| YOLOv8详解:损失函数、Anchor | 您所在的位置:网站首页 › p50nova9pro对比 › YOLOv8详解:损失函数、Anchor |
YOLOv8详解:损失函数、Anchor
|
一. 损失函数
1. 对象损失
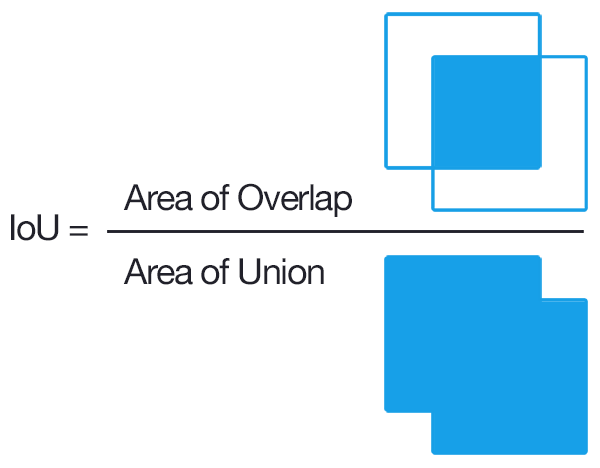
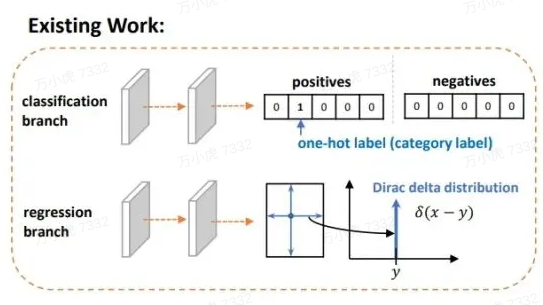
v5中使用BCE来判断“该区域是否有对象”。在输出中根据此处输出来过滤无对象区域。 v8中取消了这一损失,改为用分类损失中,“该区域是否有此类对象”的one-hot编码形式来判断。 个人理解:v5“判断对象有无”的形式,虽然能加速结果处理掩码的速度,但处理多分类问题时,该判据的可信度可能会随着类别数的增加、特征信息的互相影响而降低。同时另一方面,此损失的功能也被分类损失部分覆盖。 v8在此方向的改进不仅提升了模型权重的利用率,还通过存在状态与分类状态的强关联,使得标签能更好指导模型对类别区分能力的学习。 2. 分类损失 BCEv5/v8均使用BCE(二元交叉熵)作为分类损失,每类别判断“是否为此类”,并输出置信度。 IOU(Intersection over Union、交集-并集比例)是一种描述框之间的重合度的方式。在回归任务中,可通过“目标框”与“预测框”的比值来衡量框的回归程度 v5使用的CIOU loss用以令锚框更加接近标签值的损失,在(IOU)交并比损失上加上了宽高比的判据,从而更好在三种几何参数:重叠面积、中心点距离、长宽比上拟合目标框。 单独的CIOU loss的目标为“预测一个绝对正确的值(标签值)”,在数学上可以看做是一种“狄拉克分布”(一个点概率为无穷大,其他点概率为0)。 如果把标签认为是"绝对正确的目标",那么学习出的就是狄拉克分布,概率密度是一条尖锐的竖线。然而真实场景,物体边界并非总是十分明确的。
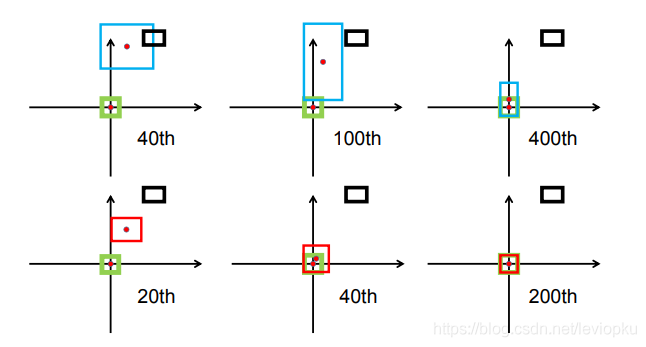
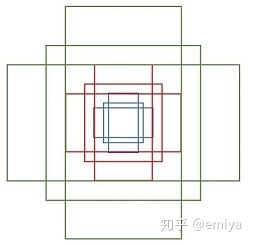
