| python | 您所在的位置:网站首页 › pandas索引器 › python |
python
DataFrame索引
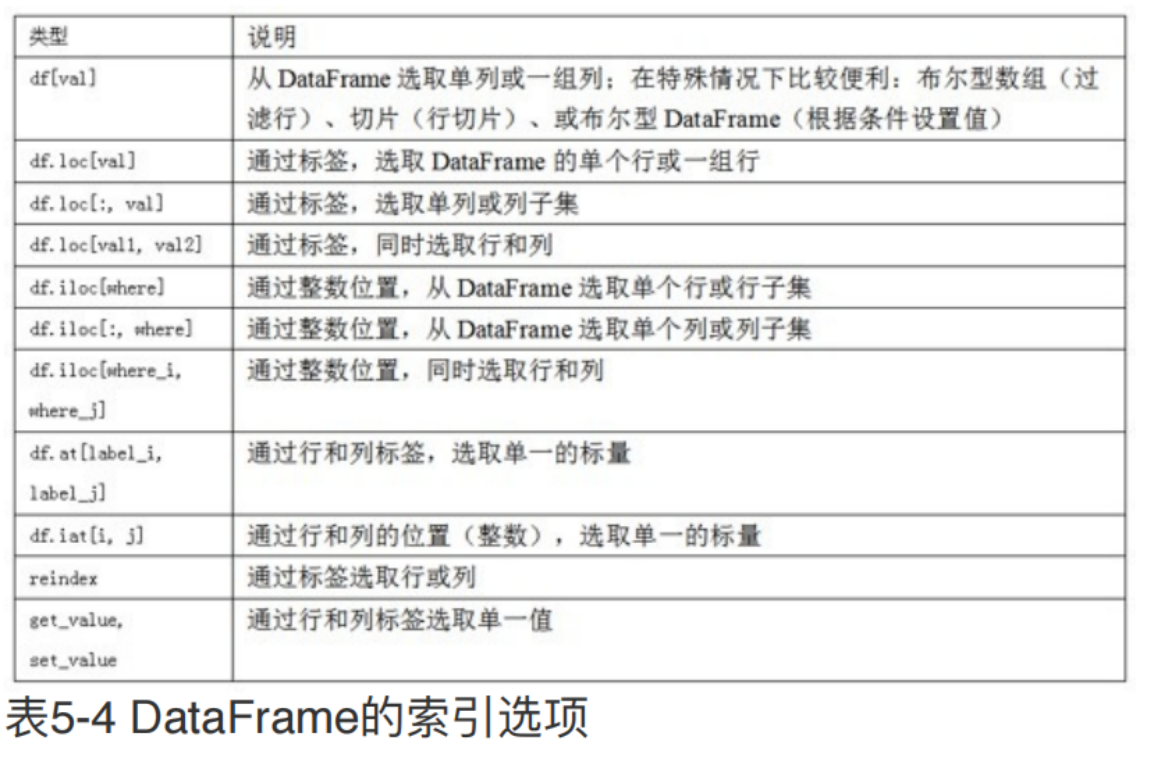 index方法和属性
index方法和属性
 data.columns.get_indexer(['第一列','第二列']):DataFrame中取得列索引位置
get_dummies函数
data.columns.get_indexer(['第一列','第二列']):DataFrame中取得列索引位置
get_dummies函数
如果DataFrame的某一列中含有k个不同的值,则可以派生出一个k列矩阵或DataFrame(其值全为1和0)。pandas有一个get_dummies函数可以实现该功能 df = pd.DataFrame({'key': ['b', 'b', 'a', 'c', 'a', 'b'],'data1': range(6)}) pd.get_dummies(df['key']) Dataframe.add_prefix('自定义前缀名')函数可以与系列以及数据帧一起使用。对于Series,行标签带有前缀。 对于DataFrame,列标签带有前缀。 离散化和面元划分(cut&qcut)qcut/cut(数据数组,面元数组) 根据数据的分布情况,cut可能⽆法使各个⾯元 中含有相同数量的数据点。⽽qcut由于使⽤的是样本分位数,因 此可以得到⼤⼩基本相等的⾯元 层次化索引(Series多个索引)data=pd.Series(np.random.randn(5),index=[['a','a','b','b','c'],list(np.arange(5))]) data[['a','b']]=data.loc[['a','b']] data['a':'b']=data.loc['a':'b'] 