| 关于数据库以及mysql的一些总结 | 您所在的位置:网站首页 › panel和pool的区别 › 关于数据库以及mysql的一些总结 |
关于数据库以及mysql的一些总结
|
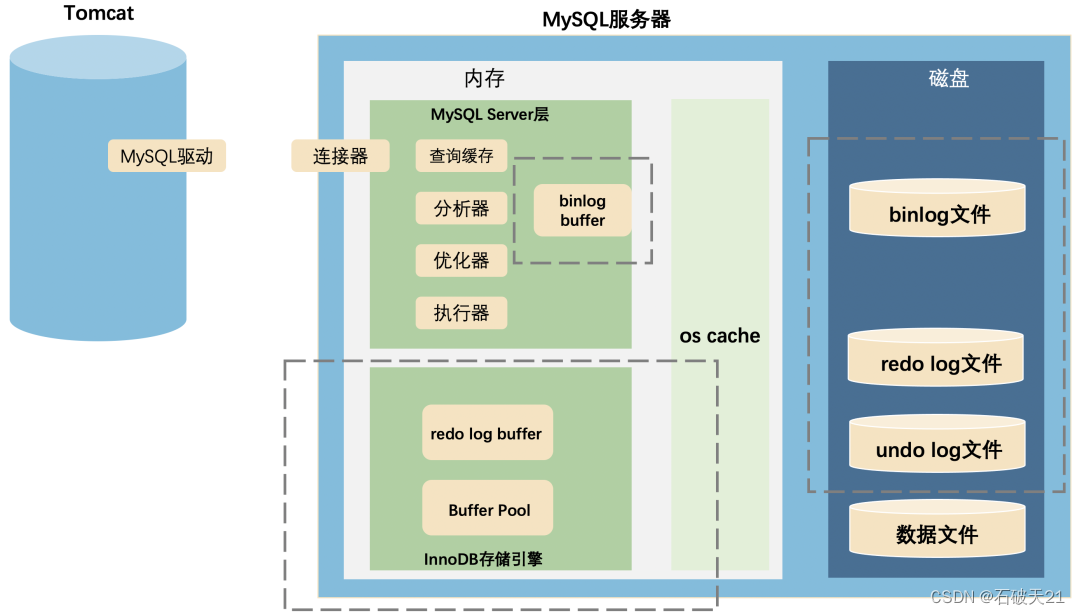
数据库的核心语言就是SQL语言,那 DDL、DML、DQL、DCL 1、DDL(Data Definition Language)语句: 数据定义语言,主要是进行定义/改变表的结构、数据类型、表之间的链接等操作。常用的语句关键字有 CREATE、DROP、ALTER 等。 2、DML(Data Manipulation Language)语句: 数据操纵语言,主要是对数据进行增加、删除、修改操作。常用的语句关键字有 INSERT、UPDATE、DELETE 等。 3、DQL(Data Query Language)语句:数据查询语言,主要是对数据进行查询操作。常用关键字有 SELECT、FROM、WHERE 等。 4、DCL(Data Control Language)语句: 数据控制语言,主要是用来设置/更改数据库用户权限。常用关键字有 GRANT、REVOKE 等。一般人员很少用到DCL语句。 Mysql分为Server层和存储引擎层。 InnoDB中的bufferPool大大减少了mysql操作磁盘IO的次数。 Mysql中的redo log、undo log以及binlog的区别: Buffer Pool是MySQL进程管理的一块内存空间,有减少磁盘IO次数的作用。 redo log是InnoDB存储引擎的一种日志,记录修改后的数据,主要作用是崩溃恢复,有三种刷盘策略,有innodb_flush_log_at_trx_commit 参数控制,推荐设置成2。 注: innodb_flush_log_at_trx_commit = 1:实时写,实时刷 innodb_flush_log_at_trx_commit = 0:延迟写,延迟刷 innodb_flush_log_at_trx_commit = 2:实时写,延迟刷 undo log是InnoDB存储引擎的一种日志,记录修改前的数据,主要作用是回滚。binlog是MySQL Server层的一种日志,记录修改过程以及修改后的数据,主要作用是归档。注:和redo log日志类似,binlog也有着自己的刷盘策略,通过sync_binlog参数控制:①sync_binlog = 0 :每次提交事务前将binlog写入os cache,由操作系统控制什么时候刷到磁盘;②sync_binlog =1 :采用同步写磁盘的方式来写binlog,不使用os cache来写binlog;③sync_binlog = N :当每进行n次事务提交之后,调用一次fsync将os cache中的binlog强制刷到磁盘。显然,sync_binlog为1是最安全的,每次提交事务就将binlog写入磁盘,数据一致性最好。但实际情况中,往往为了提高数据库的性能,会将sync_binlog适当设大,来减少磁盘IO次数,用数据一致性换性能。在对数据库一致性要求不高或数据没那么重要的业务场景,完全可以把sync_binlog设置在100~1000范围内的某个值,以此来提高数据库的性能。而在对数据一致性要求高的业务场景或特别重要的数据,比如订单则建议将sync_binlog的值设置为1,这样可以保证哪怕数据库挂了也不会丢失数据。 