| pandas读写Excel详解 | 您所在的位置:网站首页 › pandas编辑excel › pandas读写Excel详解 |
pandas读写Excel详解
|
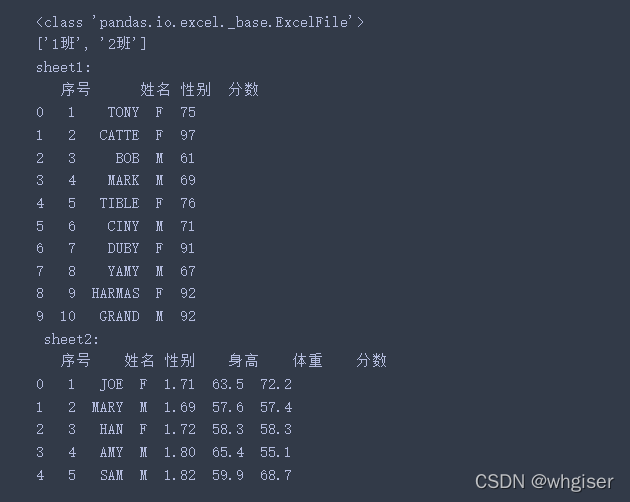
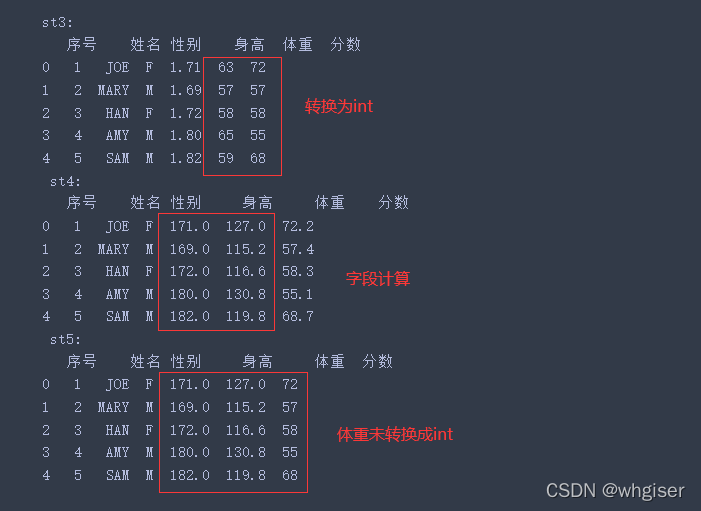
本文为作者原创,转载请注明 文章目录 一、Excel读取1. ExcelFile类2. read_excel()方法 二、Excel写入1. 写入Excel2. 已有Excel增加sheet3. 覆盖Excel中已有sheet4. 已有sheet中追加数据 一、Excel读取Excel的读取可以采用ExcelFile类和read_excel两种方法,在实际使用中差别不大。其区别可以见e-learn上贴子讨论,观点摘录如下: 除了语法之外没有特别的区别。从技术上讲,ExcelFile是一个类,read_excel是一个函数。在任何一种情况下,实际都是由定义在ExcelFile的_parse_excel解析ExcelFile.parse循环速度更快(存疑) 1. ExcelFile类类的定义和方法参数感兴趣的可以查看源码 ExcelFile.parse(sheet_name=0, header=0, names=None, index_col=None, usecols=None, squeeze=None, converters=None, true_values=None, false_values=None, skiprows=None, nrows=None, na_values=None, parse_dates=False, date_parser=None, thousands=None, comment=None, skipfooter=0, convert_float=None, mangle_dupe_cols=True, **kwds) import pandas as pd table = pd.ExcelFile('./data/table1.xlsx') print(type(table)) print(table.sheet_names) ##按顺序获取sheet名称 ## 提取表格信息 sheet1 = table.parse(sheet_name=0) #可以使用序号,一次性读取多个用列表[0,1] sheet2 = table.parse(sheet_name=table.sheet_names[1]) #也可以使用sheet名 print('sheet1:\n{0}\n sheet2:\n{1}'.format(sheet1,sheet2))输出结果如下: pandas.read_excel(io, sheet_name=0, header=0, names=None, index_col=None, usecols=None, squeeze=None, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skiprows=None, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, parse_dates=False, date_parser=None, thousands=None, decimal=’.’, comment=None, skipfooter=0, convert_float=None, mangle_dupe_cols=True, storage_options=None) 主要参数解释io文件路径sheet_namesheet名称,可以是数字或sheet名,默认‘sheet1 ’header指定标题行,默认第一行为标题,可以设置多行如[0,1]为标题行names在header=None的前提下,补充列名index_col用于指定索引,默认为None,设置多列索引index_col=[0,1]usecols用于指定读取的列,默认为None,读取第2-4列usecols = [1,2,3]engine“xlrd”支持.xls,“openpyxl”支持.xlsxdtype指定数据列的类型,如{‘a’: np.float64, ‘b’: str}converters转换指定列的函数字典{“A”:lambda x: x/100,“B”:lambda x: x/100}skiprows省略指定行数的数据,从第一行开始skipfooter省略指定行数的数据,是从尾部数的行开始示例如下: ##可以逐个sheet读取,也可以一次读取 st1 = pd.read_excel('./data/table1.xlsx',sheet_name='1班') st2 = pd.read_excel('./data/table1.xlsx',sheet_name='2班') table = pd.read_excel('./data/table1.xlsx',sheet_name=[0,1]) ## 一次性读取 st1 = table[0],st2 = table[1] print('st1:\n{0}\n st2:\n{1}'.format(st1,st2)) #与上面输出结果相同使用其他参数 st3 = pd.read_excel('./data/table1.xlsx',sheet_name=1,dtype={'体重': int,'分数': float}) st4 = pd.read_excel('./data/table1.xlsx',sheet_name=1,converters={'身高':lambda x:x*100,'体重':lambda x:x*2}) #Both a converter and dtype were specified for column 体重 - only the converter will be used st5 = pd.read_excel('./data/table1.xlsx',sheet_name=1,dtype={'体重': int,'分数': float},converters={'身高':lambda x:x*100,'体重':lambda x:x*2}) print('st3:\n{0}\n st4:\n{1}\n st5:\n{2}'.format(st3,st4,st5))注意:对某一列同时使用dtype和converters,仅仅converter被有效使用 有两种方法可以进行写入,使用to_excel方法和ExcelWriter类,如要写入到一个文件中多个sheet,需要使用ExcelWriter类。 