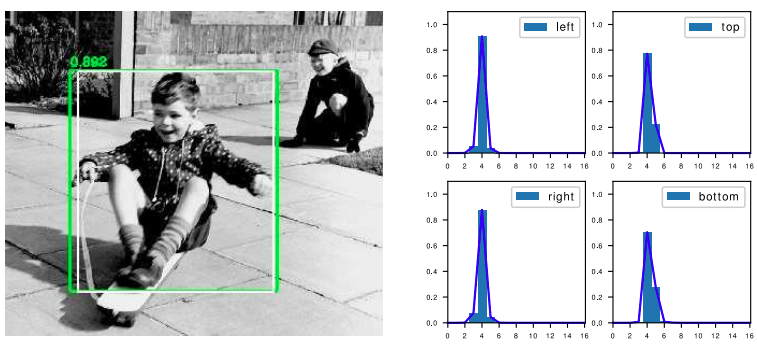
虽然v8的CIOU使用方式与v5保持一致,但引入Anchor-Free的Center-based methods(基于中心点)后,模型从输出“锚框大小偏移量(offest)”变为"预测目标框左、上、右、下边框距目标中心点的距离(ltrb = left, top, right, bottom)"。 为配合Anchor-Free、以及提升泛化性,在v8中,增加了DFL损失。DFL以交叉熵的形式,去优化与标签y最接近的一左一右2个位置的概率,从而让网络更快的聚焦到目标位置及邻近区域的分布。 也就是说,学习的分布理论上是在真实浮点坐标的附近,并以线性插值的模式得到距离左右整数坐标的权重。 这种学习标签周围位置的损失,能够增强模型在复杂情况下,如遮挡、移动物体时的泛化性。 需要额外指出的是,DFL有一个隐藏的超参数——Reg_max。 这个参数代表了“输出特征图中,ltrb预测的最大范围”。默认值为16,即能表示16个特征图单元所映射的实际距离。 在v8中,最大下采样倍数为20。即在默认环境——640 x 360下,DFL能表达的最大单边距离为:320。能够覆盖此分辨率下的所有目标。 但此超参数Reg_max是固定值——16,如果你的输入是640,最大下采样到20 x 20的特征图,那么16是够用的。 如果输入没有resize或者超过了640则需设置这个Reg_max参数,否则如果目标尺寸还大,将无法拟合到这个偏移量。 如1280 x 1280的图片,目标1280 x 960,最大下采样32倍,1280/32/2=20 > 16(除以2是因为ltrb是一半的宽高),超过了DFL的reg_max范围。 同理,输入图像小于512 x 512,那下采样32倍后,特征图尺度就小于16,Reg_max就需要设定一个更小的值。 个人理解:检测大图大目标/小图小目标时,要调整Reg_max。 个人理解:DFL通过将回归问题改造为分类问题,一方面提升了模型对复杂情况的预测能力;另一方面,在结合了Anchor-Free的思想后,通过ltrb的形式,拓展了单个特征图单元的表达能力,提升了预测框输出的利用率。 