| C/C++ 程序分析内存的几种方法 | 您所在的位置:网站首页 › perf分析进程内存占用 › C/C++ 程序分析内存的几种方法 |
C/C++ 程序分析内存的几种方法
|
对于C/C++程序来说,程序内存的控制是比较棘手的问题。 有时程序稳定增长,超出之前的预估,严重的问题是内存泄露。经常遇到的情况是程序内存占用过大,系统资源不够时,会被 OOM。这时也不能说一定是内存泄露,也许仅仅内存占用过大而已。 下面介绍几种分析内存的方法,能帮我们定位到内存泄露,哪些代码引起代码增长,申请内存的热点路径等。 valgrindvalgrind 实际上一个检测框架,里面集成了多种检测工具,通过 --tool 参数指定,默认的值为memcheck。valgrind 相当于虚拟了 cpu 环境,对于内存的每个地址都进行了跟踪,会降低 20 ~ 30 倍的程序性能,不适用于线上检测。 memcheck Go 1 valgrind --leak-check=yes your-prog [your-prog-options]来检测内存泄露问题。当检测程序退出时,通过 LEAK SUMMARY 可以直观的看到具体的信息。重点关注 definitely lost 和 indirectly lost , 如果报告出了内存问题,基本上是有问题的。通过 HEAP SUMMARY 来查看具体的泄露代码路径。 有时候 memcheck 会报告系统库及常用库的许多信息,基本上没有问题,可以直接忽略,或者通过增加 supp 文件忽略,生成 supp 文件可以设置参数 --gen-suppressions=yes。 还可以设置 --xtree-memory 来查看内存的执行树。 Go 1 valgrind --xtree-memory=full --xtree-memory-file=xtmemory.kcg.%p your-prog [your-prog-options]执行结束后,会生成类似 xtmemory.kcg.26480 文件。 %p 指的是程序PID。这个文件可以通过 kcachegrind 来查看。kcachegrind 是一款 KDE 图形化界面程序,可以在 ubuntu 桌面版上安装此程序,然后打开查看 kcg 后缀的文件。具体安装通过 githup 地址查看 https://github.com/KDE/kcachegrind。
