| Pandas 读取数据丨慕课网教程 | 您所在的位置:网站首页 › pandas怎么打开 › Pandas 读取数据丨慕课网教程 |
Pandas 读取数据丨慕课网教程
|
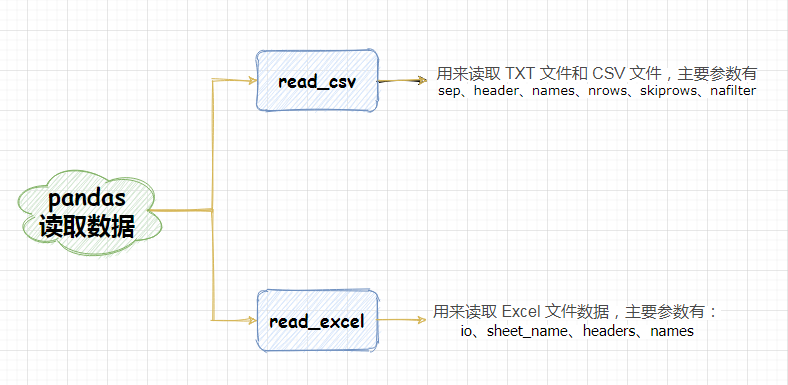
Pandas读取数据文件
1. 前言
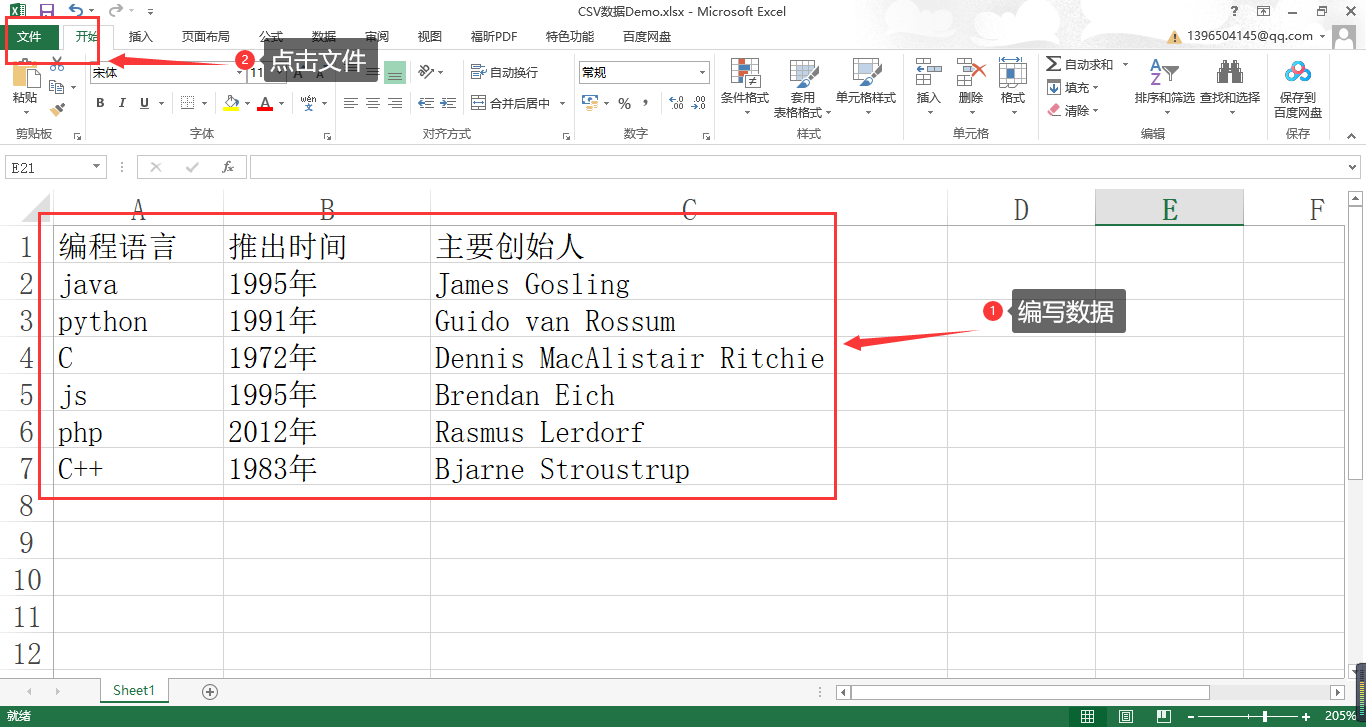
上节课我们一同通过安装 Anaconda 快速的配置好了开发环境,那么从本节课开始我们将正式学习 Pandas 库的强大功能。我们在简介中也说到了 Pandas 是一个用来做数据处理和分析的工具。 既然要做数据处理和分析,那么首先肯定要有数据对不对?这也正是我们这节课的主题:使用 Pandas 读取数据文件。一般意义上的数据文件包括:TXT 文件,CSV 文件以及 Excel 文件,Pandas 库中提供了简洁而强大的方法可以快速从这些数据文件中读取我们需要的数据,进而对数据进行处理和分析。 2. 使用 Pandas 读取 txt 数据文件 2.1 TXT 数据文件格式TXT 文件是一种文本文件,里面存储的数据格式每一行表示行数据,列数据则是通过某种分隔符对一行的数据进行拆分的,下面是一个 TXT 数据文件举例。 书名,作者,出版日期,价格 python从入门到实战,埃里克,2020,85 python数据分析,丹尼尔,2020,80 python爬虫技术,李宁,2020,79 疯狂python讲义,李刚,2019,113 大数据处理,石宣化,2018,43 人工智能,史蒂芬,2018,97 深度学习,伊恩,2017,152 人工智能算法,杰弗瑞,2020,53 人工智能简史,尼克,2017,24我们新建了一个记事本文件命名为: pandasDataDemo.txt ,里面添加了一些人工智能相关的书名、作者名、出版日期和书的价格,这里我们使用的是 “,” 分割符进行分割列数据的。 2.2 read_csv()函数read_csv() 函数为 Pandas 读取 txt、csv 数据文件提供了强力的支持,该函数含有四五十个参数,默认是 从文件、URL、文件新对象中加载带有分隔符的数据,默认分隔符是逗号。下面我们列举出它最常用的几个参数。 参数名称 描述 filepath_or_buffer 可以是url,类型包括(http, ftp, s3和文件),比如上面我们 pandasDataDemo.txt 文件的位置为:C:\Users\13965\Documents\myFuture\IMOOC\pandasCourse-progress\data_source\pandasDataDemo.txt ,如果不指定类型,默认是 file 类型 sep 指定数据的分隔符,默认是 “,” header 指定数据的从第几行解析,默认是文件数据的第1行,header=0,如果不用文件中的某行作为列名,要写上 header=None names 指定列名,如 names=[‘A’,‘B’,‘C’,‘D’,‘E’] nrows 指定数据文件中读取多少行的数据,从数据第一行开始 skiprows 指定忽略的行数,从数据文件头开始 skipfooter 指定忽略的行数,从文件的尾部开始(c引擎不支持) encoding 指定数据解析时,字符的集类型,通常指定为 “utf-8” engine 指定数据分析的引擎,默认是 c,c 引擎虽然快但是 Python 引擎的功能更多。 na_filter 是否检查缺失值(空字符串或者是空值),当数据文件较大时,并且很少有缺失值,设置 na_filter=False能有效的提升读取的速度 2.3 read_csv() 函数的使用我们这里自建了一个 pandasDataDemo.txt 数据文件,通过 Pandas 读取该文件数据,进行上述各项参数的详细讲解。 1. 