| 数据清洗处理实战:pandas查找与删除重复行(duplicate()与drop | 您所在的位置:网站首页 › pandas填充表内空值 › 数据清洗处理实战:pandas查找与删除重复行(duplicate()与drop |
数据清洗处理实战:pandas查找与删除重复行(duplicate()与drop
|
一、实战应用背景
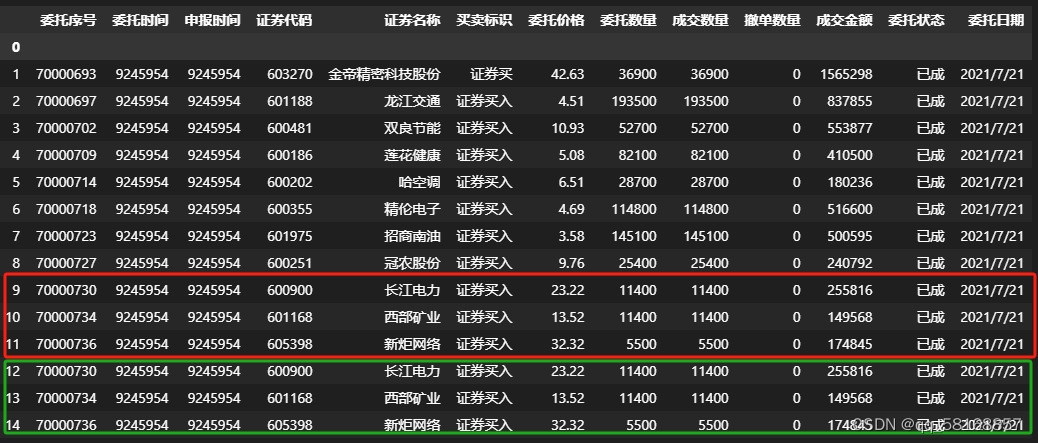
最近在进行数据识别方面的开发时,多人识别的数据汇总后,发现有不少是重行的,这时为理清责任,就需要将重复数据进行标记,并删除重复数据。针对这一问题,pandas上有高效的处理方法,就是用duplicate()方法进行标记,用drop_duplicate方法进行去重。
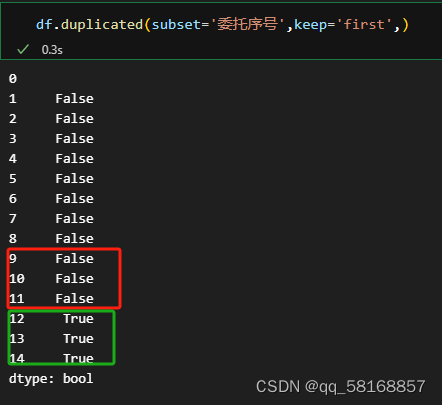
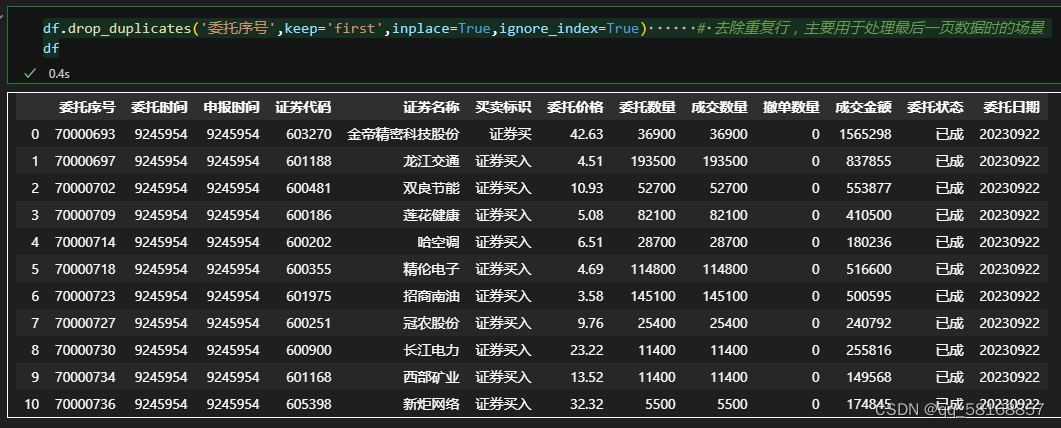
两个方法的参数见下表 两种方法参数对照表 duplicate()方法drop_duplicate()参数含义subsetsubset如果不按照全部内容查重,那么需要指定按照哪些列进行查重。需要注意的是,最好找一个唯一值设置,如单号、身份证号等,比如按照姓名进行查重,就会出现重名的情况。