的目标词,表格中的目标词也继续替换。 import docxdef info_update_new(doc,old_info, new_info): '''此函数用于批量替换合同中需要替换的信息 doc:文件 old_info和new_info:原文字和需要替换的新文字 ''' #读取段落中的所有run,找到需替换的信息进行替换 for i in [15,32]: para=doc.paragraphs[i] for run in para.runs: run.text = run.text.replace(old_info, new_info) #替换信息 #读取表格中的所有单元格,找到需替换的信息进行替换 for table in doc.tables: for row in table.rows: for cell in row.cells: cell.text = cell.text.replace(old_info, new_info) #替换信息import os #用于获取目标文件所在路径path="data/含干扰词/" # 文件夹路径files=[]for file in os.listdir(path): if file.endswith(".docx"): #排除文件夹内的其它干扰文件,只获取word文件 files.append(path+file) for file in files: doc = docx.Document(file) info_update_new(doc,"商贸", "贸易") doc.save("data/替换结果/{}".format(file.split("/")[-1])) print("{}替换完成".format(file))>>data/含干扰词/特殊_含干扰词.docx替换完成调用新的替换函数info_update_new,将结果也保存到文件夹“data/替换结果”内。结果如下,可见在完成替换后的文件中,词“商贸”和“贸易”各有3个,只有我们指定位置的词被替换掉了。 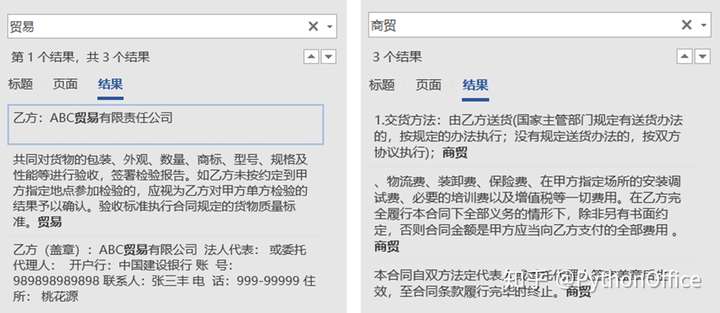
|
【本文地址】