读取数据 首先这里我们通过默认的文件读取类型,读取我们的 pandasDataDemo.txt 数据文件 # 导入pandas包 import pandas as pd # 指定导入的文件地址 默认是file,这里的路径中省略了 file:/ data_path="C:/Users/13965/Documents/myFuture/IMOOC/pandasCourse-progress/data_source/pandasDataDemo.txt" data = pd.read_csv(data_path) print(data) # --- 输出结果 --- 书名 作者 出版日期 价格 0 python从入门到实战 埃里克 2020 85 1 python数据分析 丹尼尔 2020 80 2 python爬虫技术 李宁 2020 79 3 疯狂python讲义 李刚 2019 113 4 大数据处理 石宣化 2018 43 5 人工智能 史蒂芬 2018 97 6 深度学习 伊恩 2017 152 7 人工智能算法 杰弗瑞 2020 53 8 人工智能简史 尼克 2017 24可以看到输出结果数据内容和我们 TXT 中的数据一样,在数据的格式上进行了行和列的解析,并自动生成了行索引 0-8,共 9 行数据。 2. 参数 sep sep 参数的作用是指定数据的分隔符,默认是 “,”。我们首先将 pandasDataDemo.txt 中的数据列改成以 “=” 进行分割: 书名=作者=出版日期=价格 python从入门到实战=埃里克=2020=85 python数据分析=丹尼尔=2020=80 python爬虫技术=李宁=2020=79 疯狂python讲义=李刚=2019=113 大数据处理=石宣化=2018=43 人工智能=史蒂芬=2018=97 深度学习=伊恩=2017=152 人工智能算法=杰弗瑞=2020=53 人工智能简史=尼克=2017=24接下来我们通过 sep 设置解析列的分隔符: # 导入pandas包 import pandas as pd # 指定导入的文件地址 默认是file,这里的路径中省略了 file:/ data_path="C:/Users/13965/Documents/myFuture/IMOOC/pandasCourse-progress/data_source/pandasDataDemo.txt" # 这里我们传入参数 sep data = pd.read_csv(data_path,sep="=") print(data) # --- 输出结果 --- 书名 作者 出版日期 价格 0 python从入门到实战 埃里克 2020 85 1 python数据分析 丹尼尔 2020 80 2 python爬虫技术 李宁 2020 79 3 疯狂python讲义 李刚 2019 113 4 大数据处理 石宣化 2018 43 5 人工智能 史蒂芬 2018 97 6 深度学习 伊恩 2017 152 7 人工智能算法 杰弗瑞 2020 53 8 人工智能简史 尼克 2017 24通过指定 sep 参数将数据以 “=” 进行各列的分割。 3. 参数 header 指定数据的解析,从哪一行开始,指定的这一行将默认的作为列索引。 # 导入pandas包 import pandas as pd # 指定导入的文件地址 默认是file,这里的路径中省略了 file:/ data_path="C:/Users/13965/Documents/myFuture/IMOOC/pandasCourse-progress/data_source/pandasDataDemo.txt" # 这里我们传入参数 header,指定从第4行开始解析 data = pd.read_csv(data_path,sep="=",header=3) print(data) # --- 输出结果 --- python爬虫技术 李宁 2020 79 #该行数据在源文件中是 第4行 0 疯狂python讲义 李刚 2019 113 1 大数据处理 石宣化 2018 43 2 人工智能 史蒂芬 2018 97 3 深度学习 伊恩 2017 152 4 人工智能算法 杰弗瑞 2020 53 5 人工智能简史 尼克 2017 24输出解析:这里可以看到,我们参数 header 传的是 3,输出结果的第一行为“python 爬虫技术 李宁 2020 79”,在源数据中是第4行数据,因为 Pandas 解析数据的行数是从0下标开始的,并且将第4行默认作为列索引的值。 