二. Anchor-Based、Anchor-Free概念:在目标定位任务里,由于目标的大小、尺寸都是不固定的,因此需要另一个框来预测目标的大概形状。 深度学习中常见的方法是:将整个图分为多个区域,依次判断各个区域有无目标、目标大小、目标尺寸等。 这些多个小区域被称为Anchor——即锚框,用以锚定实际的预测框。 根据训练集中所有标签的形状,计算(聚类)出基础的“覆盖面最广的多类框形状”,并令网络输出"偏移量"offset微调框尺寸,以更好预测形状。 v5中Anchor-Based的使用方式为one_stage——在网络的多尺度上展开anchor boxes,以直接预测物体的类别和 anchor box偏移量。 v5中目标的反算为:特征图数据 * 预设锚框参数的宽高 = 目标的位置(并不是直接预测目标的位置)。 其中特征图数据则包含了中心点偏移量、宽高偏移量等数据。 在V5中,反算得到的预测框有:(52×52 + 26×26 + 13×13) × 3 = 10647个。 个人理解:显然,由于Anchor-Based对框形状的预先定义,使其在确定的数据环境中有极好的表现,在学术研究或固定环境检测中有较好的发挥。而也因为这点,在面对复杂环境时,Anchor-Based对物体的表达能力会较为吃力。 2. Anchor-Free Anchor-Based的局限性①Anchor的设置需要手动去设计(长宽比,尺度大小,anchor的数量),对不同数据集也需要不同的设计,相当麻烦。 ②Anchor的匹配机制使得极端尺度(特别大/小的object)被匹配到的频率,相对于大小适中的object被匹配到的频率更低,网络在学习时不容易学习这些极端样本。 ③Anchor的庞大数量使得存在严重的不平衡问题,涉及到采样、聚类的过程。但聚类的表达能力在复杂情况下是有限的 ④Anchor-Based为了兼顾多尺度下的预测能力,推理得到的预测框也相对较多,在输出处理时的nms计算也会更加耗时。 原理训练中直接学习各种框形状。推理时不依靠聚类,而是根据学习到的边框距离/关键点位置,拟合物体尺寸。 v8中使用的方法是:Center-based methods——基于中心点的方法。