| 高效的10个Pandas函数,你都用过了吗? | 您所在的位置:网站首页 › pandas选取两列 › 高效的10个Pandas函数,你都用过了吗? |
高效的10个Pandas函数,你都用过了吗?
|
文章来源:towardsdatascience作者:Soner Yıldırım翻译\编辑:Python大数据分析 Pandas是python中最主要的数据分析库之一,它提供了非常多的函数、方法,可以高效地处理并分析数据。让pandas如此受欢迎的原因是它简洁、灵活、功能强大的语法。 这篇文章将会配合实例,讲解20个重要的pandas函数。其中有一些很常用,相信你可能用到过。还有一些函数出现的频率没那么高,但它们同样是分析数据的得力帮手。 介绍这些函数之前,第一步先要导入pandas和numpy。 import numpy as np import pandas as pd 1. QueryQuery是pandas的过滤查询函数,使用布尔表达式来查询DataFrame的列,就是说按照列的规则进行过滤操作。 用法: pandas.DataFrame.query(self, expr, inplace = False, **kwargs)参数作用: expr:要评估的查询字符串;inplace=False:查询是应该修改数据还是返回修改后的副本kwargs:dict关键字参数首先生成一段df: values_1 = np.random.randint(10, size=10) values_2 = np.random.randint(10, size=10) years = np.arange(2010,2020) groups = ['A','A','B','A','B','B','C','A','C','C'] df = pd.DataFrame({'group':groups, 'year':years, 'value_1':values_1, 'value_2':values_2}) df 过滤查询用起来比较简单,比如要查列value_1=2016的行记录: df.query('year >= 2016 ')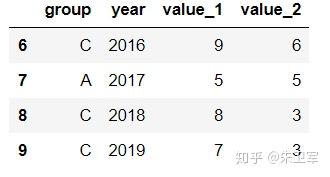 2. Insert 2. InsertInsert用于在DataFrame的指定位置中插入新的数据列。默认情况下新列是添加到末尾的,但可以更改位置参数,将新列添加到任何位置。 用法: Dataframe.insert(loc, column, value, allow_duplicates=False)参数作用: loc: int型,表示插入位置在第几列;若在第一列插入数据,则 loc=0column: 给插入的列取名,如 column='新的一列'value:新列的值,数字、array、series等都可以allow_duplicates: 是否允许列名重复,选择Ture表示允许新的列名与已存在的列名重复接着用前面的df:  在第三列的位置插入新列: #新列的值 new_col = np.random.randn(10) #在第三列位置插入新列,从0开始计算 df.insert(2, 'new_col', new_col) df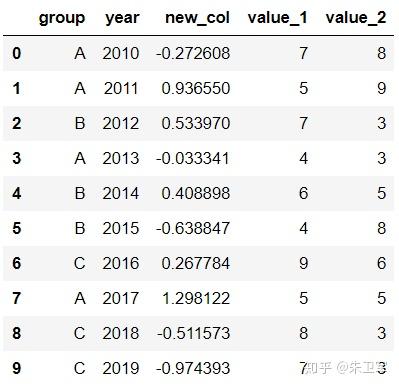 3. Cumsum 3. CumsumCumsum是pandas的累加函数,用来求列的累加值。 用法: DataFrame.cumsum(axis=None, skipna=True, args, kwargs)参数作用: axis:index或者轴的名字skipna:排除NA/null值以前面的df为例,group列有A、B、C三组,year列有多个年份。我们只知道当年度的值value_1、value_2,现在求group分组下的累计值,比如A、2014之前的累计值,可以用cumsum函数来实现。 当然仅用cumsum函数没办法对groups (A, B, C)进行区分,所以需要结合分组函数groupby分别对(A, B, C)进行值的累加。 