ExcelWriter定义如下: class pandas.ExcelWriter(path, engine=None, date_format=None, datetime_format=None, mode=‘w’, storage_options=None, if_sheet_exists=None, engine_kwargs=None, **kwargs) to_excel方法: DataFrame.to_excel(excel_writer, sheet_name=‘Sheet1’, na_rep=’’, float_format=None, columns=None, header=True, index=True, index_label=None, startrow=0, startcol=0, engine=None, merge_cells=True, encoding=None, inf_rep=‘inf’, verbose=True, freeze_panes=None, storage_options=None) ExcelWriter()可以向同一个excel的不同sheet中写入对应的表格数据 代码如下(示例): #使用pd.to_excel方法 st5.to_excel('./data/table2.xlsx',sheet_name='newSheet')ExcelWriter类写入流程:基于已创建的writer对象,利用to_excel()方法将不同的dataframe及其对应的sheet名称写入该writer对象中,并在全部表格写入完成之后,使用save()方法来执行writer中内容向对应实体excel文件写入数据的过程 同python文件IO一样,有两种写入方式。writer应该作为上下文管理器,否则,需要调用close() 保持和关闭打开的文件句柄 第一种: writer = pd.ExcelWriter('./data/table3.xlsx') st4.to_excel(writer,sheet_name='st4',index=False) st5.to_excel(writer,sheet_name='st5',index=False) ##数据写出到excel文件中 writer.save()第二种: with pd.ExcelWriter('./data/table4.xlsx') as writer: st4.to_excel(writer, sheet_name='st4',index=False) st5.to_excel(writer, sheet_name='st5',index=False) 2. 已有Excel增加sheetmode分为两种写入’w’和追加‘a’,在已有表格中增加sheet使用‘a’模式,指定写入的sheet名称,代码如下(示例): with pd.ExcelWriter('./data/table4.xlsx',mode='a',engine='openpyxl') as writer: st3.to_excel(writer, sheet_name='st3',index=False) 3. 覆盖Excel中已有sheet如果需要重新写入Excel中某个sheet,直接往Excel写入同名sheet不会覆盖,而是创建一个新的表单(sheet1),需要采用以下方法 with pd.ExcelWriter('./data/table4.xlsx',mode='a',engine='openpyxl') as writer: wb = writer.book # openpyxl.workbook.workbook.Workbook 获取所有sheet wb.remove(wb['st3']) #删除需要覆盖的sheet st1.to_excel(writer, sheet_name='st3',index=False) ##sheet st3的内容更新成st1值 4. 已有sheet中追加数据读取原表格的Workbook和sheets,赋给writer句柄,保证数据内容的一致。获取拟写入表单的数据行数,从下一行开始写入,需要设置header = False import pandas as pd from openpyxl import load_workbook newdata = pd.DataFrame([('6','LUCY','F',190,135,90),('7','ROB','M',181,145,78),('8','FRADI','M',176,133,80)])#需要新写入的数据 df = pd.read_excel('./data/table4.xlsx',sheet_name='st4') #读取原数据文件和表 writer = pd.ExcelWriter('./data/table4.xlsx',engine='openpyxl') book = load_workbook('./data/table4.xlsx') writer.book = book # openpyxl.workbook.workbook.Workbook writer.sheets = dict((ws.title, ws) for ws in book.worksheets) #{'st4': , 'st5': , 'st3': } df_rows = df.shape[0] #获取原数据的行数 newdata.to_excel(writer, sheet_name='st4',startrow = df_rows + 1, index = False, header = False)#将数据写入excel中的st3,从第一个空行开始写 writer.save()#保存 |
【本文地址】