如果不使用数据中的某行作为列名,要声明 header=None ,Pandas 会默认以数字编号为各列名称。 # 导入pandas包 import pandas as pd # 指定导入的文件地址 默认是file,这里的路径中省略了 file:/ data_path="C:/Users/13965/Documents/myFuture/IMOOC/pandasCourse-progress/data_source/pandasDataDemo.txt" # 这里我们传入参数 header=None data = pd.read_csv(data_path,sep="=",header=None) print(data) # --- 输出结果 --- 0 1 2 3 0 书名 作者 出版日期 价格 1 python从入门到实战 埃里克 2020 85 2 python数据分析 丹尼尔 2020 80 3 python爬虫技术 李宁 2020 79 4 疯狂python讲义 李刚 2019 113 5 大数据处理 石宣化 2018 43 6 人工智能 史蒂芬 2018 97 7 深度学习 伊恩 2017 152 8 人工智能算法 杰弗瑞 2020 53 9 人工智能简史 尼克 2017 244. 参数 names 通过该参数,我们可以为解析的数据,添加列索引值。 # 导入pandas包 import pandas as pd # 指定导入的文件地址 默认是file,这里的路径中省略了 file:/ data_path="C:/Users/13965/Documents/myFuture/IMOOC/pandasCourse-progress/data_source/pandasDataDemo.txt" # 这里我们传入参数 names,传入列名称 data = pd.read_csv(data_path,sep="=",header=None,names=["AA","BB","CC","DD"]) print(data) # --- 输出结果 --- AA BB CC DD 0 书名 作者 出版日期 价格 1 python从入门到实战 埃里克 2020 85 2 python数据分析 丹尼尔 2020 80 3 python爬虫技术 李宁 2020 79 4 疯狂python讲义 李刚 2019 113 5 大数据处理 石宣化 2018 43 6 人工智能 史蒂芬 2018 97 7 深度学习 伊恩 2017 152 8 人工智能算法 杰弗瑞 2020 53 9 人工智能简史 尼克 2017 24输出解析:通指定 names 的值,我们看到输出中列名称已经变成我们指定的 AA,BB,CC,DD了。 5. 参数 nrows 指定解析数据的行数: # 导入pandas包 import pandas as pd # 指定导入的文件地址 默认是file,这里的路径中省略了 file:/ data_path="C:/Users/13965/Documents/myFuture/IMOOC/pandasCourse-progress/data_source/pandasDataDemo.txt" # 这里我们传入参数 nrows data = pd.read_csv(data_path,sep="=",nrows=3) print(data) # --- 输出结果 --- 书名 作者 出版日期 价格 0 python从入门到实战 埃里克 2020 85 1 python数据分析 丹尼尔 2020 80 2 python爬虫技术 李宁 2020 79输出解析:这里可以看到输出结果,包含了数据文件中的四行,而不是 3 行数据,这是因为默认的数据的第一行解析为列索引后,然后再进行 3 行数据的解析。 Tips:read_csv() 函数解析数据的逻辑为,根据里面参数设置,逐行的去解析文件中的数据,如果不指定 names,会先把第一行的数据解析为 列索引,然后再去根据条件,继续向下解析。 