先找中心/中心区域,再预测中心到四条边的距离。 v8中目标的反算为:在特征图每个grid(特征图中的单个框)上,预测框四条边与grid中心点的偏移值 (“左上右下”相对于中心点的距离)。 其中四条边偏移量将通过直接将16个格子进行积分(离散变量为求和,也就是期望),再乘以下采样倍数来得到。 在V8中,反算得到的预测框有:(80x80 + 40x40 + 20x20) = 8400个。 注:v8默认的最大下采样倍数为32。 个人理解:Anchor-Free通过不依赖数据集中的先验知识,使网络对“物体形状”有更好的表达能力,更具泛化潜能。在运动物体、尺寸不一物体检测上有所提升,同时检测被遮挡物体时也能更加灵活。 三. 样本分配策略概念:在目标定位任务里,由于在图片中,有目标的区域总是少量的, |
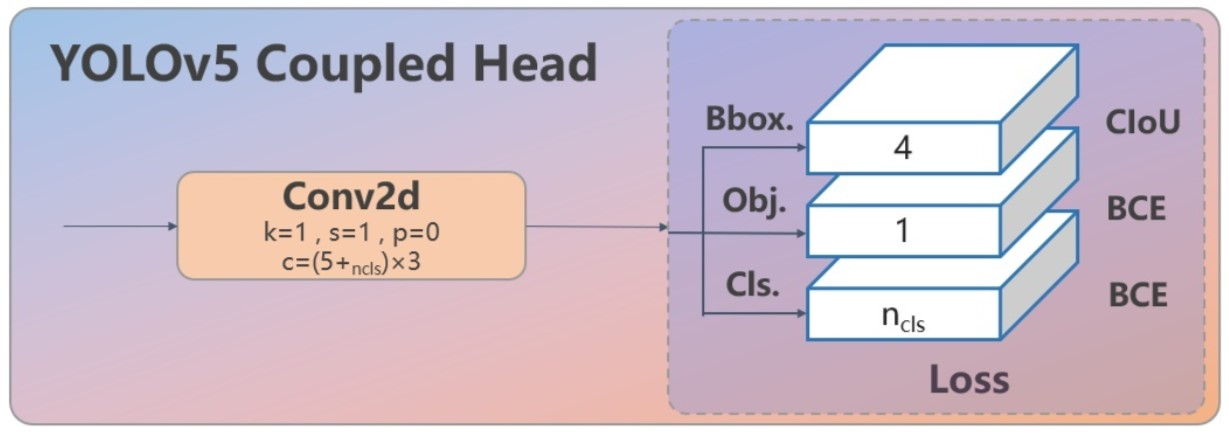
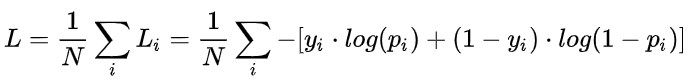 v5中,由于有对象损失的存在,在反算时只对BCE分类输出的“置信度分数”做取最大值,得到置信度最大的类别,后直接输出。 v8中,由于去掉了对象损失,在输出中也去掉了“对象置信度”,直接输出各个类别的“置信度分数”,再对其求最大值,将其作为此anchor框的“置信度”。
v5中,由于有对象损失的存在,在反算时只对BCE分类输出的“置信度分数”做取最大值,得到置信度最大的类别,后直接输出。 v8中,由于去掉了对象损失,在输出中也去掉了“对象置信度”,直接输出各个类别的“置信度分数”,再对其求最大值,将其作为此anchor框的“置信度”。 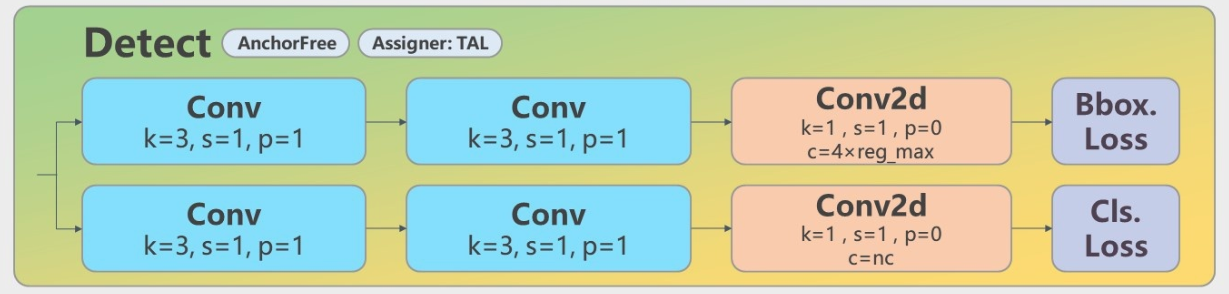
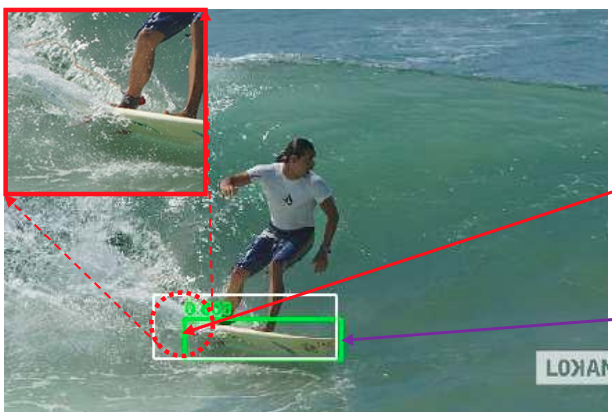

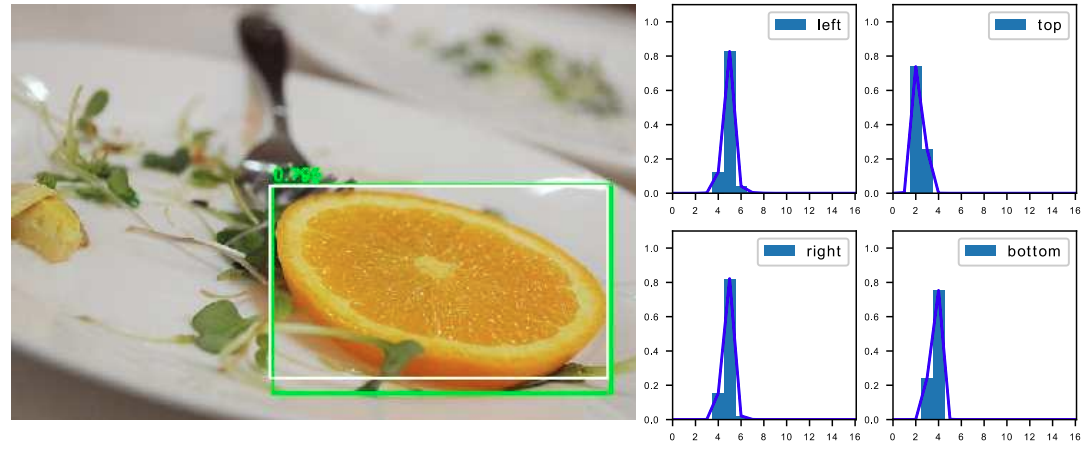