df['cumsum_2'] = df[['value_2','group']].groupby('group').cumsum() df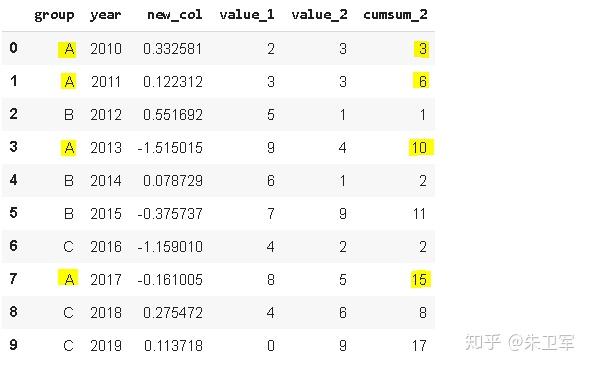 4. Sample 4. SampleSample用于从DataFrame中随机选取若干个行或列。 用法: DataFrame.sample(n=None, frac=None, replace=False, weights=None, random_state=None, axis=None)参数作用: n:要抽取的行数frac:抽取行的比例 例如frac=0.8,就是抽取其中80%replace:是否为有放回抽样, True:有放回抽样 False:未放回抽样weights:字符索引或概率数组random_state :随机数发生器种子axis:选择抽取数据的行还是列 axis=0:抽取行 axis=1:抽取列比如要从df中随机抽取5行: sample1 = df.sample(n=5) sample1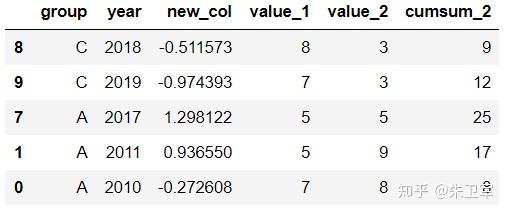 从df随机抽取60%的行,并且设置随机数种子,每次能抽取到一样的样本: sample2 = df.sample(frac=0.6,random_state=2) sample2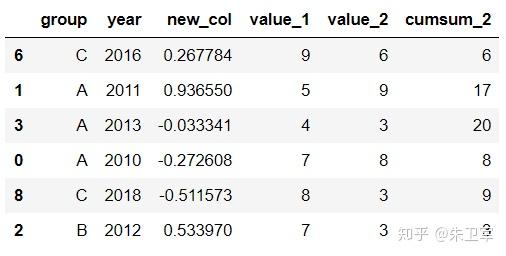 5. Where 5. WhereWhere用来根据条件替换行或列中的值。如果满足条件,保持原来的值,不满足条件则替换为其他值。默认替换为NaN,也可以指定特殊值。 用法: DataFrame.where(cond, other=nan, inplace=False, axis=None, level=None, errors='raise', try_cast=False, raise_on_error=None)参数作用: cond:布尔条件,如果 cond 为真,保持原来的值,否则替换为otherother:替换的特殊值inplace:inplace为真则在原数据上操作,为False则在原数据的copy上操作axis:行或列将df中列value_1里小于5的值替换为0: df['value_1'].where(df['value_1'] > 5 , 0) Where是一种掩码操作。 「掩码」(英语:Mask)在计算机学科及数字逻辑中指的是一串二进制数字,通过与目标数字的按位操作,达到屏蔽指定位而实现需求。 6. IsinIsin也是一种过滤方法,用于查看某列中是否包含某个字符串,返回值为布尔Series,来表明每一行的情况。 用法: Series.isin(values) 或者 DataFrame.isin(values)筛选df中year列值在['2010','2014','2017']里的行: years = ['2010','2014','2017'] df[df.year.isin(years)]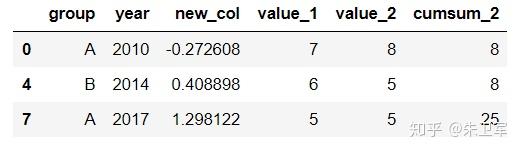 7. Loc and iloc 7. Loc and ilocLoc和iloc通常被用来选择行和列,它们的功能相似,但用法是有区别的。 用法: DataFrame.loc[] 或者 DataFrame.iloc[] loc:按标签(column和index)选择行和列iloc:按索引位置选择行和列选择df第1~3行、第1~2列的数据,使用iloc: df.iloc[:3,:2]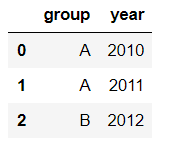 使用loc: df.loc[:2,['group','year']]1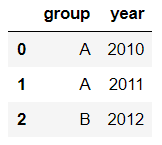 提示:使用loc时,索引是指index值,包括上边界。iloc索引是指行的位置,不包括上边界。 选择第1、3、5行,year和value_1列: df.loc[[1,3,5],['year','value_1']]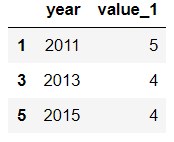 8. Pct_change 8. Pct_changePct_change是一个统计函数,用于表示当前元素与前面元素的相差百分比,两元素的区间可以调整。 