下面我们通过设置 names 的值(或者设置 names=None),并传入解析的 nrows 数量,看一下输出结果: import pandas as pd # 指定导入的文件地址 默认是file,这里的路径中省略了 file:/ data_path="C:/Users/13965/Documents/myFuture/IMOOC/pandasCourse-progress/data_source/pandasDataDemo.txt" # 这里我们传入参数 nrows 和 names data = pd.read_csv(data_path,sep="=",nrows=3,names=["AA","BB","CC","DD"]) print(data) # --- 输出结果 --- AA BB CC DD 0 书名 作者 出版日期 价格 1 python从入门到实战 埃里克 2020 85 2 python数据分析 丹尼尔 2020 80输出解析:可以看到这里的 3 行正是我们数据文件中的前三行数据。 6. 参数 skiprows 解析数据,从数据开始忽略多少行开始解析: # 导入pandas包 import pandas as pd # 指定导入的文件地址 默认是file,这里的路径中省略了 file:/ data_path="C:/Users/13965/Documents/myFuture/IMOOC/pandasCourse-progress/data_source/pandasDataDemo.txt" # 这里我们传入参数 skiprows data = pd.read_csv(data_path,sep="=",skiprows=5) print(data) # --- 输出结果 --- 大数据处理 石宣化 2018 43 0 人工智能 史蒂芬 2018 97 1 深度学习 伊恩 2017 152 2 人工智能算法 杰弗瑞 2020 53 3 人工智能简史 尼克 2017 24输出解析:这里可以看到数据在忽略了 5 行之后,将第 6 行数据解析为列名称,继续向下进行数据的解析。 7. 参数 skipfooter ,encoding ,engine skipfooter 参数:解析数据,忽略从后向前说多少条的数据行; encoding 参数:制定解析的编码方式; engine 参数:指定解析的引擎类型; # 导入pandas包 import pandas as pd # 指定导入的文件地址 默认是file,这里的路径中省略了 file:/ data_path="C:/Users/13965/Documents/myFuture/IMOOC/pandasCourse-progress/data_source/pandasDataDemo.txt" # 这里我们传入参数 skiprows data = pd.read_csv(data_path,sep="=",skipfooter=7) print(data) # --- 输出结果 --- 涔﹀悕 浣滆�� 鍑虹増鏃ユ湡 浠锋牸 0 python浠庡叆闂ㄥ埌瀹炴垬 鍩冮噷鍏� 2020 85 1 python鏁版嵁鍒嗘瀽 涓瑰凹灏� 2020 80 :6: ParserWarning: Falling back to the 'python' engine because the 'c' engine does not support skipfooter; you can avoid this warning by specifying engine='python'. data = pd.read_csv(data_path,sep="=",skipfooter=7)输出解析:这里可以看到输出结果存在的问题,首先根据提示可以看出是 c 引擎不支持 skipfooter 的解析;其实是存在中文乱码的问题,为了解决这两个问题,我们通过 encoding 和 engine 分别制定编码方式和引擎类型。 # 导入pandas包 import pandas as pd # 指定导入的文件地址 默认是file,这里的路径中省略了 file:/ data_path="C:/Users/13965/Documents/myFuture/IMOOC/pandasCourse-progress/data_source/pandasDataDemo.txt" # 这里我们传入参数 skiprows,engine,encoding data = pd.read_csv(data_path,sep="=",skipfooter=7, engine='python',encoding='utf-8') print(data) # --- 输出结果 --- 书名 作者 出版日期 价格 0 python从入门到实战 埃里克 2020 85 1 python数据分析 丹尼尔 2020 80输出解析:这里我们通过指定编码 encoding=‘utf-8’ 和解析引擎 engine=‘python’ ,可以看到修复了上面存在的问题,并且看到结果是忽略了数据的后7行,只解析了前 3 行数据。 Tips:所谓引擎,最通俗的理解就是动力的来源,我们这里提到的 C 引擎和 Python 引擎,主要是指在 Pandas 解析数据时,解析函数最底层主要运行程序的编写语言,在使用这两个解析器引擎时,C引擎的速度更快,但是 Python 引擎的功能更多更齐全。 8. 参数 na_filter 该参数可配置解析文件时是否检查(空字符串或者是空值),如果一个文件比较大的话,指定 na_filter 能有效的提高解析数据的速度: 首先我们将源数据最后两行的作者这一列删掉内容,如下所示: 书名=作者=出版日期=价格 python从入门到实战=埃里克=2020=85 python数据分析=丹尼尔=2020=80 python爬虫技术=李宁=2020=79 疯狂python讲义=李刚=2019=113 大数据处理=石宣化=2018=43 人工智能=史蒂芬=2018=97 深度学习=伊恩=2017=152 人工智能算法==2020=53 人工智能简史==2017=24针对缺失值,read_csv() 函数默认是将缺失值解析后,展示为 NaN ,这里我们看一下解析出来的数据结果: # 导入pandas包 import pandas as pd # 指定导入的文件地址 默认是file,这里的路径中省略了 file:/ data_path="C:/Users/13965/Documents/myFuture/IMOOC/pandasCourse-progress/data_source/pandasDataDemo.txt" data = pd.read_csv(data_path,sep="=", engine='python',encoding='utf-8') print(data) # ---输出结果--- 书名 作者 出版日期 价格 0 python从入门到实战 埃里克 2020 85 1 python数据分析 丹尼尔 2020 80 2 python爬虫技术 李宁 2020 79 3 疯狂python讲义 李刚 2019 113 4 大数据处理 石宣化 2018 43 5 人工智能 史蒂芬 2018 97 6 深度学习 伊恩 2017 152 7 人工智能算法 NaN 2020 53 8 人工智能简史 NaN 2017 24 # 这里看到最后良好的作者都解析为 NaN下面我们在 read_csv() 函数中,加入 na_filter=False属性: # 导入pandas包 import pandas as pd # 指定导入的文件地址 默认是file,这里的路径中省略了 file:/ data_path="C:/Users/13965/Documents/myFuture/IMOOC/pandasCourse-progress/data_source/pandasDataDemo.txt" # 这里我们传入参数 na_filter data = pd.read_csv(data_path,sep="=",na_filter=False, engine='python',encoding='utf-8') print(data) # ---输出结果--- 书名 作者 出版日期 价格 0 python从入门到实战 埃里克 2020 85 1 python数据分析 丹尼尔 2020 80 2 python爬虫技术 李宁 2020 79 3 疯狂python讲义 李刚 2019 113 4 大数据处理 石宣化 2018 43 5 人工智能 史蒂芬 2018 97 6 深度学习 伊恩 2017 152 7 人工智能算法 2020 53 8 人工智能简史 2017 24输出解析:这里可以看到,通过 na_filter=False 参数指定后,read_csv() 函数将不对缺失值进行解析。 