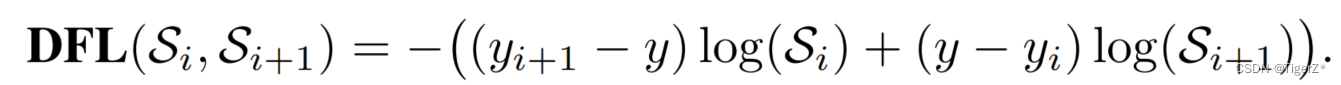 将标签转换为DFL形式的具体过程为: ①将标签值xywh转换为ltrb ②计算ltrb四个值,转换为DFL所需的积分形式(即预测值 + 临近预测值) 具体转换过程为:y = 中心距某条边的距离 / 当前的下采样倍数 例如: 目标中心点距上边73 px,在最大下采样32倍的特征图中,计算其在DFL中的映射值为73 / 32 = 2.3。 取整后得预测值yi = 2, 临近预测值yi+1 = 3 根据映射值与预测值、临近预测值的接近程度,计算各自的权重为 2.3 - 2 = 0.3, 3 - 2.3 = 0.7
将标签转换为DFL形式的具体过程为: ①将标签值xywh转换为ltrb ②计算ltrb四个值,转换为DFL所需的积分形式(即预测值 + 临近预测值) 具体转换过程为:y = 中心距某条边的距离 / 当前的下采样倍数 例如: 目标中心点距上边73 px,在最大下采样32倍的特征图中,计算其在DFL中的映射值为73 / 32 = 2.3。 取整后得预测值yi = 2, 临近预测值yi+1 = 3 根据映射值与预测值、临近预测值的接近程度,计算各自的权重为 2.3 - 2 = 0.3, 3 - 2.3 = 0.7 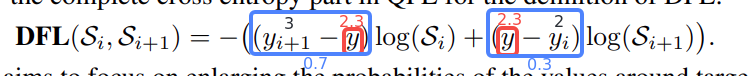 根据上述计算,其在DFL中的表达即为
根据上述计算,其在DFL中的表达即为 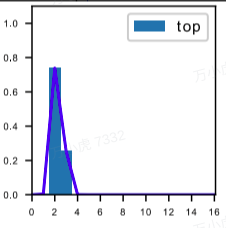 在实际训练中,DFL将与CIOU损失结合使用。 在第一部分,通过DFL对“边界框分布概率”和标签的“分布概率”进行损失计算,从而对每条边进行优化。 在第二部分,将“边界框分布概率”还原为预测框,通过CIOU损失对预测框和标签的“实际框”进行损失计算,从而对预测框整体进行优化。
在实际训练中,DFL将与CIOU损失结合使用。 在第一部分,通过DFL对“边界框分布概率”和标签的“分布概率”进行损失计算,从而对每条边进行优化。 在第二部分,将“边界框分布概率”还原为预测框,通过CIOU损失对预测框和标签的“实际框”进行损失计算,从而对预测框整体进行优化。 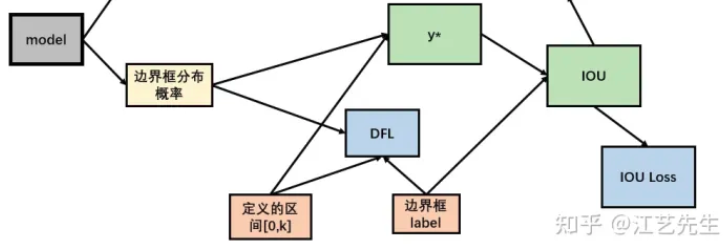




【本文地址】