在“内层”中进行选取:data.loc[:,1] 层次化索引生成透视表:data.unstack() unstack的逆运算是stack:data.unstack().stack() 重排与分级排序data.swaplevel('name1', 'name2'):重排 data.sort_index():根据单个级别中的值对数据进⾏排序--data.sort_index(level='') 根据级别汇总统计:frame.sum(level='k1',axis=1) DataFrame的set_index函数:将其⼀个或多个列转换为⾏索引,并创建⼀个新的DataFrame frame2 = frame.set_index(['c', 'd']) reset_index的功能跟set_index刚好相反,层次化索引的级别会 被转移到列⾥⾯ 合并数据集一、pandas.merge:可根据⼀个或多个键将不同DataFrame中的⾏ 连接起来(类sql的join) 1.参数详解  2.how 连接方式可选参数
2.how 连接方式可选参数

merge 结果:一对多 和 多对多 连接是行的笛卡尔积 警告: 在进行列-列连接时,DataFrame对象中的索引会被丢弃 DataFrame还有⼀个便捷的join实例⽅法,它能更为⽅便地实现 按索引合并: left2.join(right2,on='key', how='outer') numpy数据合并:np.concatenate()函数(参数axis) 二、pandas.concat:可以沿着⼀条轴将多个对象堆叠到⼀起。 concat参数如下: 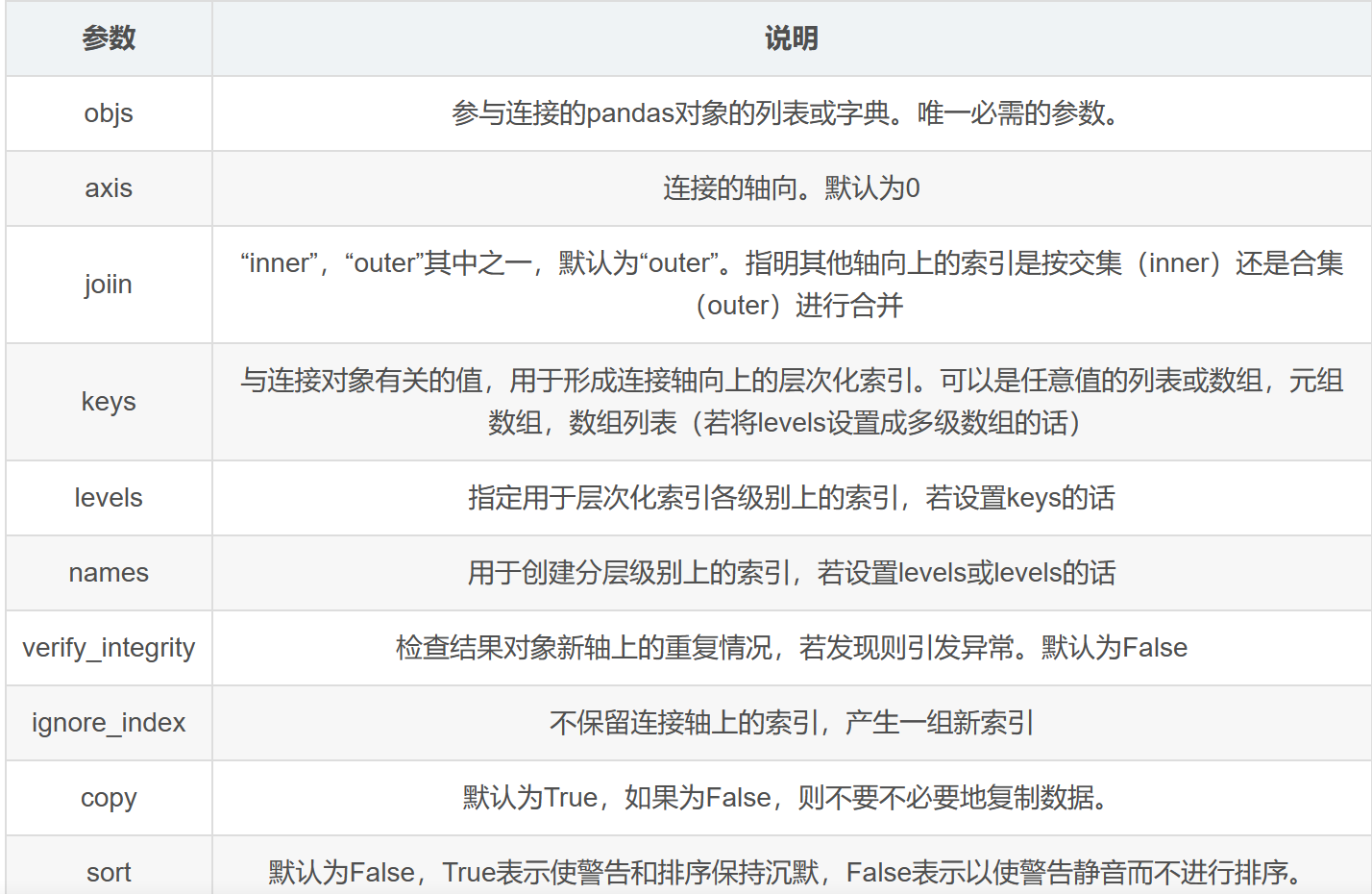
pd.concat([df1,df2],keys=['x','y'],axis=1,names=['xx','yy']) combine_first |
【本文地址】