| 如何利用 Sigil 和 EpubCheck 插件检查和修复 EPUB 文件 – 书伴 | 您所在的位置:网站首页 › pdf发送到kindle乱码 › 如何利用 Sigil 和 EpubCheck 插件检查和修复 EPUB 文件 – 书伴 |
如何利用 Sigil 和 EpubCheck 插件检查和修复 EPUB 文件 – 书伴

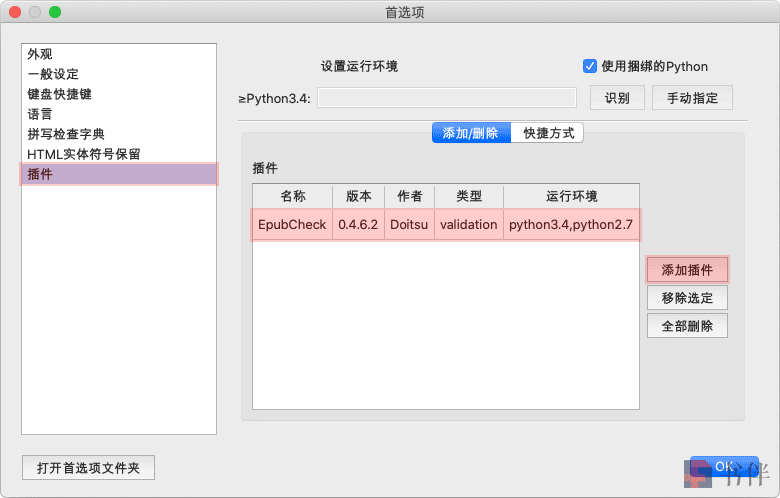
在如何快速修复推送失败的 EPUB 文件那篇文章的末尾,书伴推荐使用 Sigil + EpubCheck 插件这个软件组合自行检查其它可能导致 EPUB 文件推送失败的问题,但是有的小伙伴反馈不知道具体如何使用这个软件组合,因此本文就此需求更具体地介绍一下这对组合的使用方法。 使用 EpubCheck 插件的目的是找出所有可能导致 EPUB 文件推送失败的问题,以便用 Sigil 进行修复。导致 EPUB 推送失败的问题大多出在 content.opf 和 toc.ncx 这两个文件上,因此尽量根据验证结果中的提示信息进行修复,确保其不会出现与这两个文件相关的错误信息。 一、为 Sigil 安装 EpubCheck 插件首先需要确保你已经安装了 Sigil,通过下面提供的链接下载 EpubCheck 插件压缩包,依次点击 Sigil 菜单【Plugins(插件) → Manage Plugins(插件管理)】,在弹出对话框中点击【Add Plugin(添加插件)】,选择插件压缩包,点击【打开】按钮即可完成安装。 下载 EpubCheck 插件:官方发布页面插件安装成功后会出现在 Sigil 的插件列表中,如下图所示:
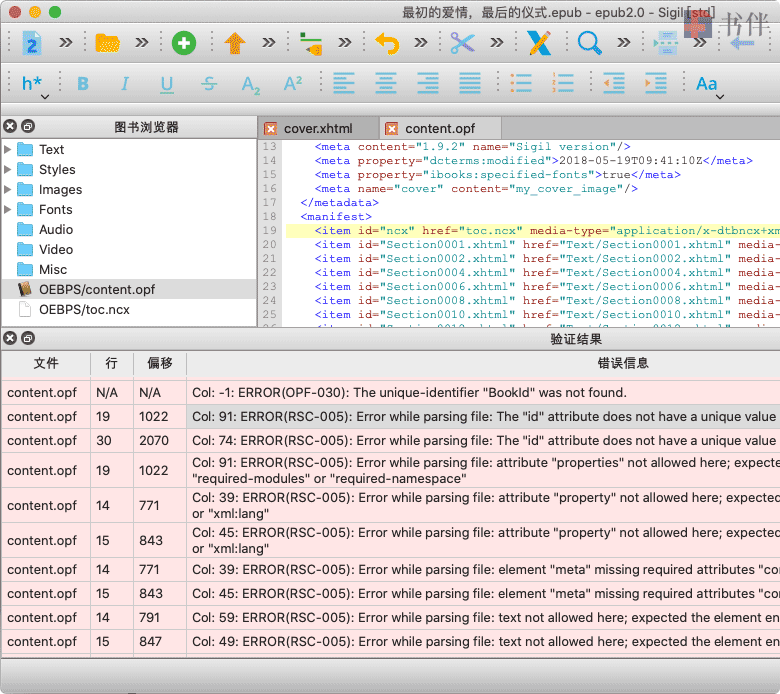
注意,运行 Sigil 的 EpubCheck 插件需要确保你的操作系统安装了 Java 环境,安装 JRE(Java Runtime Environment)或 JDK(Java Development Kit)均可。如果已安装可忽略此步骤,否则可在以下链接中任选其一下载安装。若非以 Java 开发为目的,推荐安装体积更小的 JRE。 JRE:官方下载页面 | 手动选择适用操作系统的版本 JDK(Standard Edition):官方下载页面 OpenJDK:官方下载页面* 提示:如果你使用的 Sigil 版本号小于 0.9.0,还需要确保你的操作系统安装了 Python 。 二、用 EpubCheck 插件验证 EPUB用 EpubCheck 插件验证 EPUB 的具体方法为:用 Sigil 打开 EPUB 文件,依次点击 Sigil 的菜单【插件(Plugins) → 有效性(Validation) → EpubCheck】即可对其进行检测。 待插件检查完毕后(时间长短因文件大小而异),会在 Sigil 界面下方弹出“验证结果”,结果中会列出当前 EPUB 文件所有违 EPUB 规范的地方,如下图所示:
验证结果会以表格的形式列出,每一行表示一个具体问题,你可以通过四个栏目查看某个问题的具体信息。这四个栏目的表头含义分别如下所示: 文件(File):问题涉及代码所在文件。 行(Line):问题涉及代码所在文件中的行号。如果值为 N/A 表示元素缺失。 偏移(Offset):问题涉及代码相对于所在文件中所有字符的偏移量。 错误信息(Message):问题涉及代码所在文件中的列号,以及导致该问题的具体提示。所幸,除了行号值为 N/A 的行,我们不必根据这些信息手动去查找问题涉及代码所在具体位置,只需要双击相应行就可以自动定位了。注意,有时可能多个行对应同一个问题。 对于行号值为 N/A 的行,表示文件中缺失某种 EPUB 规范中规定的必须存在的元素,你需要根据“错误信息”中给出的提示,参考 EPUB2 或 EPUB3 规范自行添加。