从图形上看,很容易看到哪些部分占用的内存大,哪些地方一直在申请内存而没有释放,以及通过 Callers 看到调用关系。 图形左边的 Self 列可以看到当前函数的内存占用,如果总共内存很大,说明子函数申请的内存比较大。 massif有时候程序并没有内存泄露的问题,但是内存消耗比较严重,或者想知道哪块代码引起了大的内存消耗,也可以使用massif 工具。 Go 1 valgrind --tool=massif your-prog [your-prog-options]massif 默认情况下只会统计分配器的函数,比如 malloc, calloc, realloc, memalign, new, new[],底层的系统调用,比如 mmap, mremap, brk 并没有统计。默认情况下, massif 统计到的内存情况要比 top 工具看到的内存要少。massif 使用快照的方式来展现内存使用状况。 massif 默认会生成 massif.out.%p 文件, %p 是进程ID。命令行的话,可以通过 ms_print 查看。 Go 1 ms_print massif.out.3985massif 的横坐标默认使用执行的指令数,对于耗时短的程序可能展示效果不理想,可以通过 --time-unit= [default: i] 更改。i 是指令数,ms 是毫秒时间,B 是申请的字节数,耗时短的程序可以用这个。 Go 12345678910111213 -------------------------------------------------------------------------------- n time(i) total(B) useful-heap(B) extra-heap(B) stacks(B)-------------------------------------------------------------------------------- 0 0 0 0 0 0 1 172,290 1,016 1,000 16 0 2 172,330 2,032 2,000 32 0 3 172,370 3,048 3,000 48 0 4 172,410 4,064 4,000 64 0 5 172,450 5,080 5,000 80 0 6 172,490 6,096 6,000 96 0 7 172,530 7,112 7,000 112 0 8 172,570 8,128 8,000 128 0 9 172,610 9,144 9,000 144 0useful-heap 是程序申请的内存,由于分配器的实现机制,系统的内存对齐要求等,会有额外的内存来填充申请的内存块。useful-heap 可以理解为有效载荷。申请的内存块包括头部(标识大小),有效载荷,填充。在对 struct 使用中,字段的布局是很重要的,否则会浪费内存空间。 也可以通过图形化界面来查看,也需要 KDE 环境,可以在 Ubuntu 桌面上安装。github 地址 https://github.com/KDE/massif-visualizer。