比如说给定三个元素[2,3,6],计算相差百分比后得到[NaN, 0.5, 1.0],从第一个元素到第二个元素增加50%,从第二个元素到第三个元素增加100%。 用法: DataFrame.pct_change(periods=1, fill_method=‘pad’, limit=None, freq=None, **kwargs)参数作用: periods:间隔区间,即步长fill_method:处理空值的方法对df的value_1列进行增长率的计算: df.value_1.pct_change()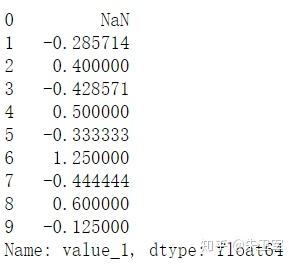 9. Rank 9. RankRank是一个排名函数,按照规则(从大到小,从小到大)给原序列的值进行排名,返回的是排名后的名次。 比如有一个序列[1,7,5,3],使用rank从小到大排名后,返回[1,4,3,2],这就是前面那个序列每个值的排名位置。 用法: rank(axis=0, method: str = 'average', numeric_only: Union[bool, NoneType] = None, na_option: str = 'keep', ascending: bool = True, pct: bool = False)参数作用: axis:行或者列method:返回名次的方式,可选{‘average’, ‘min’, ‘max’, ‘first’, ‘dense’}method=average 默认设置: 相同的值占据前两名,分不出谁是1谁是2,那么去中值即1.5,下面一名为第三名method=max: 两人并列第 2 名,下一个人是第 3 名method=min: 两人并列第 1 名,下一个人是第 3 名method=dense: 两人并列第1名,下一个人是第 2 名method=first: 相同值会按照其在序列中的相对位置定值ascending:正序和倒序对df中列value_1进行排名: df['rank_1'] = df['value_1'].rank() df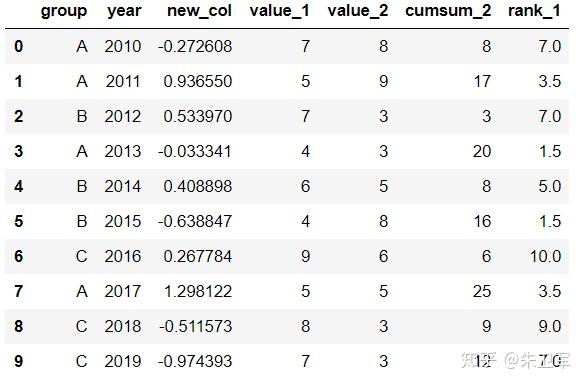 10. Melt 10. MeltMelt用于将宽表变成窄表,是 pivot透视逆转操作函数,将列名转换为列数据(columns name → column values),重构DataFrame。 简单说就是将指定的列放到铺开放到行上变成两列,类别是variable(可指定)列,值是value(可指定)列。 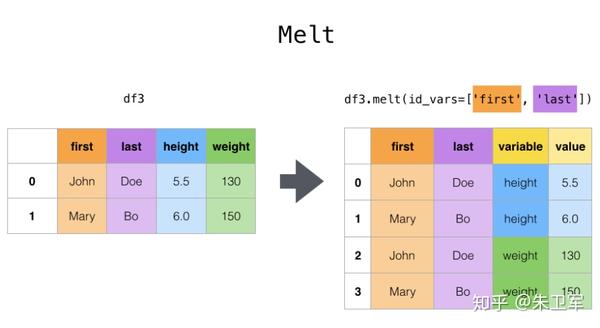 用法: pandas.melt(frame, id_vars=None, value_vars=None, var_name=None, value_name='value', col_level=None)参数作用: frame:它是指DataFrameid_vars [元组, 列表或ndarray, 可选]:不需要被转换的列名,引用用作标识符变量的列value_vars [元组, 列表或ndarray, 可选]:引用要取消透视的列。如果未指定, 请使用未设置为id_vars的所有列var_name [scalar]:指代用于”变量”列的名称。如果为None, 则使用- - frame.columns.name或’variable’value_name [标量, 默认为’value’]:是指用于” value”列的名称col_level [int或string, 可选]:如果列为MultiIndex, 它将使用此级别来融化例如有一串数据,表示不同城市和每天的人口流动: import pandas as pd df1 = pd.DataFrame({'city': {0: 'a', 1: 'b', 2: 'c'}, 'day1': {0: 1, 1: 3, 2: 5}, 'day2': {0: 2, 1: 4, 2: 6}}) df1 现在将day1、day2列变成变量列,再加一个值列: pd.melt(df1, id_vars=['city']) 推荐两本超级优秀的python入门书籍 |
【本文地址】