不过通常这种问题不会影响推送,除非其它问题修复后仍然推送失败,否则可以暂时忽略这种问题。 * 提示:判断 EPUB 使用的是 EPUB2 规范还是 EPUB3 规范,可以通过其 OPF 文件中 元素的 version 属性值进行确认,如果该值是 2.0 说明是 EPUB2,如果是 3.0 就是 EPUB3。 如前文所述,大多数情况下最需要关注的是 content.opf 和 toc.ncx 这两个文件存在的问题,除非这两个文件修复完仍然推送失败,其它 CSS 或 XHTML 文件中出现的问题都不太会影响推送。 二、根据验证结果修复存在的问题通常 EpubCheck 给出的错误信息足以作为修复问题的线索。如果英文读起来吃力,可以单击某一行的“错误信息”栏,然后按快捷键 Ctrl + C 将相应的文本内容复制下来,就可以借助“Google 翻译”之类的翻译服务帮助理解了。下面举个例子来说明一下如何修复 EPUB 文件中存在错误。 假设验证某个 EPUB 文件得到如下所示结果,显示 content.opf 和 toc.ncx 文件存在一些问题: 验证结果 文件 行 偏移 错误信息 content.opf N/A N/A Col: -1: ERROR(OPF-030): The unique-identifier “BookId” was not found. content.opf 19 1022 Col: 91: ERROR(RSC-005): Error while parsing file: The “id” attribute does not have a unique value content.opf 30 2070 Col: 74: ERROR(RSC-005): Error while parsing file: The “id” attribute does not have a unique value content.opf 19 1022 Col: 91: ERROR(RSC-005): Error while parsing file: attribute “properties” not allowed here; expected attribute “fallback”, “fallback-style”, “required-modules” or “required-namespace” content.opf 14 771 Col: 39: ERROR(RSC-005): Error while parsing file: attribute “property” not allowed here; expected attribute “content”, “id”, “name”, “scheme” or “xml:lang” content.opf 14 771 Col: 39: ERROR(RSC-005): Error while parsing file: element “meta” missing required attributes “content” and “name” content.opf 14 791 Col: 59: ERROR(RSC-005): Error while parsing file: text not allowed here; expected the element end-tag toc.ncx N/A N/A Col: -1: ERROR(NCX-001): NCX identifier (“”) does not match OPF identifier (“9787532777686”).乍一看问题有很多,但是仔细分析就会发现,有很多行号是重复的,这就说明那一行中同时存在多种问题,有可能修复一处就能消除这些问题。