通过上面的方式有些低级别的内存申请是检测不到的。通过下面命令 Go 1 valgrind --tool=massif --pages-as-heap=yes your-prog [your-prog-options]这样的话,所有的内存都能检测到。查看方式和上面一样。 heaptrack和 massif 类似,也是分析内存性能的。它是通过包装的方式对内存进行统计,也就是对分配器函数 malloc, new 等操作进行了封装。会降低程序 10 ~ 20 倍的性能,只适合线下分析用。和 massif 有几个不同点 没有对底层申请函数的检查,不能做到对全局内存的把控,massif 可以设置参数实现 heaptrack 可以生成大量数据,统计文件是动态生成的,massif 只能程序结束后,文件才生成 heaptrack 可以动态的跟踪,massif 只能在程序启动时设置,heaptrack 通过 -p [PID] 参数动态跟踪github 地址:https://github.com/KDE/heaptrack heaptrack 编译时会包含三个工具 heaptrack 命令行跟踪程序,可以生成统计文件 heaptrack_print 命令行工具查看统计文件 heaptrack_gui 图形化界面查看统计文件,也是一款 KDE 工具这三个工具可以分开安装,在服务器上安装 heaptrack,heaptrack_print, 在 ubuntu 桌面版上安装 heaptrack_gui。 在服务器上安装时使用, 关闭编译 heaptrack_gui Go 1 cmake -DCMAKE_BUILD_TYPE=Release -DHEAPTRACK_BUILD_GUI=Off ..可以使用下面命令生成统计文件 Go 123 heaptrack your-prog [your-prog-options]# 动态跟踪运行时程序heaptrack -p [PID]heaptrack 运行时,统计文件就会生成,可以通过 heaptrack_print 或者 heaptrack_gui 查看,不用等程序结束。
使用 heaptrack_gui 重点关注 Bottom-Up, 从底层函数进行的统计的。 Allocations 申请内存的次数 Temporary 临时申请内存的次数。比如在函数执行中,申请了内存,就立即释放了。应该重点关注下,内存申请是很耗性能的,尽量减少此值,使用缓存或者内存池等 Peak 内存申请的高峰,最高点申请了多少内存 Leaked 截止统计,目前泄露了多少内存,这里使用 leak 并不合适,应该描述成没有释放的内存。