3. Pandas 读取csv数据文件 3.1 CSV数据文件CSV 即 Comma Separate Values 是逗号分隔文件的缩写,它是一种用来存储数据的纯文本文件,每一栏的数据是通过 “,” 进行分割的,每一行数据都以回车符结束。csv文件的创建方式有两种:第一种是通过新建记事本,填写好每行以 “,” 分列,回车结尾的数据保存后,将记事本的后缀名改为 .csv 即可;第二种是通过 Excel 创建 CSV 文件。 首先新建Excel表文件,打开进行编辑:
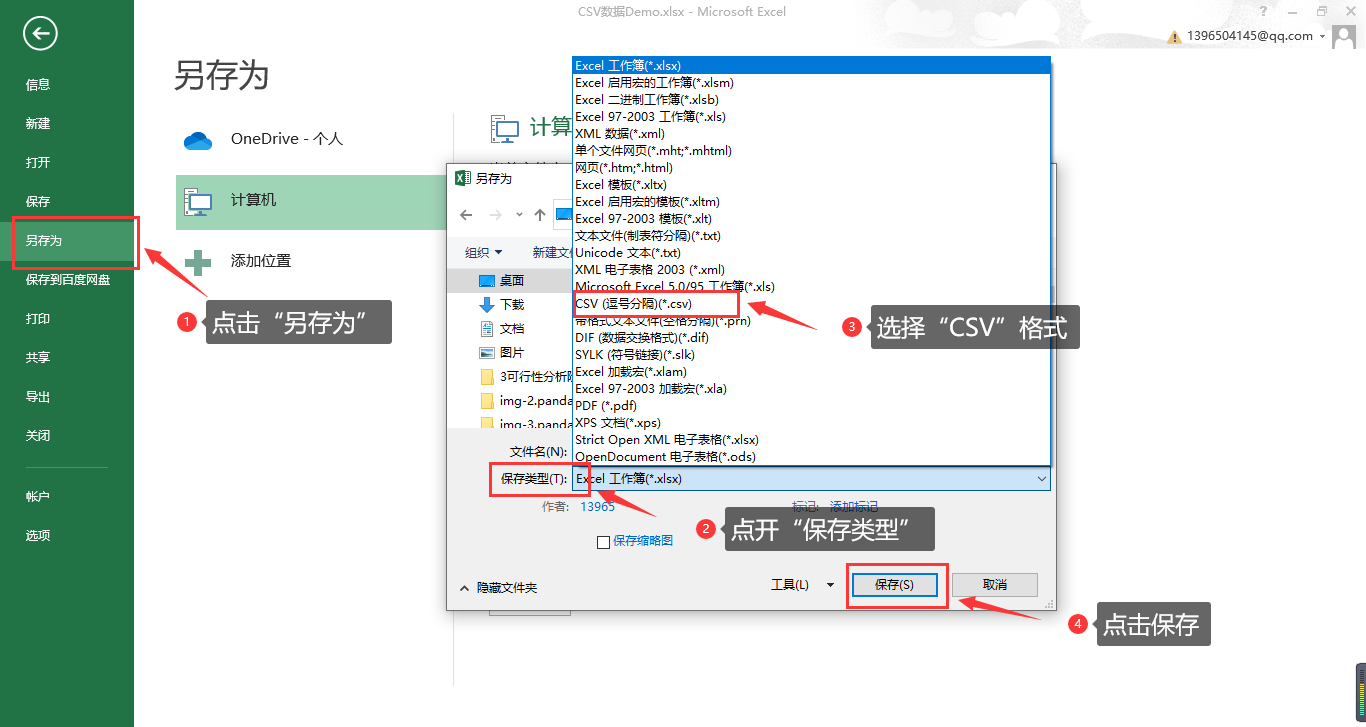
接下来我们将数据文件存储为CVS格式:
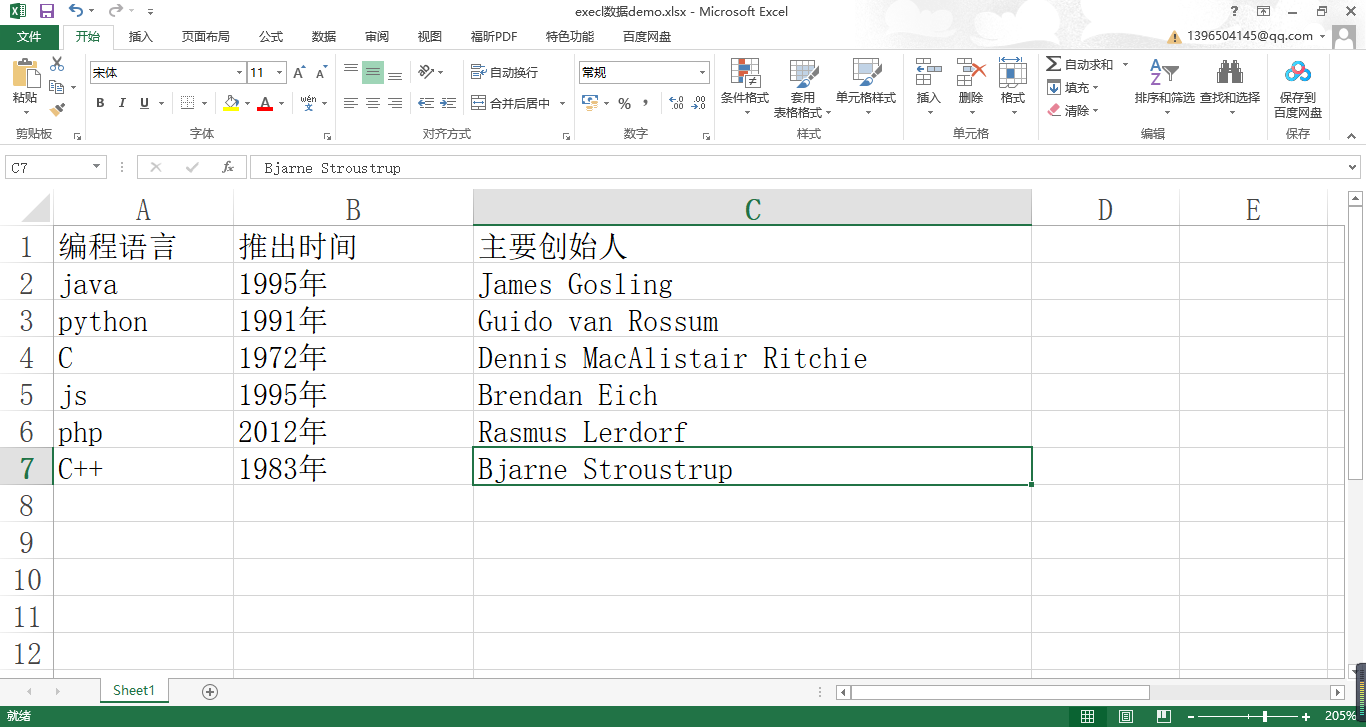
我们将生成的 CSV 数据 Demo.csv 数据文件,右键通过记事本打开,可以看到里面的数据格式如下: 编程语言,推出时间,主要创始人 java,1995年,James Gosling python,1991年,Guido van Rossum C,1972年,Dennis MacAlistair Ritchie js,1995年,Brendan Eich php,2012年,Rasmus Lerdorf C++,1983年,Bjarne Stroustrup 3.2 CSV 数据文件的读取Pandas 读取 CSV 文件用的也是 read_csv()函数,解析数据是默认的使用 “,” 进行划分列,当然对应的参数也是适用的,这里我们就不一一赘述,我们演示一下读取 csv 文件数据。 # 导入pandas包 import pandas as pd # 指定导入的文件地址 默认是file,这里的路径中省略了 file:/ data_path="C:/Users/13965/Documents/myFuture/IMOOC/pandasCourse-progress/data_source/CSV数据Demo.csv" # 这里我们指定解析引擎为 python data = pd.read_csv(data_path, engine='python') print(data) # ---输出结果--- 编程语言 推出时间 主要创始人 0 java 1995年 James Gosling 1 python 1991年 Guido van Rossum 2 C 1972年 Dennis MacAlistair Ritchie 3 js 1995年 Brendan Eich 4 php 2012年 Rasmus Lerdorf 5 C++ 1983年 Bjarne Stroustrup 4. Pandas 读取 excel 数据文件 4.1 Excel数据文件Excel 是我们比较常见的办公文件之一,经常用于数据的整理、分析和可视化方面的工作,具有行和列的数据格式,自身含有大量的数据处理和分析函数,但是如果我们 Excel 的数据量比较大,他在数据的处理上就会很慢,甚至有打不开的情况发生,而 Pandas 不仅功能分析上比较强大,在速度上也远远优于 Excel 的处理。下面将具体看一下 Pandas 是如何读取 Excel 数据的,首先我们先创建一个 Excel 数据文件: excel 数据demo.xlsx:
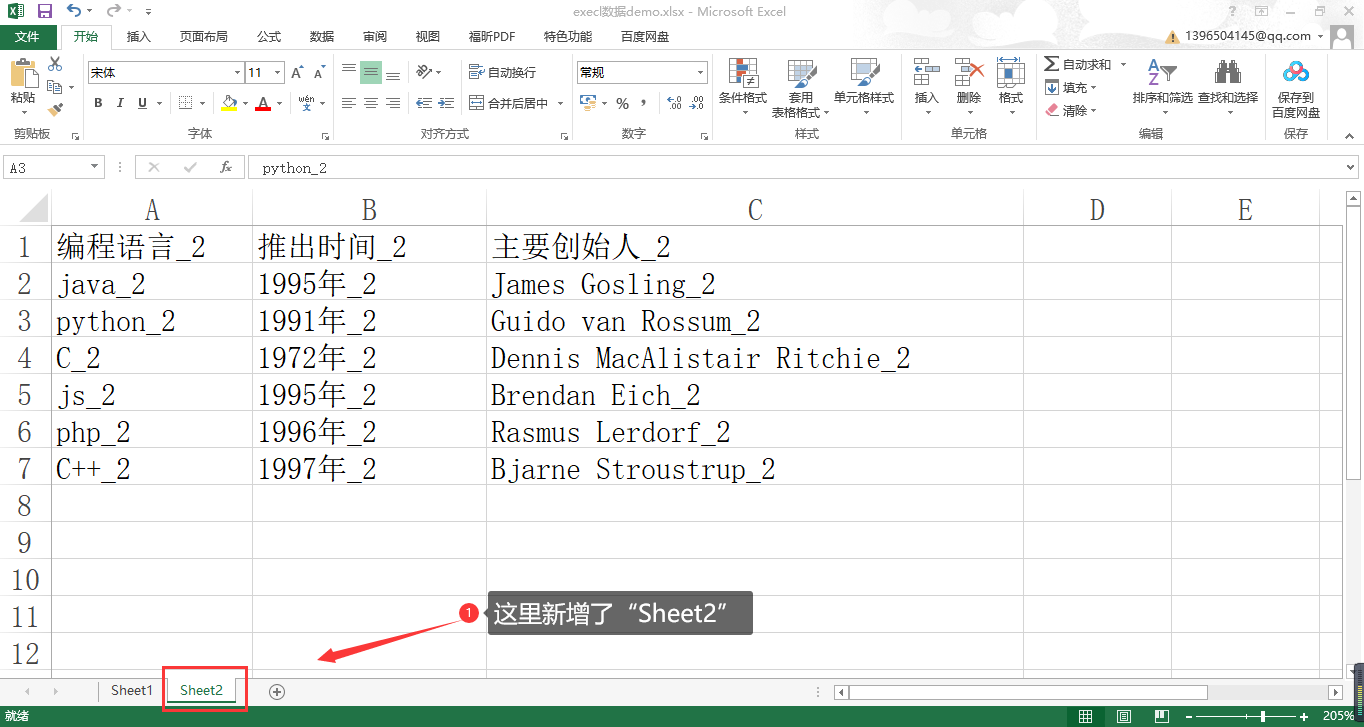