下面我们就来逐个演示修复问题的思路。 表中第 1 行,即行号的值为 N/A 的那一行的错误信息示为:唯一标识符“BookID”未找到。 一般情况下这表示缺失了某个元素。根据 EPUB2 规范中的说明,OPF 文件中根元素 必须为其属性 unique-identifier 指定一个值,该值必须和元数据元素 的 id 属性值相同。但是在本例中,根元素 的 unique-identifier 属性值是 BookId,元素 的 id 属性值却是如下所示的 ISBN,因此出现了上述错误提示。 ... 9787532777686 ...分析出原因后,就可以如下所示按照 EPUB 规范修正这一行代码: ... 9787532777686 ...表中第 2、3 行的错误信息同为:“id”属性没有唯一值。这说明同一个 id 属性在两个元素中出现了两次,通过双击这两行定位到具体代码后可以发现,行号为 19 和 30 那两个元素不仅是 id 属性出现了重复,href 属性引用的资源也是重复的。而另一个行号为 19 的错误信息为:属性“properties”不允许出现在这里。这说明元素中出现了不该出现的 properties 属性。 ... ... ...分析出原因后,就可以对这两个元素去重,并去掉不应该出现在元素中的属性: ... ...提示:如果仅仅是元素的 id 属性出现了重复,而 href 属性指向的资源没有重复,只需要将 id 的属性值改成不相同的即可。如果是 href 属性指向的资源是重复的,就不用管 id 是否重复,直接去重即可。 表中第 5、6、7 行的错误信息同时出现在行号 14 上,分别为:属性“property”不允许出现在这里、元素“meta”缺失属性“content”和“name”、文本不允许出现在这里;预期的是元素结束标签。这些错误表明,电子书的制作者将 EPUB3 的规范用在了 EPUB2 上,错误地使用了 元素,在 EPUB2 规范中该元素类似于 XHTML 1.1 规范中的 元素,这是一个不能包含文本的空元素,在 EPUB2 中通常会使用 name 和 content 这两个属性。 ... 2018-05-19T09:41:10Z ...EPUB2 规范中显示 元素是可选的,因此,方便起见,你可以直接将这行代码删除。如果由于某种原因需要保留此元数据,需要更改成如下所示符合 EPUB2 规范的形式: ... ...表中最后一行的错误来自 toc.ncx 文件,错误信息为:NCX 标识符(“”)与 OPF 标识符(“9787532777686”)不匹配。根据 EPUB2 规范中的说明,NCX 文件中必须包含一个 元素,其 name 属性值为 dtb:id,content 属性值要引用 OPF 中 identifier 元素的值。而在本例中,NCX 文件中 元素的 content 属性值却为空,因此出现了上述错误提示。 ... ...解决方法很简单,直接将 OPF 文件中元数据元素 identifier 的值拷贝过来即可: ... ...至此,示例中 content.opf 和 toc.ncx 这两个文件存在的所有错误就修复完成了。当然并非所有错误都会导致推送失败,比如上面这个例子中,导致推送失败的是表中的第 2、3、4 条错误,其它的其实并不影响推送,但是如果不是太难解决,还是建议一次性解决,以避免重复测试推送。 上面这些对 EPUB 文件的修复操作仅提供一种解决问题的思路,并不能覆盖所有 EPUB 文件中可能出现的错误,你可以参照这些思路,尝试解决你遇到的具体问题。书伴总结了一些推送 EPUB 文件时出现频率较高推送失败原因可供参考,同时欢迎留言分享你的经验。 © 「书伴」原创文章,转载请注明出处及原文链接:https://bookfere.com/post/1004.html |
【本文地址】