有可能是真正的泄露,也有可能内存会一直保留直到程序结束 Allocate 总共申请了多少内存每个标题条目都可以查看, 重点关注 Flame Graph 内存申请的火焰图,内存热点一目了然 Consumed 内存消耗图,横坐标单位为时间 perf上面的工具极大的影响程序性能,只能做线下分析。perf 是一款性能计数器,可以用作线上采样。对程序影响较小。 分配器跟踪:mallocmalloc, free, new, delete 函数是分配器实现的,不是系统调用,通过对这些函数检测来跟踪内存申请热点。 分配器函数是用户态,perf 没有现成的事件支持,需要先添加探针事件。以 malloc 为例说明,标准库中 libc.so.6 本身提供。 可以通过 nm /lib64/libc.so.6 | grep malloc 确定。 添加探针 Go 1 sudo perf probe -x /lib64/libc.so.6 malloc有些系统会报错 uprobe_events file does not exist - please rebuild kernel with CONFIG_UPROBE_EVENTS., 说明不支持添加探针,无法使用此方法。 如果成功,会显示 Go 123456 Added new event: probe_libc:malloc (on malloc in /usr/lib64/libc-2.17.so) You can now use it in all perf tools, such as: perf record -e probe_libc:malloc -aR sleep 1可以使用事件 probe_libc:malloc 来跟踪 malloc 调用。 有时候我们没用标准库的内存函数,而是通过第三方库,比如 jemalloc, tcmalloc 等。这种方法也适用。以jemalloc 举例 Go 1234 ;; 确认包含 malloc 函数nm /opt/lib/libjemalloc.so.2 | grep malloc;; 增加探针sudo perf probe -x /opt/lib/libjemalloc.so.2 malloc成功后,生成新的事件 probe_libjemalloc:malloc 。依次执行下面命令生成火焰图 Go 1234 sudo perf record -F 99 -p -e probe_libjemalloc:malloc -a --call-graph dwarf sleep 30sudo perf script | ./stackcollapse-perf.pl > out.perf-folded ./flamegraph.pl --color=mem out.perf-folded > mem.svg brk,mmap 系统调用很多应用内存的增长通过调用底层系统函数 brk 或者 mmap 实现。