Pandas 提供了 read_excel() 函数用于 Excel 数据文件的读取,并为其提供了很多的参数用于解析 Excel 数据的设置,接下来我们列举一些该函数中常用的几个参数设置: 参数名称 描述 io 传入 execl 文件的对象,字符串可能是一个 URL 包括的类型(http,ftp,s3和文件) sheet_name 指定读取第几个 sheet 表,默认是第一个,sheet_name=None 可以读取所有的 sheet header 指定哪一行作为列名,如果不需要里面的行作为列名,要写上 header = None names 指定列名,如 names=[‘A’,‘B’,‘C’,‘D’,‘E’]1. 首先,我们通过 read_excel() 的 io 将 “execl数据demo.xlsx ”中的数据解析出来: # 导入pandas包 import pandas as pd # 指定导入的文件地址 默认是file,这里的路径中省略了 file:/ data_path="C:/Users/13965/Documents/myFuture/IMOOC/pandasCourse-progress/data_source/execl数据demo.xlsx" data = pd.read_excel(data_path) print(data) # --- 输出结果 --- 编程语言 推出时间 主要创始人 0 java 1995年 James Gosling 1 python 1991年 Guido van Rossum 2 C 1972年 Dennis MacAlistair Ritchie 3 js 1995年 Brendan Eich 4 php 2012年 Rasmus Lerdorf 5 C++ 1983年 Bjarne Stroustrup输出解析:这里是将 Excel 中的第一个工作表的数据解析出来 Excel 中行和列分别解析为行数据和列数据,默认第一行作为列名称。 2. 参数 sheet_name 该参数用于设置读取 Excel 数据中的哪个工作表,值为工作表名称,首先我们在 “execl数据demo.xlsx” 文件中新增一个工作表 Sheet2 ,数据的内容直接从工作表1 中复制,并为每一项数据添加 “_2” 作为区分:
首先我们通过设置 sheet_name=‘Sheet2’ 来读取 Sheet2 中的数据: # 导入pandas包 import pandas as pd # 指定导入的文件地址 默认是file,这里的路径中省略了 file:/ data_path="C:/Users/13965/Documents/myFuture/IMOOC/pandasCourse-progress/data_source/execl数据demo.xlsx" # 这里我们传入参数 sheet_name data = pd.read_excel(data_path,sheet_name='Sheet2') print(data) # --- 输出结果 --- 编程语言_2 推出时间_2 主要创始人_2 0 java_2 1995年_2 James Gosling_2 1 python_2 1991年_2 Guido van Rossum_2 2 C_2 1972年_2 Dennis MacAlistair Ritchie_2 3 js_2 1995年_2 Brendan Eich_2 4 php_2 1996年_2 Rasmus Lerdorf_2 5 C++_2 1997年_2 Bjarne Stroustrup_2输出解析:这里可以看到解析的数据为 Sheet2 中的数据内容。 接下来我们设置 sheet_name=None ,来解析所有工作表的数据: # 导入pandas包 import pandas as pd # 指定导入的文件地址 默认是file,这里的路径中省略了 file:/ data_path="C:/Users/13965/Documents/myFuture/IMOOC/pandasCourse-progress/data_source/execl数据demo.xlsx" # 这里我们传入参数 sheet_name data = pd.read_excel(data_path,sheet_name=None) print(data) # --- 输出结果 --- {'Sheet1': 编程语言 推出时间 主要创始人 0 java 1995年 James Gosling 