MySQL挂了有两种情况:操作系统挂了MySQL进程跟着挂了;操作系统没挂,但是MySQL进程挂了。 redo log与bin log的区别: binlog是逻辑日志,记录的是对哪一个表的哪一行做了什么修改;redo log是物理日志,记录的是对哪个数据页中的哪个记录做了什么修改,如果你还不了解数据页,你可以理解成对磁盘上的哪个数据做了修改。 binlog是追加写;redo log是循环写,日志文件有固定大小,会覆盖之前的数据。 binlog是Server层的日志;redo log是InnoDB的日志。如果不使用InnoDB引擎,是没有redo log的。
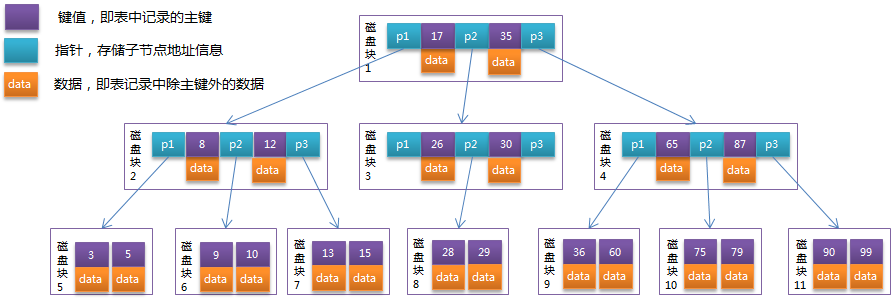
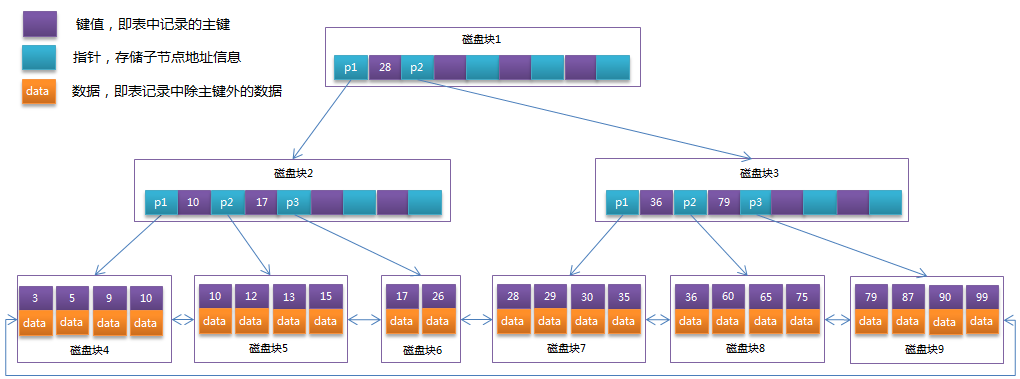
Binlog日志的三种模式 1、statement level模式:每一条修改数据的sql都会记录到master的bin_log中 优点:statement level下的优点首先就是解决了row level下的缺点,不需要记录每一行的变化,较少bin-log日志量,节约IO,提高性能。 缺点:没有记录每一行的变化,一些新功能同步可能会有障碍,比如函数、触发器等。 2、row level模式:日志中会记录成每一行数据修改的形式 优点:记录哪一条记录被修改,修改成什么样。所以row level的日志内容会非常清楚的记录每一行数据修改的细节,非常容易理解。而且不会出现某些特定情况下的存储过程,或fuction,以及trigger的调用或处罚无法被正确复制的问题。 缺点:产生大量的记录日志 3、Mixed模式(混合模式):以上两种模式的混合 B+Tree相对于B-Tree有几点不同: 非叶子节点只存储键值信息。(注:叶子节点即没有后续分支的节点)所有叶子节点之间都有一个链指针。数据记录都存放在叶子节点中。B-Tree图: B+Tree图: 面对大数据量时,B-Tree的高度会很大,B+Tree的高度一般都在2~4层。mysql的InnoDB存储引擎在设计时是将根节点常驻内存的,也就是说查找某一键值的行记录时最多只需要1~3次磁盘I/O操作。 数据库中的B+Tree索引可以分为聚集索引(clustered index)和辅助索引(secondary index)。上面的B+Tree示例图在数据库中的实现即为聚集索引,聚集索引的B+Tree中的叶子节点存放的是整张表的行记录数据。辅助索引与聚集索引的区别在于辅助索引的叶子节点并不包含行记录的全部数据,而是存储相应行数据的聚集索引键,即主键。当通过辅助索引来查询数据时,InnoDB存储引擎会遍历辅助索引找到主键,然后再通过主键在聚集索引中找到完整的行记录数据。 聚簇索引并不是一种单独的索引类型,而是一种数据存储方式。是基于B+Tree实现的。 Innobd中的主键索引是一种聚簇索引,非聚簇索引都是辅助索引,像复合索引、前缀索引、唯一索引。 Innodb使用的是聚簇索引,MyISam使用的是非聚簇索引,MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。MyISam的B+Tree结构的叶子节点的data存放的是数据记录的地址,Innodb的B+Tree结构的叶子节点的data存放的是整条row具体数据 |
【本文地址】