brk 设置 heap 上边界位置,mmap 实现内存映射。一般小内存调用 brk, 大内存使用 mmap。可以使用下面查看系统上两个事件的调用情况 Go 1234567891011121314 sudo perf stat -e syscalls:sys_enter_brk,syscalls:sys_enter_mmap -a -I 1000# time counts unit events 1.000342206 187 syscalls:sys_enter_brk (100.00%) 1.000342206 937 syscalls:sys_enter_mmap 2.000725026 169 syscalls:sys_enter_brk 2.000725026 699 syscalls:sys_enter_mmap 3.001029115 246 syscalls:sys_enter_brk 3.001029115 1,067 syscalls:sys_enter_mmap 4.002700026 150 syscalls:sys_enter_brk 4.002700026 1,128 syscalls:sys_enter_mmap 5.003057782 105 syscalls:sys_enter_brk 5.003057782 771 syscalls:sys_enter_mmap 6.003359386 116 syscalls:sys_enter_brk 6.003359386 466 syscalls:sys_enter_mmap生成火焰图来查看 Go 123 sudo perf record -e syscalls:sys_enter_brk -a --call-graph dwarf sleep 20sudo perf script | ./stackcollapse-perf.pl > out.perf-folded./flamegraph.pl --color=mem out.perf-folded > mem.svg
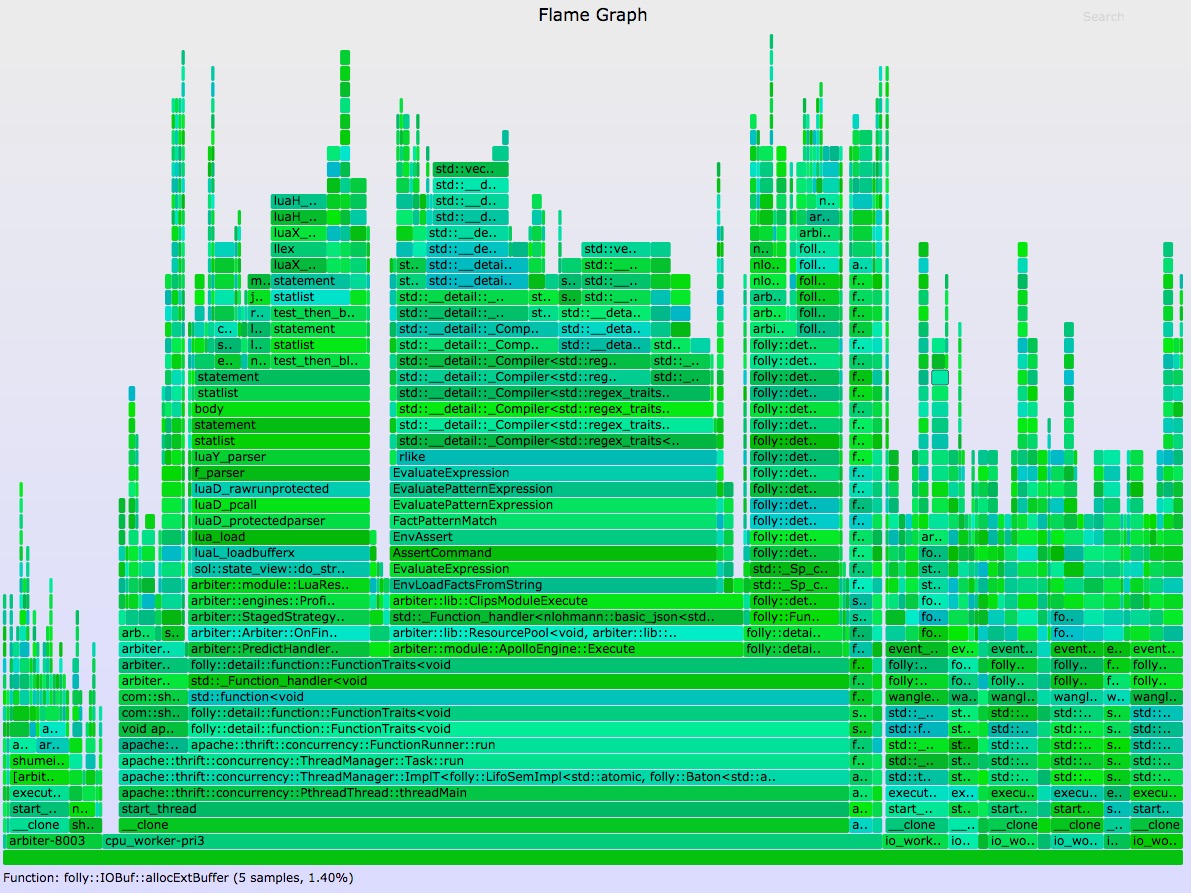