1 python 1991年 Guido van Rossum 2 C 1972年 Dennis MacAlistair Ritchie 3 js 1995年 Brendan Eich 4 php 2012年 Rasmus Lerdorf 5 C++ 1983年 Bjarne Stroustrup, 'Sheet2': 编程语言_2 推出时间_2 主要创始人_2 0 java_2 1995年_2 James Gosling_2 1 python_2 1991年_2 Guido van Rossum_2 2 C_2 1972年_2 Dennis MacAlistair Ritchie_2 3 js_2 1995年_2 Brendan Eich_2 4 php_2 1996年_2 Rasmus Lerdorf_2 5 C++_2 1997年_2 Bjarne Stroustrup_2}输出解析:可以看到输出结果是将 Sheet1 和 Sheet2 的数据都进行了解析,格式是字典形式,工作表名为 key,值是解析的工作表的数据值。 3. 参数 header header 参数用于指定哪一行作为列名: # 导入pandas包 import pandas as pd # 指定导入的文件地址 默认是file,这里的路径中省略了 file:/ data_path="C:/Users/13965/Documents/myFuture/IMOOC/pandasCourse-progress/data_source/execl数据demo.xlsx" # 这里我们传入参数 header data = pd.read_excel(data_path,header =2) print(data) # ---输出结果--- python 1991年 Guido van Rossum 0 C 1972年 Dennis MacAlistair Ritchie 1 js 1995年 Brendan Eich 2 php 2012年 Rasmus Lerdorf 3 C++ 1983年 Bjarne Stroustrup输出解析:这里可以看到将第二行的数据解析为列名,并从改行详细继续解析数据。 4. 参数 names names 用于手动传入列名的值: # 导入pandas包 import pandas as pd # 指定导入的文件地址 默认是file,这里的路径中省略了 file:/ data_path="C:/Users/13965/Documents/myFuture/IMOOC/pandasCourse-progress/data_source/execl数据demo.xlsx" # 这里我们传入参数 header data = pd.read_excel(data_path,names =["a1","a2","a3"]) print(data) # ---输出结果--- a1 a2 a3 0 java 1995年 James Gosling 1 python 1991年 Guido van Rossum 2 C 1972年 Dennis MacAlistair Ritchie 3 js 1995年 Brendan Eich 4 php 2012年 Rasmus Lerdorf 5 C++ 1983年 Bjarne Stroustrup输出解析:这里手动传入了列的名称为 a1 , a2 , a3。 3.小结本节课程我们主要学习了 Pandas 解析 TXT、CSV 、Execl 文件的数据方法,讲到了 read_csv() ,read_execl() 两个函数,他们之间有很多方法参数是相同的,大家多加练习具体感受一下。本节课程的重点如下: txt 、csv 、execl 各数据文件自身的格式特点; read_csv() 函数具有的常用参数设置; read_excel() 函数具有的常用参数设置。
Tips:想要学习更多Pandas相关知识,可以点击 Pandas 读取 MySql数据 Pandas Pandas 数据结构Series Pandas Pandas 数据结构DataFrame 划线 写笔记 复制0/1000 |
【本文地址】