本例用单号:subset=['委托序号'],如果用姓名,可以增加其他列进行辅助,解决重名的问题,如可以按照姓名和出生日期两列查重,subset=['name','birthday'],同理还可以再添加列,这样就可以基本保证去重效果了。keepkeep决定保留重复行中的哪个:first:保留重复值的第一个;last:保留重复值的最后一个;False:删除重复值的所有行inplace布尔值,默认为False,是否直接在原数据上删除重复项或删除重复项后返回副本。ignore_index 布尔值,默认False:不改变DataFrame的原有索引标签,否则将修改为0,1,…n-1 三、解决案例 (一)查重 df.duplicated(subset='委托序号',keep='first')
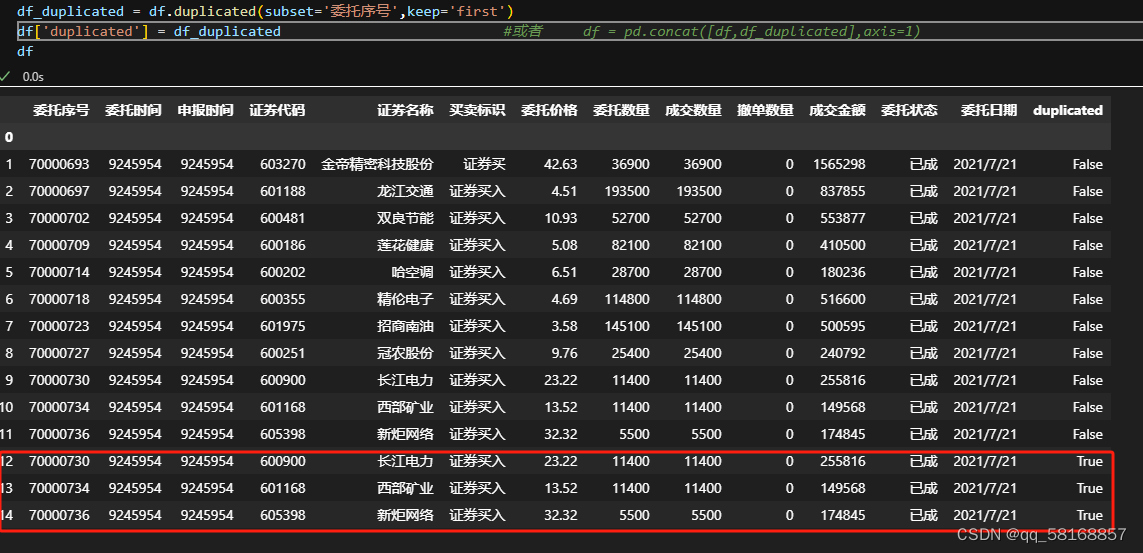
返回 的这些布尔值可以用一个pd.Series来接收,可以和原来的数据框合并,以进行对比。 df_duplicated = df.duplicated(subset='委托序号',keep='first') df['duplicated'] = df_duplicated # 或者用下面的语句,但没有上面语句简洁实用 # df = pd.concat([df,df_duplicated],axis=1) df
|
【本文地址】
公司简介
联系我们