通过上面的火焰图可以看到 申请使用内存的热点路径 可能的内存泄露点,需要查看每个路径,并对应源码分析 使用 brk 可以看到当前堆的增长来源于哪里 可用内存的减少来源于哪里 page faults 事件brk 和 mmap 调用是显示了虚拟内存的增长,物理内存与虚拟内存的映射就产生了page faults 事件。page faults 是低频率的事件,使用 perf 分析的话开销是比较小的。 Go 123456789 sudo perf stat -e page-faults -a -I 1000# time counts unit events 1.000208143 57,579 page-faults 2.000447459 70,268 page-faults 3.000683302 86,734 page-faults 4.000914273 37,346 page-faults 5.001125391 83,286 page-faults 6.001341499 87,406 page-faults 7.001560936 68,948 page-faults可以对单个进程进行跟踪 Go 123 sudo perf record -p 13583 -e page-faults -a --call-graph dwarf sleep 30sudo perf script | ./stackcollapse-perf.pl > out.perf-folded./flamegraph.pl --color=mem out.perf-folded > mem.svg
可以看到 arbiter::module::ApolloEngine::Execute 产生的 page faults 比较多。 通过上面的火焰图可以看到 申请使用内存的热点路径 可能的内存泄露点,需要查看每个路径,并对应源码分析 总结本文提供了几种不同的工具对内存不同角度的分析,valgrind, heaptrack 只适合线下分析,perf 可以做线上内存分析。内存不止关注泄露,对内存性能的分析也不是容易的事情。有时候内存的增长可能并不是代码的问题,比如外部服务的不稳定,会引起自身数据内存的增长。 掌握内存的特点,并用合适的工具分析,可以快速的解决遇到的问题。 Related Postsstd::regex_replace 引起的core问题追踪记一次优化经历如何使用vpn区分公司内网和国内外网络GO 中的内联函数【面试】文件的相对路径问题 |
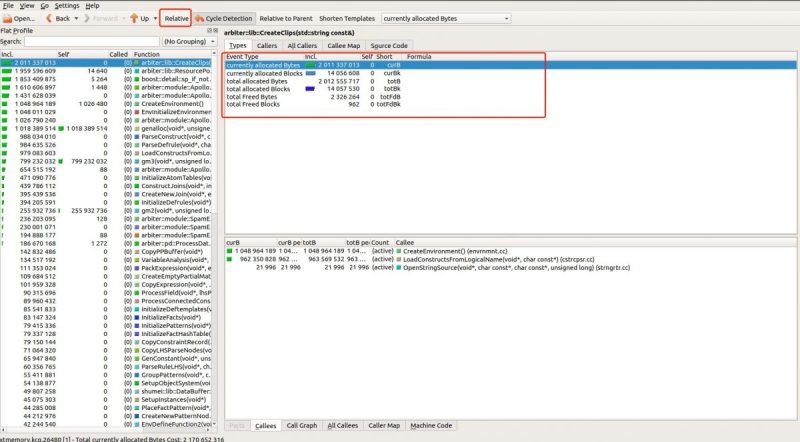 可以取消 Relative 选项,那么单位就是字节。可以从 Types 看到几种类型
可以取消 Relative 选项,那么单位就是字节。可以从 Types 看到几种类型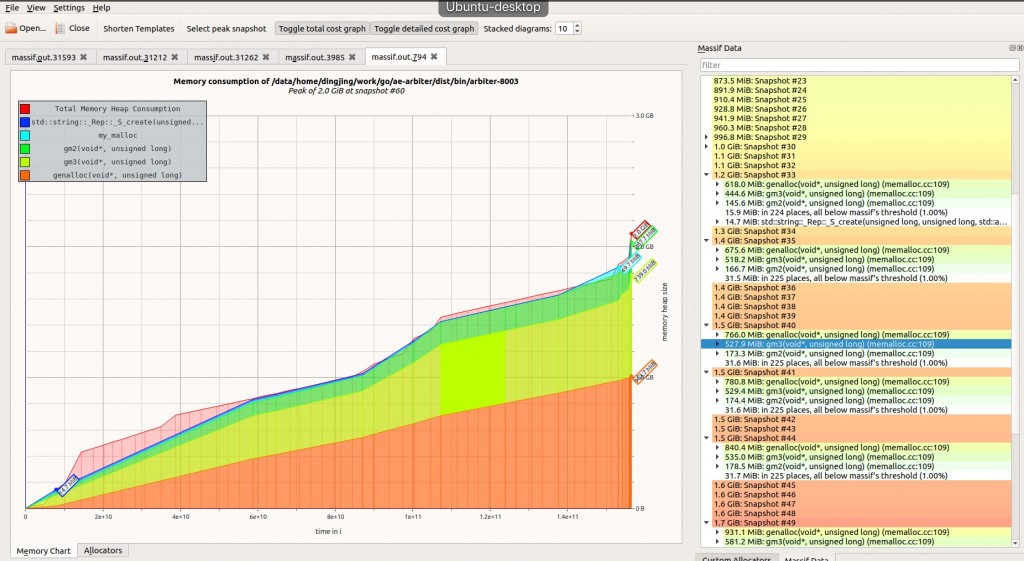
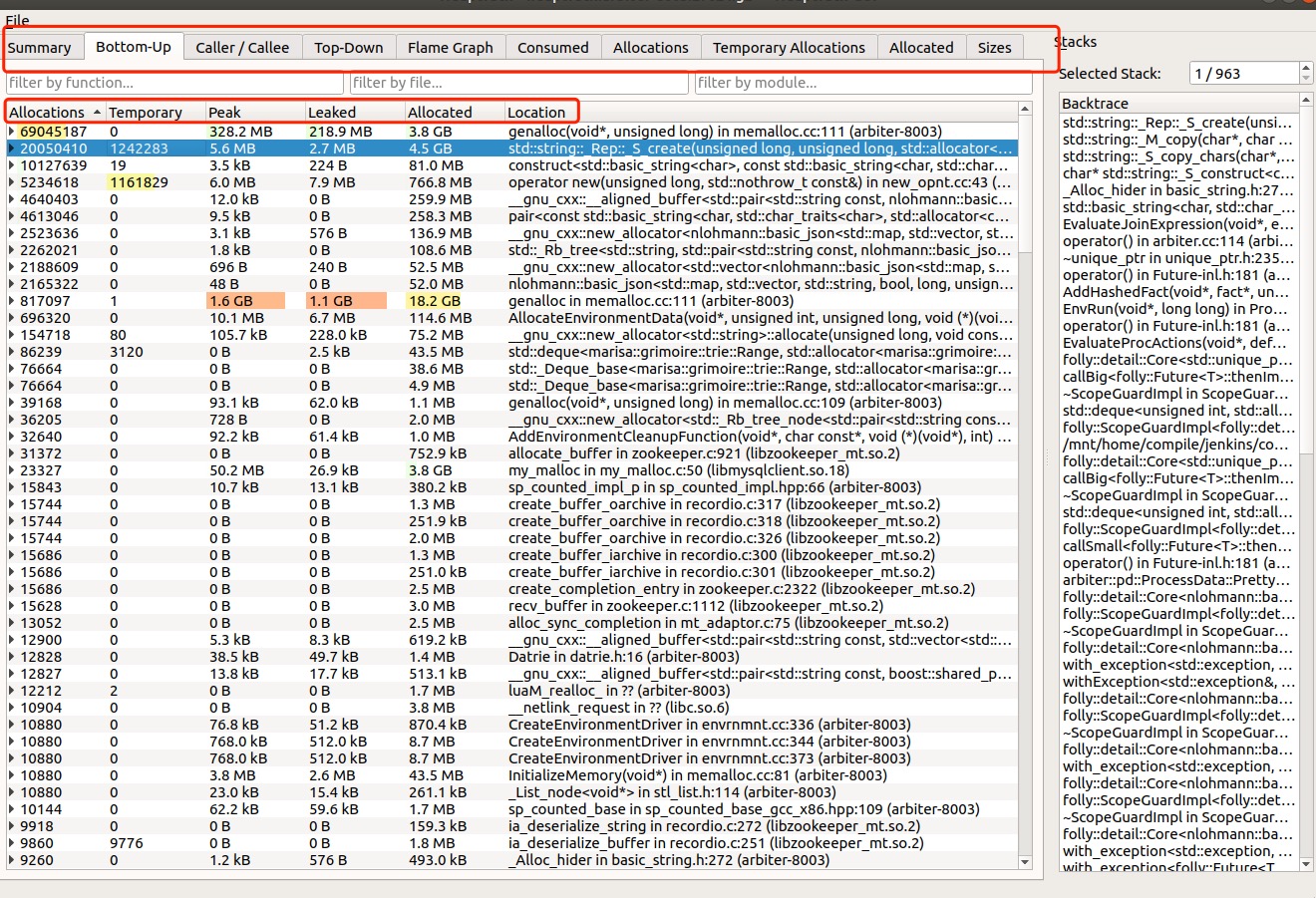
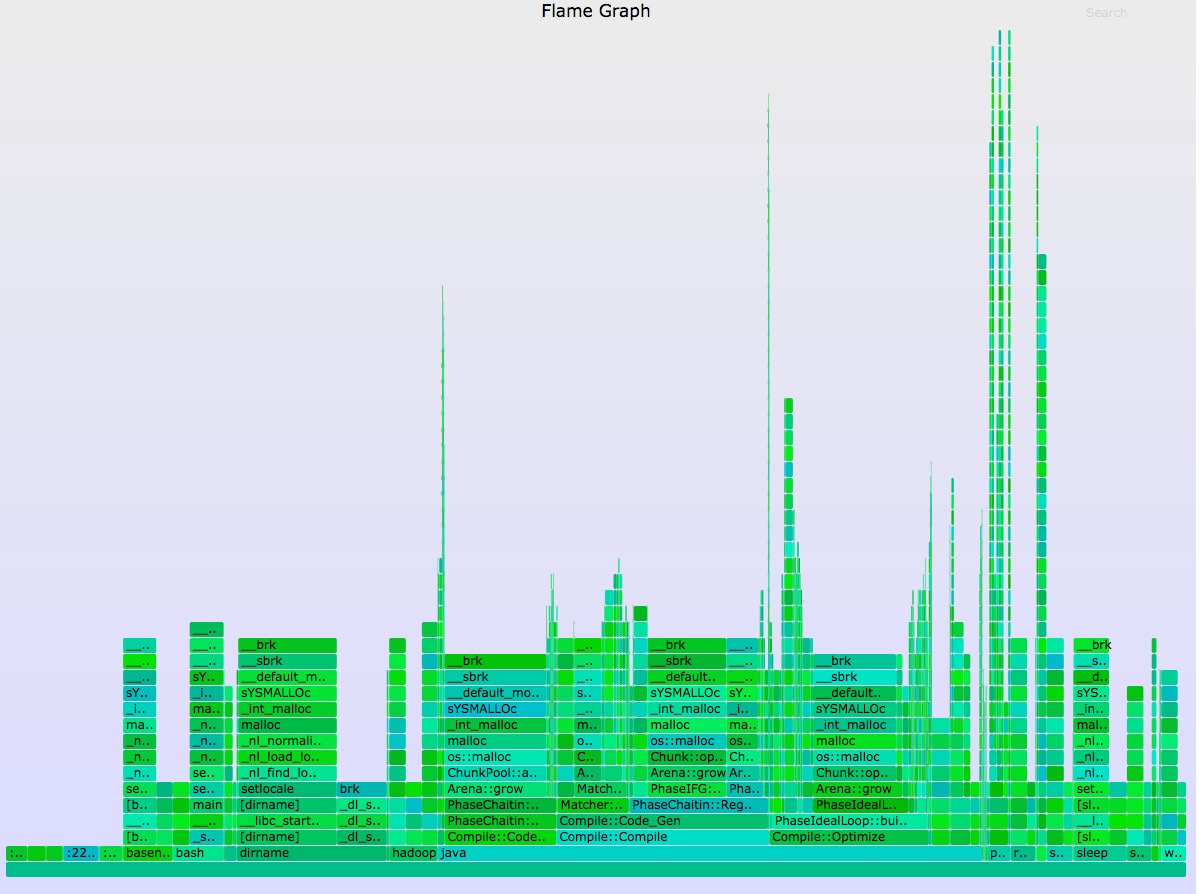
【本文地址】